By: Koen Verbeeck | Updated: 2023-04-04 | Comments | Related: > Database Design
Problem
I just started a job as a Business Intelligence Developer. For my first project, we're working on a data warehouse where they're using the Kimball methodology. One of the senior developers explained how star schemas work and told me to avoid snowflaking. But what is a snowflake schema exactly?
Solution
For creating data warehouses, a popular methodology is star schema modeling, also known as dimensional data modeling. Ralph Kimball described this technique in the book, The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, which is why it's often referred to as the "Kimball Method." In a star schema, a central fact table is surrounded by different dimension tables linked together by surrogate keys. You can lay this out as a star (with a little imagination), hence the name.
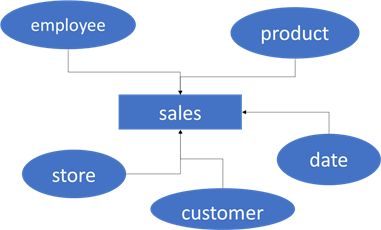
You can find more detail about the different aspects of the star schema in this tip. This is a good place to start your learning journey if you're unfamiliar with star schemas in data warehousing projects.
A snowflake schema is an expansion of the star schema. It's a more normalized version, where data redundancy is reduced, most likely for query performance reasons or ease of development. It is not to be confused with the Snowflake database, a cloud-based data warehouse solution.
The Snowflake Schema Explained
Let's use an example to illustrate how we expand the star schema pictured previously. Suppose we also need to keep track of locations along with the other dimension tables. Stores have a location and customers; we know the customer's location if they are part of the customer loyalty program, which requires people to provide their address. There are a couple of options to consider.
The first option is to add all the location info to their respective dimension. However, suppose this location changes often (more likely the customers, not the stores). This might result in rapidly growing dimensions if we track history. For more info about slowly changing dimensions, check out Implement a Slowly Changing Type 2 Dimension in SQL Server Integration Services - Part 1.
Another option is to stay "full star schema" and add two dimensions to our fact table: customer location and store location. If there are many changes to these dimensions, the customer and store dimensions stay unimpacted. From a reporting perspective, this is almost the same as the previous option.
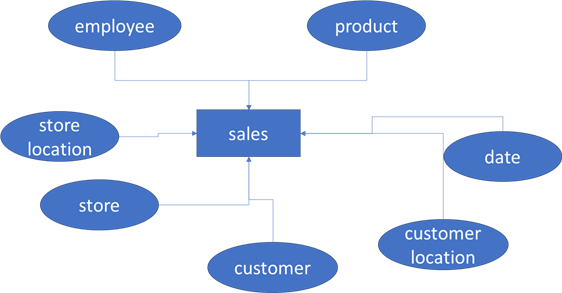
The advantage of this option is that you don't need to modify your existing dimensions and their ETL load processes. The disadvantage is that you must modify your fact table with two extra surrogate keys. What if it's a large table? Will you reload it? Or update the history for those two new columns? Or maybe ignore history and only load those two columns for new data? Interesting choices that must be considered. Another disadvantage is that you must build two location dimensions, which are basically the same. You can mitigate this by creating a single dimension, calling it location or geography, and linking the fact table twice to the same dimension. In this case, you sort of "virtualize" your dimension.
The final option is to build a snowflake schema. We build one single dimension – location or geography (mentioned before) – and link this dimension to both store and customer.
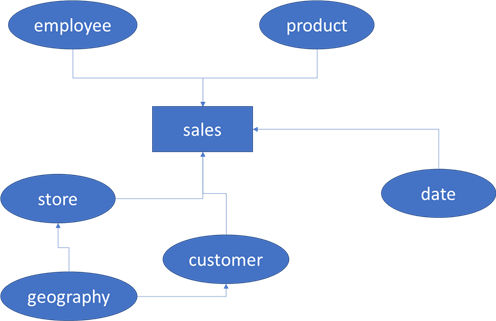
Because we now have a dimension not linked to a fact table, the schema is said to be a snowflake. Instead of looking like a star, it now resembles a snowflake because of the extra branching. The data is more normalized. If we want to update a location – for example, if a country doesn't want to be part of a union anymore – we can change it in one place.
