By: Koen Verbeeck | Comments | Related: More > DBA Best Practices
Problem
A webinar about SQL Server Development best practices was hosted on MSSQLTips.com. In this webcast, several tips and tricks were shared which could save a lot of time and headaches when writing T-SQL code. You can view the webcast on-demand here. At the end, there was room for questions, but since not every question could be answered in the allotted time frame, we will tackle them in this tip.
Solution
Q: One of the causes of performance issues is blocking in database...how can we minimize it apart of tuning indexes and queries?
A certain amount of locking and blocking is unavoidable in SQL Server. However, if a query is blocking other queries from accessing a table, it can quickly become problematic. There are a couple of actions you can take:
Make your queries as short and efficient as possible. You can optimize the query itself (maybe by switching to a set-based SQL statement by using a tally table, as shown in the webinar) or by tuning the indexes as mentioned in the question. But after you made queries as fast as possible, you have to take transactions into account. If you have very long running transactions, chances are higher they will be blocking other queries. It’s not the best idea to put a BEGIN TRAN at the very beginning of a very long stored procedure and a COMMIT at the end. You can for example put transactions around just the update/insert/delete statements. If you have long running batch statements, such as a DELETE statement, you can try to minimize locking by splitting it up into smaller batches. Suppose you try to delete all rows below a certain date:
DELETE FROM MyTable WHERE MyDate < '2019-01-01';
You can delete rows per month or use a WHILE loop to delete 1000 rows at a time. Or you can use SET ROWCOUNT to process only a specified number of rows:
SET ROWCOUNT 500 delete_more: DELETE FROM MyTable WHERE LogDate < '2019-01-01'; IF @@ROWCOUNT > 0 GOTO delete_more SET ROWCOUNT 0
You can find more info about SET ROWCOUNT in the tip How To Use @@ROWCOUNT In SQL Server.
- Using in-memory OLTP tables reduces the amount of locking drastically. Keep in mind this solution might not be suited for your specific scenario since there are some prerequisites.
- You can use the NOLOCK query hint when using a SELECT query. With this hint, you can read data from a table even when it is locked. However, it is strongly discouraged to use this hint everywhere, as it can lead to inconsistent results. Suppose for example you’ve read data from a table which was just changed by an UPDATE statement. However, after reading the data, the UPDATE statement rolled back. Now you have data that doesn’t exist anymore in the table.
- You can switch to the read committed snapshot isolation level. You get higher concurrency and less blocking, but there is additional overhead as well. You can find a good overview in the article The unwanted Side Effects of enabling Read Committed Snapshot Isolation.
- The best solution to avoid blocking for SELECT queries is to read from a database that isn’t locked. You can for example use readable secondaries of an Always On availability group, a log shipped database, a replicated database or a mirrored database with snapshot. Or you can create a business intelligence solution where the data is copied to a data warehouse.
If you want to learn more about locking and blocking, check out this overview. And here are some free resources.
Q: How would you efficiently convert EPOCH (Unix time) time formats into say yyyy-mm-dd for one column?
The definition of EPOCH time or UNIX time from Wikipedia is "the number of seconds that have elapsed since 00:00:00 Thursday, 1 January 1970, UTC minus leap seconds". This means the easiest solution is the following:
SELECT DATEADD(SECOND, [my_unixtime], '1970-01-01')
FROM [MyTable];
However, you might want to make some adjustments if you want to take your local time zone into account. Keep in mind the second parameter of DATEADD is an integer, which means the highest datetime we can get in SQL Server is the following:
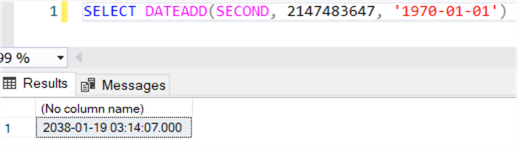
This is also known as the Year 2038 problem. If you need dates further in the future, you can first divide the EPOCH number by 86400 to get the number of days, add that to 1970-01-01 and then add the remainder of seconds to get the exact time.
Q: What is your experience with Cardinality Estimation in regards to execution plans?
To be honest, my personal experience is very limited since I’ve never had any real issues with the new cardinality estimator (which was introduced with SQL Server 2014). If you’re interested in learning more, here are some resources:
- The official documentation
- Checking SQL Server Query Cardinality Estimator Version
- Should You Use the New Compatibility Modes and Cardinality Estimator?
Q: I work in data warehouse projects, and there has been some discussion about how to best load data.
To further clarify the question, once some of my co-workers told me that is a bad practice to use the following to load data:
- (1) DELETE period-of-time-N
- (2) INSERT period-of-time-N technic for fact tables
and I should do this instead:
- (1) COPY everything-but-period-of-time-N in a text file
- (2) TRUNCATE TABLE
- (3) INSERT everything-but-period-of-time-N from the text file
- (4) INSERT period-of-time-N.
What is your take on this?
To clarify the question, there are three possible scenarios for loading the current period of data into a fact table:
- First option:
- Delete all of the currently existing data of the current period (which is most likely not up to date) from the fact table, if any.
- Insert the data for the current period.
- Second option:
- Copy all data of the fact table except the current period into another table or flat file.
- Truncate the fact table (which is fast).
- Insert the data back.
- Insert the data for the current period
- Third option:
- Copy all data of the fact table except the current period into another table.
- Delete the original table.
- Rename the new table to the original table name.
- Insert the new period.
In my opinion, the second option is most likely not a good candidate as it involves copying the largest part of the fact table too many times. The first option seems straight forward, but in very large fact tables deleting data might not be efficient. The third option gives a work around by not deleting data, but again involves shuffling a lot of data around. Unfortunately, it’s not possible to determine which option is always best. As usual, it depends:
- What are the indexes on the table?
- Is there a columnstore index?
- How much data is in the fact table?
- How much data does the current period hold?
- …
The delete of the first option can be sped up by using an index that contains the period column as the first column. This can be a clustered or non-clustered index. However, if other indexes are present, those need to be maintained as well.
If there’s a clustered columnstore index, deletes are to be avoided. But, copying all data to another table and creating a new clustered columnstore index is resource consuming as well.
Some databases systems, like Snowflake or document databases, might prefer option 3 for very large tables because of the way the data is structured internally. In Snowflake, there are no indexes that can help you speeding up a delete, but copying data to another table is really fast.
For SQL Server though, there might be another alternative: partition switching. You can partition your table on period. Stage the data for the current period in a staging table which has the same schema as the fact table and then you can simply switch the partitions, which is very fast. The downside is that partitioning is Enterprise-only before SQL Server 2016 SP1. If you have SQL Server 2016 SP1 or a more recent version of SQL Server, you can use the feature in all editions. An example of partitioning can be found in the tip Implementation of Sliding Window Partitioning in SQL Server to Purge Data.
Next Steps
- If you haven’t already, you can view the recording of the webcast here.
- There are many other webcasts available, on a variety of topics. You can find an overview here.
- There are more questions covered in part 2, so stay tuned!






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
