By: Ron L'Esteve | Comments | Related: > Apache Spark
Problem
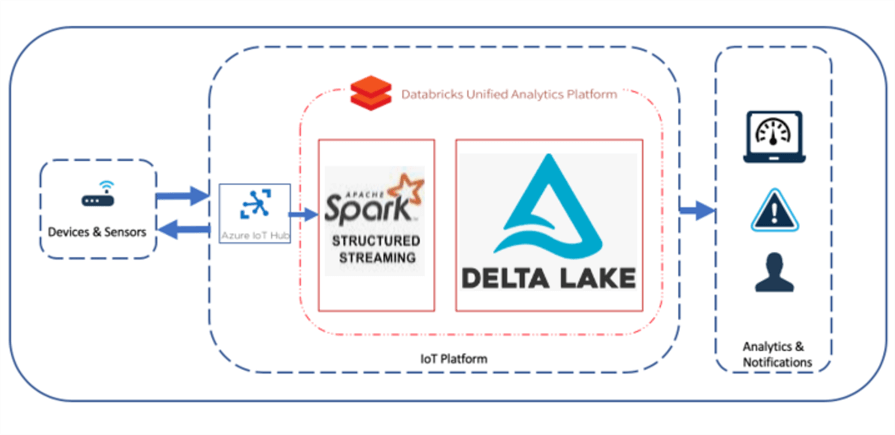
Real-time IoT analytics coupled with advanced analytics and real-time machine learning insights are all areas of interest that many organizations are eager to pursue to advance their business and goals. Apache Spark's advancing API offerings have opened many opportunities for advanced and streaming analytics for big data workloads. One such API offering from Apache Spark is centered around Structured Streaming which supports big data and real-time advanced analytics capabilities. How can we get started with real-time IoT analytics using Apache Spark's Structured Streaming offerings?
Solution
Apache Spark's structured streaming is a stream processing framework built on the Spark SQL engine. Once a computation along with the source and destination are specified, the structured streaming engine will run the query incrementally and continuously as new data is available. Structured streaming treats a stream of data as a table and continuously appends data. In this article, we will walk thorough an end-to-end demonstration of how to implement a structured streaming solution using a Device Simulator which will generate random device data that will be fed into an Azure IoT Hub and processed by Apache Spark through a Databricks Notebook and into a Delta Lake to persist the data. Additionally, we will explore how to customize structured streaming output modes (append vs. update vs. complete) and triggers in the code.
Pre-requisites
As a basis for the demo, ensure that you have read and understood my previous article, Real-Time Anomaly Detection Using Azure Stream Analytics, which discusses how to complete the following steps:
- Install and Run the IoT Device Simulator Visual Studio Solution File: This device simulator will create stream of random device data that will be fed into the IoT Hub device and used by Spark Structured Streaming.
- Create and Configure an IoT Hub Device: This service will bridge the divide between the Device Simulator and the Spark Structured Streaming service.
- Additionally, the Databricks service will need to be created in Azure Portal. Read Getting Started with Databricks for more information on this setup process. Databricks' Spark compute clusters will be used for the Structured Streaming process. Alternatively, Synapse Analytics could also be used for this process.
