By: Eric Blinn | Updated: 2021-08-10 | Comments | Related: > Indexing
Problem
I have a SQL Server query that asked for a new nonclustered index to be created, but after I created the index, the query performance did not improve. Is there a better optimization solution for my Microsoft SQL Server database? Would a filtered index help or do I need to tune the stored procedure?
Solution
Filtered indexes are a type of non-clustered index that have a very specific use case when indexing a table. This tip will cover filtered indexes in detail. It will explain how to create a filtered index, how to use them, and what the use cases are for them as a point of reference for SQL Server DBAs and Developers.
All of the demos in this tutorial will use the WideWorldImporters sample database which can be downloaded for free from Github.
SQL Server Filtered Index Overview
Most SQL Server indexes contain a subset of columns, but include all the rows of a table. The statement below creates a single-column, non-clustered index that includes every row of the target table.
CREATE NONCLUSTERED INDEX DC ON Warehouse.StockItemTransactions(StockItemID);
Filtered indexes are just like regular, non-clustered SQL Server indexes except that they only contain a subset of rows from the table rather than all of the rows, which makes the index size smaller. This can have a very positive impact on certain SQL queries.
How to create a SQL Server Filtered Index
Filtered indexes are made in the exact same way as regular non-clustered indexes but include a WHERE clause at the end. These WHERE clauses are extremely similar to those attached to regular SQL statements.
The T-SQL syntax below creates a new index much like the example above except that it will only contain rows where the TransactionTypeID column value for the row is equal to 12. Run the following code in SQL Server Management Studio (SSMS):
CREATE INDEX DC12 ON Warehouse.StockItemTransactions(StockItemID) WHERE TransactionTypeID = 12;
Due to the smaller row count, this index will be physically smaller on disk, likely have less of a write penalty associated with it, be easier upon which to perform maintenance, be faster to scan, and have more specific statistical metadata than the index above.
There are limits about what can be put into the WHERE clause when compared to a SQL WHERE clause. This is a list of things that cannot be placed in the where clause of a filtered index.
- LIKE, BETWEEN, or NOT IN operators
- CASE Statements
- Dynamic date ranges using GETDATE() or similar calculations
How to use a SQL Server Filtered Index
The query optimizer will only use a filtered index if the query being executed is certain to be able to use that same filtered index in every possible scenario. This means that if there is a variable in a query that is set to a value that would hit a valid filtered index condition, the optimizer will not use the filtered index because it can't be certain that the next time that same query is called it will have the same valid value for the variable. The optimizer will, instead, choose the next best plan that can be universally applied to all possible values of the variable.
This example will explain further.
DECLARE @TransactionTypeID INT = 12; DECLARE @StockItemID INT = 160; SELECT StockItemID FROM Warehouse.StockItemTransactions WHERE TransactionTypeID = @TransactionTypeID AND StockItemID = @StockItemID;
This query looks like it should be able to use the filtered index that was created above. The TransactionTypeID is 12 which was added to the filter condition on the index and the StockItemID is the column that was sorted on the index. However, the optimizer cannot choose a plan using the filtered index because the same exact query may be run again later with a value other than 12 for TransactionTypeID – rendering the filtered index useless. Instead, the optimizer creates a full table scan for this query based on the execution plan below.
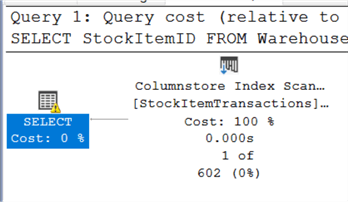
There are 2 ways around this problem – each with their own pros and cons.
The first option is to force the query to recompile for every execution.
DECLARE @TransactionTypeID INT = 12; DECLARE @StockItemID INT = 160; SELECT StockItemID FROM Warehouse.StockItemTransactions WHERE TransactionTypeID = @TransactionTypeID AND StockItemID = @StockItemID OPTION(RECOMPILE);
By adding the OPTION (RECOMPILE) to the end of the query, the optimizer knows that it will be allowed to compile a new plan upon every execution and does not need to accept a next-best plan to account for future variants in variable values. Because of that it will use the DC12 index created above.
