By: Koen Verbeeck | Comments (2) | Related: > TSQL
Problem
T-SQL is a formidable procedural language for Microsoft SQL Server derived from ANSI SQL (structured query language). With just basic DML (Data Manipulation Language) syntax – UPDATE, DELETE, INSERT, SELECT – you can already do a great deal of database programming with scripts or stored procedures. In this tip we'll go a little bit farther than the basics and show you some valuable SQL statements used in Microsoft's relational database management systems. Little pieces of T-SQL syntax that might take you to the next level.
Solution
Common Table Expressions Transact-SQL Tricks
Sometimes you have to reuse a result set in T-SQL, for example because expressions are becoming complex or you want to reference the result of an expression in multiple columns. The easiest option is to write a subquery:
SELECT
TestPlus = tmp.Test1 + tmp.Test2
,TestMinus = tmp.Test1 – tmp.Test2
FROM
(
SELECT
Test1 = SUM(myColumn)
,Test2 = AVG(myColumn)
FROM myTable
GROUP BY myColumn
) tmp;
In the query above, the query between brackets is the subquery or the inner query. It has the alias tmp. The outer query selects from the inner query and can thus reference the columns from the inner query. However, if you have a long, complicated query with many intermediary calculations, nesting subqueries can make the query hard to read.
A solution is to use common table expressions, commonly abbreviated as CTEs. A CTE is another way of writing a subquery. The previous query rewritten to use a CTE looks like this:
WITH CTE_TMP AS
(
SELECT
Test1 = SUM(myColumn)
,Test2 = AVG(myColumn)
FROM myTable
GROUP BY myColumn2
)
SELECT
TestPlus = tmp.Test1 + tmp.Test2
,TestMinus = tmp.Test1 – tmp.Test2
FROM CTE_TMP tmp;
With a CTE, the subquery comes first, then the outer query. This makes the query more readable, especially if you have many subqueries. Take for example the query featured in the tip Adding Custom Reports to SQL Server Management Studio (which is about 1.5 pages long). With ordinary subqueries, it would be much harder to read and understand the query.
Some interesting facts about CTEs:
- If there are statements before the WITH clause of the CTE, they must be terminated with a semicolon.
- CTEs are not a performance optimization. SQL Server will execute the CTE just like it would if the query used a subquery instead. If you reference a CTE multiple times, the subquery will also be executed multiple times. CTEs are merely a way of making your queries more readable. If you have many CTEs and the query has performance issues, you might want to consider splitting up the query and storing intermediary results in temp tables. In some use cases, it seems possible to reuse the output of a CTE, as outlined in this article.
- CTEs are needed for writing a recursive query. You can learn more about them in the tip Recursive Queries using Common Table Expressions (CTE) in SQL Server.
You can find more info about common table expressions in the tip SQL Server Common Table Expressions (CTE) usage and examples.
UPDATE with FROM clause Transact-SQL Tricks
It's possible to update a MS SQL Server table using the result set of a query involving other tables. Let's say for example we want to update the customer table with a column indicating the customer has made a sale in the past 3 months. Here is the SQL code with an UPDATE statement:
UPDATE c SET IsActive = 1 FROM [dbo].[DimCustomer] c JOIN [dbo].[FactInternetSales] s ON c.[CustomerKey] = s.[CustomerKey] WHERE s.[OrderDate] >= DATEADD(MONTH,-3,GETDATE());
In this query you can see we've joined DimCustomer with FactInternatSales using the customer key. We filter on the sales records made in the last 3 months in the WHERE clause. Using the resulting customer keys, we update the DimCustomer table. The trick here is that we've aliased the DimCustomer table with "c", and we reference this alias in the UPDATE clause.
An advantage of this update pattern is that you can easily test what you're going to update. Simply put a SELECT * before the FROM clause and execute the query to see the result set:

If the query becomes more complex, you might want to use a CTE for clarity. This is the same query rewritten to use a CTE:
WITH CTE_Update AS
(
SELECT DISTINCT CustomerKey
FROM [dbo].[FactInternetSales]
WHERE [OrderDate] >= DATEADD(MONTH,-3,GETDATE())
)
UPDATE c
SET IsActive = 1
FROM [dbo].[DimCustomer] c
JOIN CTE_Update u ON c.[CustomerKey] = u.[CustomerKey];
Window Functions T-SQL Statements
A subset of window functions already existed since SQL Server 2005, but a wider implementation of window functions in SQL Server 2012 really changed the way a T-SQL developer could write queries. Before SQL Server 2012, some patterns were hard to write: rolling averages, running totals, calculating the median, et cetera. Typically, it involved joining to the same table multiple times. With window functions, these types of queries are not only easier to write, but in most cases, they perform much better than their old counterparts.