Create an IoT Hub
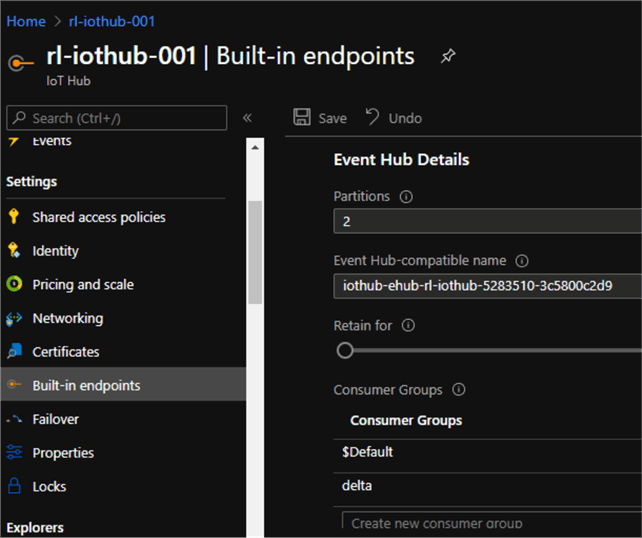
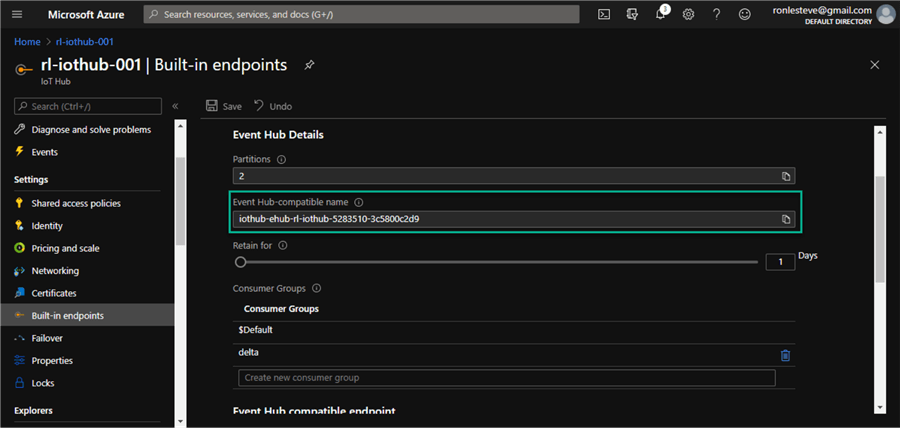
Once an IoT Hub has been created along with an IoT Device being added to the hub, a new consumer group would need to be added to the Built-in endpoints section of the IoT Hub. Consumer Groups are used by applications to pull data from the IoT Hub, hence having a recognizable alias will be useful when we write the Structured Streaming code.
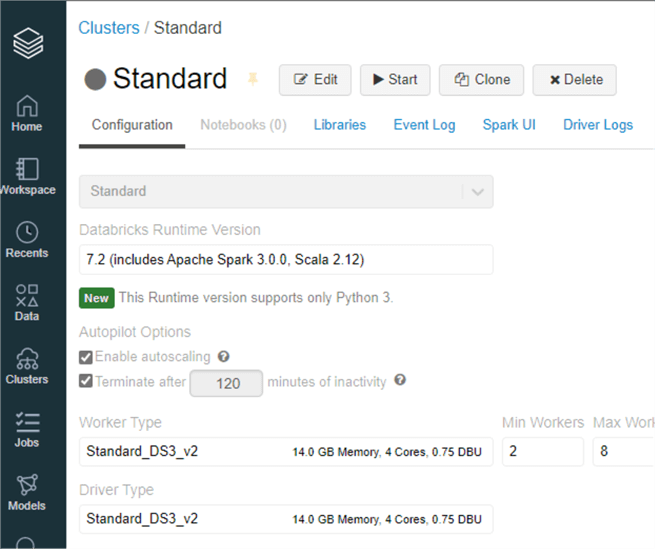
Create a Databricks Cluster
Next, a Databricks cluster will need to be created. For the purposes of this demo we have a Standard Cluster with the following configurations.
Install Maven Library
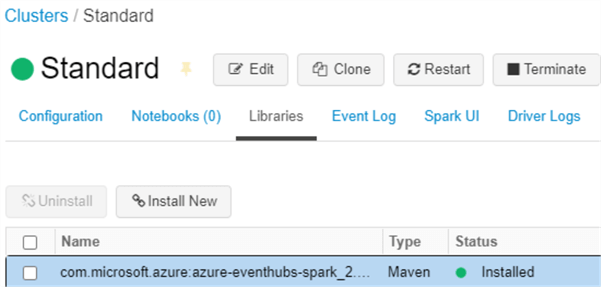
There is one more setup and configuration step before we can begin writing structured streaming code in the Databricks Notebook. We'll need to install a Maven library with the following coordinates: com.microsoft.azure:azure-eventhubs-spark_2.12:2.3.15.
Please note that these coordinates were obtained from the following MvnRepository, hence it would be important to select the correct version of the coordinates based on your respective configuration versions.