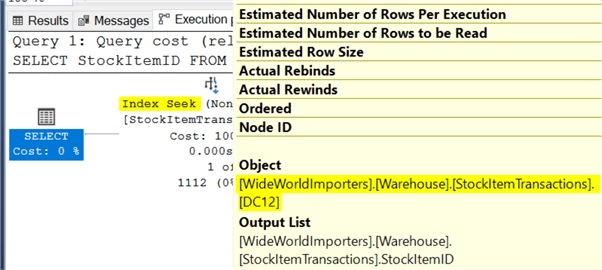
The main "pro" to this approach is that it is easy to implement. There is a huge downside in that it can be very detrimental to overall system performance if the query is hard to compile or runs often. Only consider this approach for queries that won't run often, like on-demand reports.
The second option is to hard code a match value for the filtered index predicate rather than use a variable. This can be accomplished by inserting the value directly into the query or by converting a variable value into a hard coded value using dynamic SQL. Examples of both to are below.
This query will use the filtered index because the value 12 is hard coded into the query and the optimizer no longer needs to consider alternate values.
DECLARE @StockItemID INT = 160; SELECT StockItemID FROM Warehouse.StockItemTransactions WHERE TransactionTypeID = 12 AND StockItemID = @StockItemID;
This query will also use the filtered index because the value 12 is hard coded in the final query.
DECLARE @TransactionTypeID INT = 12; DECLARE @StockItemID INT = 160; DECLARE @SQL NVARCHAR(4000); SET @SQL = ' SELECT StockItemID FROM Warehouse.StockItemTransactions WHERE TransactionTypeID = ' + CAST(@TransactionTypeID AS nvarchar(11)) + ' AND StockItemID = @StockItemID;'; EXEC sp_executeSQL@SQL, N'@StockItemID INT', @StockItemID = @StockItemID;
The pro to this option is that plans that are generated can be saved and reused, saving CPU time related to compilation. This can also be a con. Since a separate plan can be saved for every conceivable value for TransactionTypeID the plan cache might bloat with an excess of similar query plans. In this example the database only has 3 possible values for the TransactionTypeID so that likely won't become an issue.
One other con is that any time a query uses dynamic SQL – especially with user input – there is the risk of SQL injection. Take extra care to protect any code from such attacks.
Use cases for a SQL Server Filtered Index
Due to the coding limitations shown above there are limits to the use cases of filtered indexes.
Filtered indexes are most useful in performance tuning scenarios where SQL queries will use a column with low cardinality. The TransactionTypeID above had only 3 unique values so filtering an index on that column makes sense as a regular index with all rows may struggle to provide a performance improvement with so few input values. Also, since there are so few possible values the issues related to the plan cache bloat don't tend to be as problematic.
The next use case for a filtered index is when there is a commonly searched column that contains many NULL values. In this case create a filtered index that both sorts on this column and excludes the rows with a NULL value on the column. This creates a much smaller index that will be very easy to use in code. Any argument that compares that column to any non-null value will use the filtered index. In this use case there is no need to force recompiles or hard code a value!
Another scenario that may make sense to use a filtered index is a scenario where there is an extremely common argument used across many queries. One example might be a "Critical Orders Dashboard" where a whole host of queries each execute with a common argument such as "OrderSeverity=99". Since all the queries are looking for the exact same OrderSeverity it wouldn't be problematic to hard code that value in the SQL code. Making a series of filtered indexes that sort by customer, date, or region and each filtered on OrderSeverity=99 would make that dashboard load pretty quickly. Also, since one would expect that only a small percentage of orders have that highest severity these indexes would likely be very small in comparison to a regular non-clustered index.
Final Thoughts
The use case for a filtered index isn't very big, but the performance gain one can get by using them properly can be extremely big. Now that you know what to look for, see if you can find an opportunity to use one in your environment!
Next Steps
- Protect yourself from SQL injection
- Comparing filtered indexes to filtered views
- A deep dive on how the optimizer chooses filtered indexes






About the author
 Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.
Eric Blinn is the Sr. Data Architect for Squire Patton Boggs. He is also a SQL author and PASS Local Group leader.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2021-08-10