Snowflake in Power BI
Keep in mind that importing a schema like this as-is into Power BI can have unintended consequences. If you filter on geography – e.g., country is equal to the United States of America – you only get fact records where both the store and the customer are from the USA. You filter out all customers from other countries, such as Canada. Especially in online retail, this will be a big problem.
You can solve this by duplicating your dimension by either using views in the database or importing the dimension once into Power BI and copying it over there. This is called role playing dimensions. It's still the same dimension, but it takes on different roles depending on the relationship.
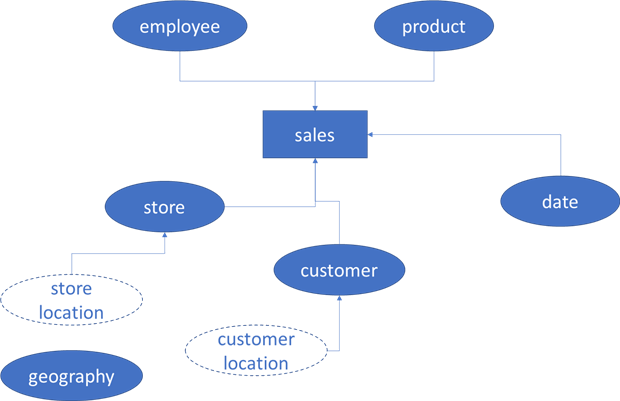
In the diagram above, both store and customer locations are views on top of the geography table. They basically take the same data but maybe rename the columns. The advantage is that such a schema in Power BI doesn't have issues when filtering on a location. You filter either on the store location and/or the customer location, but they don't interfere with each other.
In SSAS Multidimensional, you can create role playing dimensions in the model itself. More information can be found in this tip: Defining Role Playing Dimensions for SQL Server Analysis Services.
Another type of snowflaking is when you take part of a dimension and put it in a separate dimension. This may happen because these parts change often and you don't want to create too many history rows, or maybe because they're a logical entity on their own. A good example of this use case is within the Adventure Works sample data warehouse. There, we have a product dimension, a product subcategory dimension, and a product category dimension. In a star schema, all three tables would have been one product dimension, but here they are split into three different tables.
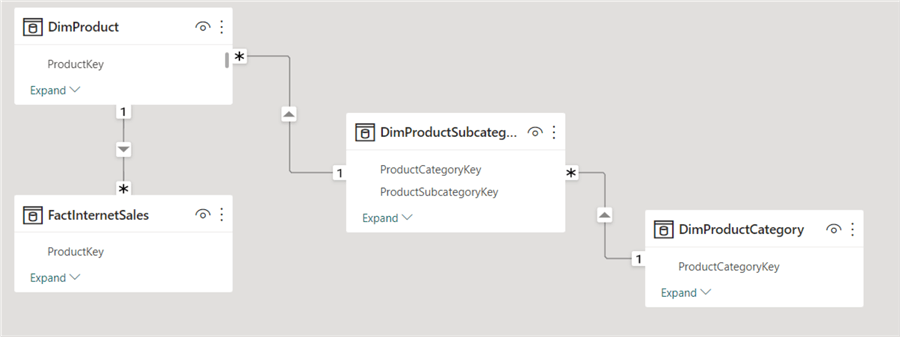
The advantage of this setup is that no filters interfere with each other because of how the foreign key relationships are laid out. When you filter on a product category, it filters the relevant subcategories, filters the relevant products, and finally filters the fact table.
Typically, this is done for the performance benefits of normalization: inserts, updates, and deletes are faster. But there are more joins when you query this data directly using SQL. In Power BI, this effect is probably negligible. In SSAS Multidimensional, you need to use the special relationship type called "referenced relationship" to implement such a schema. More info on this can be found in this blog post. In SSAS Tabular or Power BI, you don't have to take extra steps to make it work.
Conclusion
A snowflake schema is a special type of star schema in the dimensional modeling methodology. In a snowflake schema, some dimensions are not linked directly to a fact table, making the model more normalized. This is usually done to obtain some of the benefits of normalization, such as improved writing performance and reduced data redundancy.
Next Steps
- To learn more about star schemas, check out this tip
- How to Create a Star Schema in Power BI Desktop
- The Importance of a Good Data Model in Power BI Desktop
- Why Power BI loves a Star Schema
- Explore the Role of Normal Forms in Dimensional Modeling






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-04-04