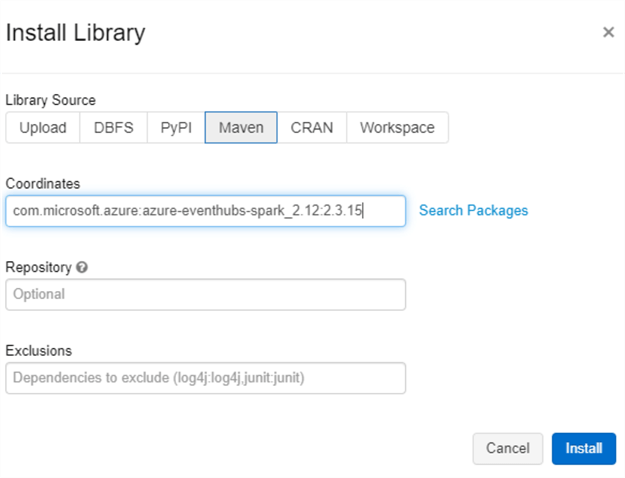
Once the selected Maven library is installed on the cluster, it will display a status of 'Installed'. Remember to re-start the cluster for the library to be properly installed on the cluster.
Create a Notebook & Run Structured Streaming Queries
Configure Notebook Connections
Now we are ready to create a new Databricks notebook and attach the Standard Cluster with the Maven library installed to it. Additionally, we will be using Scala for this notebook.
We will start by running the following code, which will 1) build a connection string using the IoT Hub connection details and 2) Start the structured stream. We'll need to replace the IoT Hub connections below before running the code. Also, remember to verify the consumer group in the code based on what was defined in the IoT Hub in Azure Portal.
import org.apache.spark.eventhubs._ import org.apache.spark.eventhubs.{ ConnectionStringBuilder, EventHubsConf, EventPosition } import org.apache.spark.sql.functions.{ explode, split } // To connect to an Event Hub, EntityPath is required as part of the connection string. // Here, we assume that the connection string from the Azure portal does not have the EntityPath part. val connectionString = ConnectionStringBuilder("—Event Hub Compatible Endpoint--") .setEventHubName("—Event Hub Compatible Name--") .build val eventHubsConf = EventHubsConf(connectionString) .setStartingPosition(EventPosition.fromEndOfStream) .setConsumerGroup("delta") val eventhubs = spark.readStream .format("eventhubs") .options(eventHubsConf.toMap) .load()
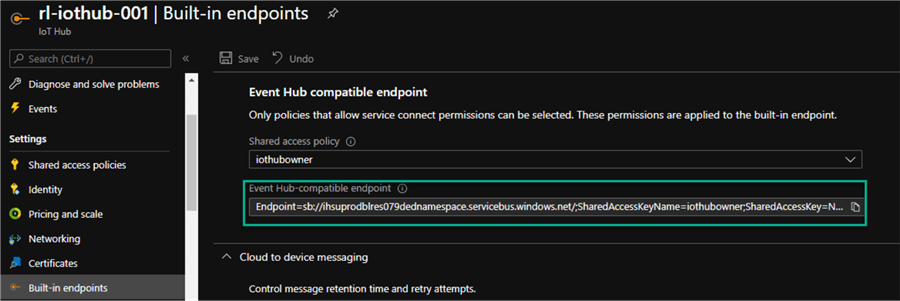
The following details will need to be entered in the code and can be found in the built-in endpoints section of the IoT Hub from Azure Portal.
Start the Structured Stream
The second section of this code will take the defined connections and read the stream. The results below indicate that the stream has been read successfully.
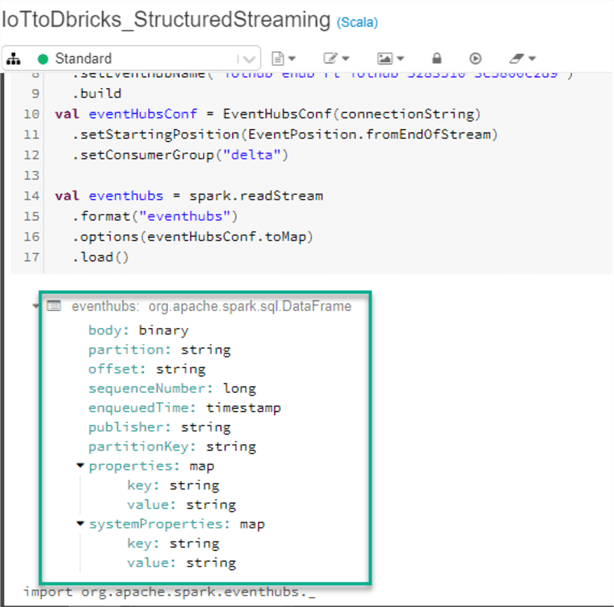
Next, we can run the following code to display stream details.