Take a look at how we can calculate the median with this SELECT statement:
SELECT DISTINCT
[DepartmentName]
,MedianRate = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY [BaseRate]) OVER (PARTITION BY [DepartmentName])
FROM [dbo].[DimEmployee]
ORDER BY MedianRate DESC;
It's one single expression. Before SQL Server 2012, you had to sort all of the items. If there was an odd number of items, take the middle item, if there was an even number of items, take the average of the middle two.
Window functions should be part of the toolbox of every T-SQL developer. However, explaining the full concept of window functions would take us too far in this tip. If you want to learn more, you can start with the window functions tutorial.
Removing Duplicates T-SQL Tutorial
A common use case is removing duplicates from a table. You can have "true" duplicates, where two or more rows are exactly the same, or "logical duplicates" where two rows have the same business key but some columns might differ. The latter can for example be the consequence of a join returning more rows than expected.
Removing true duplicates on a table can be tricky, if the table doesn't have a primary key defined. Suppose for example we have the following heap table defined with two columns of the varchar data type:
CREATE TABLE dbo.DeleteTest(code VARCHAR(10), descr VARCHAR(50));
The following data is entered into the table:
INSERT INTO dbo.DeleteTest ([code], [descr]) SELECT 'A', 'First Member' UNION ALL SELECT 'B', 'Second Member' UNION ALL SELECT 'B', 'Second Member' UNION ALL SELECT 'C', 'Third Member';
By accident, a row is inserted twice. You cannot delete rows where the code equals B, because this would delete both rows. You also cannot delete it through the table editor, because this will throw an error:
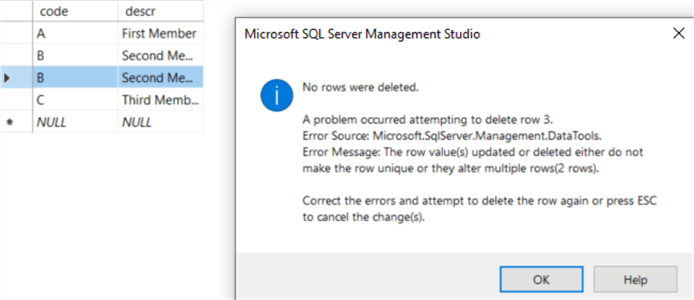
We can delete the row by using the ROW_NUMBER() window function and a common table expression:
WITH CTE_delete AS
(
SELECT rid = ROW_NUMBER() OVER(PARTITION BY code ORDER BY(SELECT NULL))
FROM [dbo].[DeleteTest]
)
DELETE FROM [CTE_delete]
WHERE rid > 1;
The trick here is that in the DELETE clause, you can also specify a CTE instead of a table name. In some cases, you can also use a view. Anyway, because the ROW_NUMBER function creates a unique number for each row (per code), SQL Server is able to delete one of the rows.
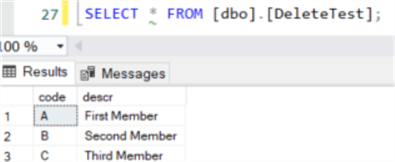
The tip Delete duplicate rows with no primary key on a SQL Server table goes deeper into this problem and proposes several alternative solutions to this problem.
The ROW_NUMBER function is useful when it comes to removing duplicate rows. You can also use it in SELECT or UPDATE statements to differentiate between rows which are unique or almost unique. Let's say for example an INNER JOIN is returning multiple rows, but we only want one specific row returned instead. In the AdventureWorks sample database, we can join the SalesOrderHeader table with the SalesOrderDetail table.