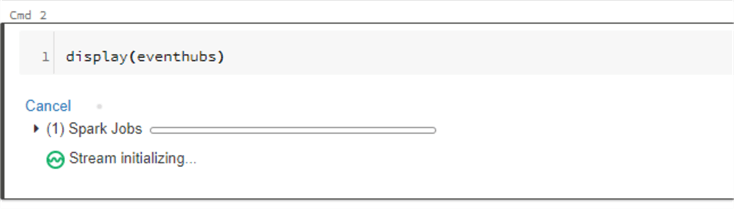
display(eventhubs)
As we can see, the steam is initializing.
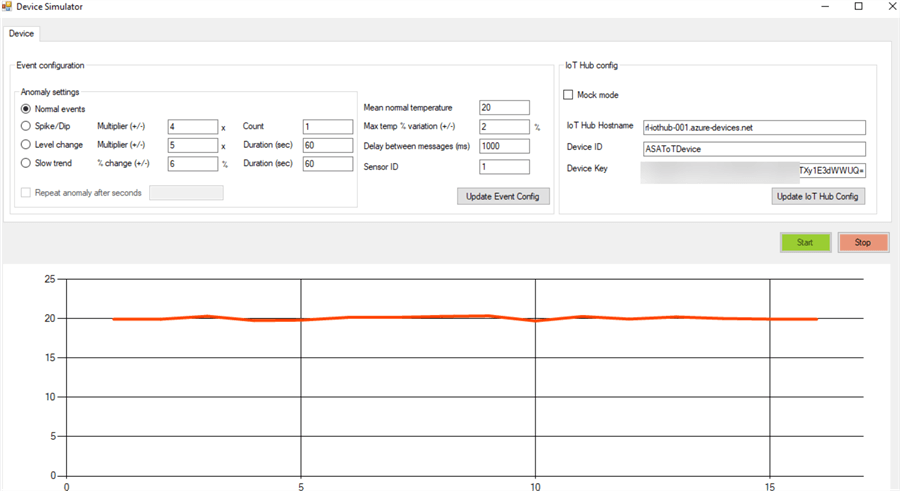
Start the IoT Device Simulator
Next, lets head over to our device simulator and ended the IoT Hub device details related to Hub Namespace, Device ID and Device Key and run the device simulator. The red line below indicates that the device simulator is running.
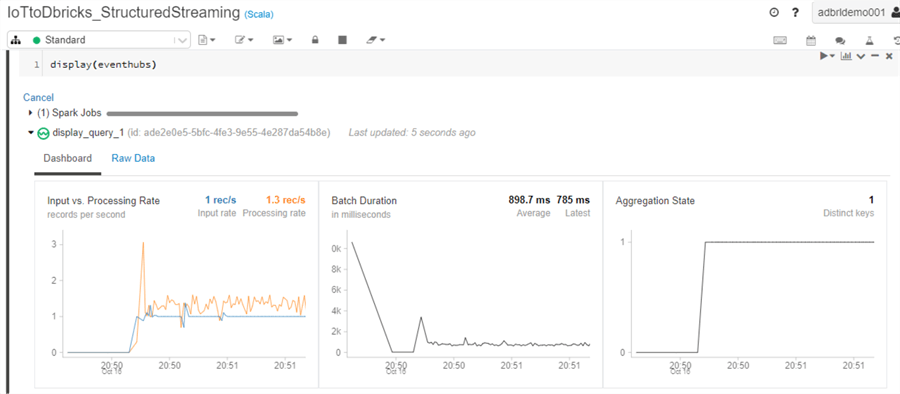
Display the Real-Time Streaming Data
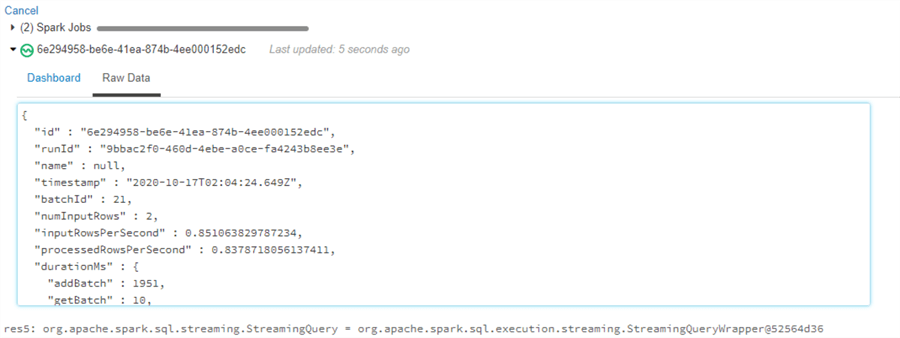
Now when we navigate back to the Databricks notebook and expand the Dashboard section of the display(eventhubs) code block, we can see the processing metrics for the stream related to input vs processing rate, batch duration and aggregation state.
When we navigate to the raw data tab, we can see the structure and data of the stream.
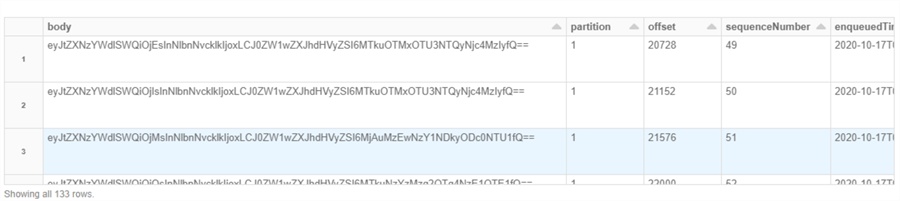
Create a Spark SQL Table
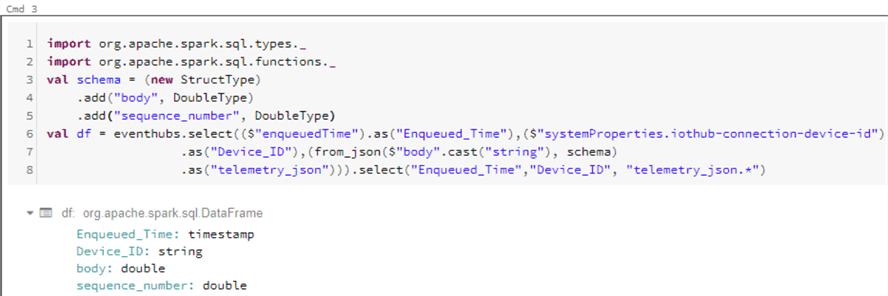
Now that we know that we have incoming data, we can create a Spark SQL Table by running the following code. Remember to define the columns based on your IoT Device data. For this demo, we are using columns 'body' and 'sequenceNumber' from the device simulator.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
val schema = (new StructType)
.add("body", DoubleType)
.add("sequence_number", DoubleType)
val df = eventhubs.select(($"enqueuedTime").as("Enqueued_Time"),($"systemProperties.iothub-connection-device-id")
.as("Device_ID"),(from_json($"body".cast("string"), schema)
.as("telemetry_json"))).select("Enqueued_Time","Device_ID", "telemetry_json.*")
The expected output will display the results of the spark.sqlDataFrame.
Next, we can go ahead and create the Spark SQL table.
df.createOrReplaceTempView("device_telemetry_data")

Write the Stream to a Delta Table
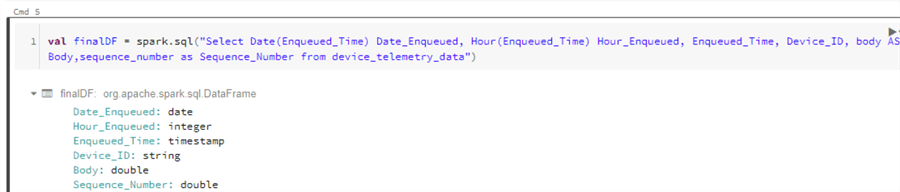
Now its time to write the stream to a Delta Table. We'll start by running the following code to define the final Dataframe.