SELECT h.[SalesOrderID], d.[SalesOrderDetailID] FROM [Sales].[SalesOrderHeader] h JOIN [Sales].[SalesOrderDetail] d ON [d].[SalesOrderID] = [h].[SalesOrderID] ORDER BY 1,2;
This will return multiple records for each sales order:
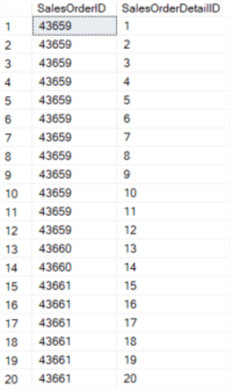
Now we only want to return the detail rows with the highest line total. If there's a tie, we take the row with the highest detail ID:
SELECT
tmp.[SalesOrderID]
,tmp.[SalesOrderDetailID]
FROM
(
SELECT
h.[SalesOrderID]
,d.[SalesOrderDetailID]
,rid = ROW_NUMBER() OVER (PARTITION BY d.[SalesOrderID] ORDER BY [d].[LineTotal] DESC, d.[SalesOrderDetailID] DESC)
FROM [Sales].[SalesOrderHeader] h
JOIN [Sales].[SalesOrderDetail] d ON [d].[SalesOrderID] = [h].[SalesOrderID]
) tmp
WHERE rid = 1
ORDER BY 1;
Tally Table T-SQL Statements
Another great example of the application of window functions is the tally table, or the "numbers" table. It's a table with one column containing only sequential numbers, usually starting at one. Using the ROW_NUMBER function and common table expressions, we can quickly generate database objects such a table in the SQL language:
WITH E00(N) AS (SELECT 1 UNION ALL SELECT 1)
,E02(N) AS (SELECT 1 FROM E00 a, E00 b)
,E04(N) AS (SELECT 1 FROM E02 a, E02 b)
,E08(N) AS (SELECT 1 FROM E04 a, E04 b)
,E16(N) AS (SELECT 1 FROM E08 a, E08 b)
,E32(N) AS (SELECT 1 FROM E16 a, E16 b)
,cteTally(N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E32)
SELECT N
FROM cteTally
WHERE N <= 10000;
The tally table is useful for mimicking iterations. Or in other words: looping over data without actually looping. By using a tally table, the solution remains set-based functionality. Solutions using row-based patterns (such as loops or cursors) don't tend to scale well in SQL Server.
We can use a tally table for example to return all dates between a given start and end date (which in traditional programming languages would be written with a FOR or WHILE loop):
DECLARE @startdate DATE = '2021-01-01';
DECLARE @enddate DATE = '2021-12-31';
WITH E00(N) AS(SELECT 1 UNION ALL SELECT 1)
,E02(N) AS(SELECT 1 FROM E00 a, E00 b)
,E04(N) AS(SELECT 1 FROM E02 a, E02 b)
,E08(N) AS(SELECT 1 FROM E04 a, E04 b)
,E16(N) AS(SELECT 1 FROM E08 a, E08 b)
,E32(N) AS(SELECT 1 FROM E16 a, E16 b)
,cteTally(N) AS(SELECT ROW_NUMBER() OVER(ORDER BY(SELECT NULL)) FROM E32)
SELECT N, MyDate = DATEADD(DAY,N-1,@startdate)
FROM cteTally
WHERE N <= DATEDIFF(DAY,@startdate,@enddate);
This gives the following result set:
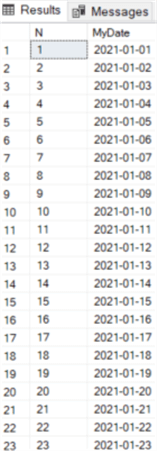
The concept of "exploding" date ranges is further explored in the tip How to Expand a Range of Dates into Rows using a SQL Server Numbers Table. More info about the concept of the numbers table can be found in the tips The SQL Server Numbers Table, Explained - Part 1 and Part 2.
Concatenating Column Values T-SQL Tricks
Stringing different values of a column together – the opposite of splitting a comma separated list – is a common requirement. For example, if we have the following column:

The following output is expected: "Koen, Bruce, Jeremy"
Since SQL Server 2017, we have the STRING_AGG function which can solve our request with a single statement.
SELECT
[DepartmentName]
,[employees] = STRING_AGG([FirstName] + ' ' + [LastName],',') WITHIN GROUP (ORDER BY [FirstName], [LastName])
FROM dbo.[DimEmployee]
GROUP BY [DepartmentName];
Before SQL Server 2017, this was a tad harder to solve. My personal favorite was the "blackbox XML method", which uses the FOR XML clause with the PATH mode. Let's illustrate with an example. In the AdventureWorks data warehouse, we're going to concatenate all the employee names for each department. The query becomes:
SELECT
[e1].[DepartmentName]
,[employees] = STUFF(
(
SELECT ',' + [e2].[FirstName] + ' ' + [e2].[LastName]
FROM [dbo].[DimEmployee] [e2]
WHERE [e2].[DepartmentName] = [e1].[DepartmentName]
ORDER BY [e2].[FirstName] + ' ' + [e2].[LastName]
FOR XML PATH(''), TYPE
).[value]('.', 'varchar(max)')
,1,1,''
)
FROM [dbo].[DimEmployee] [e1]
GROUP BY [e1].[DepartmentName];
This gives the following result:

The query uses a correlated subquery to filter the employees on the "current" department. Using XML PATH, the employee names are concatenated together. The GROUP BY clause is there to eliminate duplicates. If you would remove the GROUP BY, a row would be returned for each employee. Employees in the same department have the same result row. The STUFF function is used to remove the leading comma.
Although it looks quite weird, the XML method tends to perform quite well. In this article other alternatives to the solution are discussed.
Next Steps
- What are your favorite Transact-SQL tricks? Let us know in the comments!
- Getting started with Transact-SQL? Check out the following tutorials:






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