val finalDF = spark.sql("Select Date(Enqueued_Time) Date_Enqueued, Hour(Enqueued_Time) Hour_Enqueued, Enqueued_Time, Device_ID, body AS Body,sequence_number as Sequence_Number from device_telemetry_data")
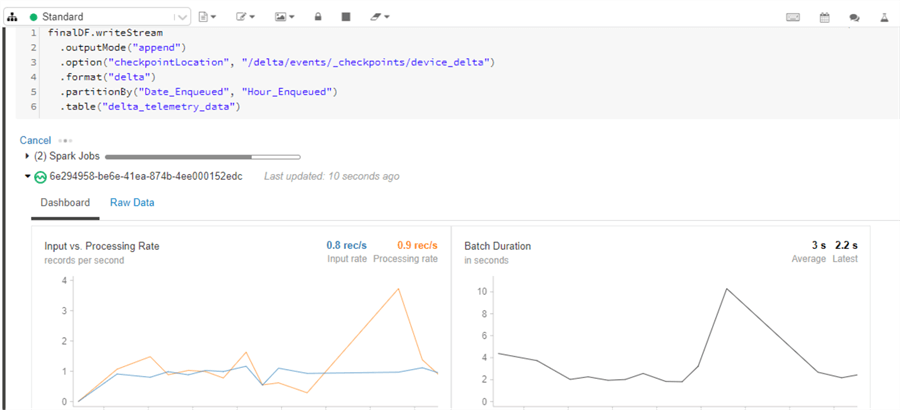
This next block of code will write the stream to the delta table. Notice that we can define the partitions, format, checkpoint location and output mode.
We are using a default checkpoint location defined and managed by Databricks, but we could just as easily define this location ourselves and persist the data to a different folder.
Note that the output mode is set to append. The following output modes are supported:
- Append (only add new records to the output sink)
- Update (update changed records in place)
- Complete (rewrite the full output)
finalDF.writeStream
.outputMode("append")
.option("checkpointLocation", "/delta/events/_checkpoints/device_delta")
.format("delta")
.partitionBy("Date_Enqueued", "Hour_Enqueued")
.table("delta_telemetry_data")
Optionally, triggers can also be added to the write stream define the timing of streaming data processing, whether the query is going to executed as micro-batch query with a fixed batch interval or as a continuous processing query.
Here are a few examples of triggers. For more information see, Apache Spark Triggers.
.trigger(Trigger.ProcessingTime("2 seconds")) .trigger(Trigger.Once()) .trigger(Trigger.Continuous("1 second"))
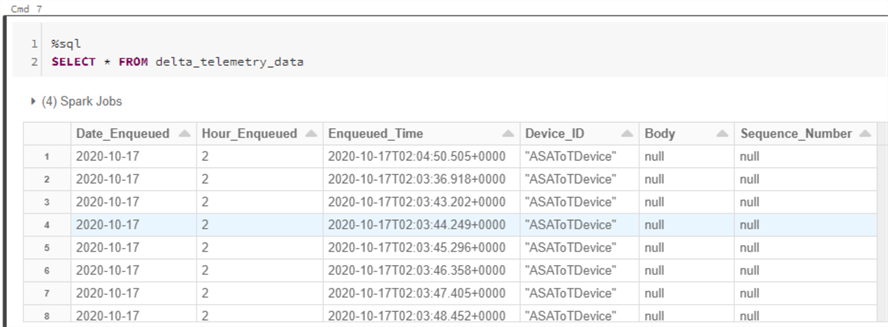
As we can see from the raw data tab, device data is continuously streaming in and we able to view the sample streaming data along with its structure.
Finally, we can write a bit of sql to query the delta table that the structured streaming data is writing into. We can then use this table to perform additional advanced analytics and/or build machine learning models to gain further valuable real-time insights into the IoT Device data.
%sql SELECT * FROM delta_telemetry_data
Next Steps
- Explore the Microsoft Structured Streaming Tutorial.
- Read the Apache Spark Structured Streaming Programming Guide.
- Explore Databricks' Structured Streaming documentation.
- Read more about Best practices for developing streaming applications.
- Read Part V, Streaming Page 331-393 of Spark-The Definitive Guide to Big Data Processing Made Simple






About the author
 Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tec
Ron L'Esteve is a trusted information technology thought leader and professional Author residing in Illinois. He brings over 20 years of IT experience and is well-known for his impactful books and article publications on Data & AI Architecture, Engineering, and Cloud Leadership. Ron completed his Master’s in Business Administration and Finance from Loyola University in Chicago. Ron brings deep tecThis author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
