Problem
We are deploying a new application that uses PostgreSQL database. My manager has asked me to design high availability into the implementation. As a SQL Server database administrator, I’ve been managing PostgreSQL databases for a while. However, I’m not sure which high availability options to implement. What are the different high availability options for PostgreSQL?
Solution
You’re probably familiar with the different high availability options in SQL Server – how they work, their capabilities, and their limitations. PostgreSQL is the same, with its own capabilities and feature set. This tip provides a high-level overview of the different high availability options in PostgreSQL and their similarities with SQL Server.
NOTE: A discussion of high availability options should always start with being clear on your recovery point objective (RPO) and recovery time objective (RTO). How you choose your ideal solution should be dictated by your RPO/RTO. This should be your starting point.
High availability (HA) refers to a system’s ability to remain operational and accessible with minimal to no downtime. This means providing as much redundancy and resiliency to make sure there is no single point of failure. For a database system like PostgreSQL, this includes the hardware and database layers, as well as the application that provides the high availability capabilities.
Assuming that high availability at the hardware layer is already taken care of, your database requires a minimum of two servers to achieve high availability. These two servers will form part of a high-availability system: one acts as a primary server, while the other acts as a standby. In the event of a primary server failure, the standby server can quickly assume the role as the new primary server, minimizing downtime and, depending on your chosen solution, data loss.
However, for a standby server to take over the role of a primary server, it must be identical to the primary server, more specifically, the databases stored on disks. Ideally, the compute resources of the two servers – CPU cores and memory – are exactly the same.
Disk-based Options for High Availability
Shared Storage Subsystem
One way to ensure that the stored databases on disks look exactly the same on both the primary and standby servers is by storing them in a shared storage subsystem, like a storage area network (SAN).
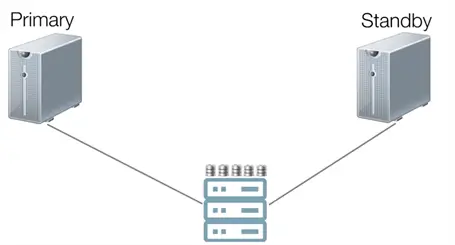
The primary and standby servers physically connect to the SAN. The SAN stores the databases instead of the local disks, and the database engine on both servers can see the databases exactly as they are.
In this configuration, only the primary server is running the database engine, accessing and controlling the databases on the SAN. The standby server’s database engine is not running. Only when the primary server becomes unavailable, a result of an outage, will the standby server take over the role as the new primary, starting the database engine and eventually taking over control of the database files.
The concept is similar to how SQL Server failover clustered instances (FCIs) work. But, similar to the limitations of SQL Server FCIs, the SAN is a single point of failure. This shared storage architecture also limits you to having a single copy of the database. If the SAN becomes unavailable, the databases become inaccessible. Even if you can force the standby server to start and take over the role as the new primary server, you still don’t have access to the databases on the SAN. While this is a great option for high availability, a shared storage architecture is still a single point of failure with a single copy of the database.
Shared Nothing Architecture
Another disk-based option for achieving high availability is by introducing a “shared nothing” architecture and having more than one copy of the databases. This is typically done by replicating the blocks on local disks from the primary server to the standby server.
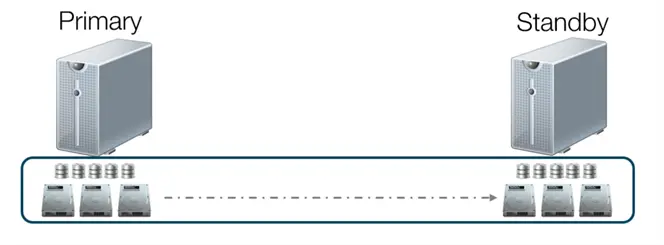
Similar to the shared storage configuration, the primary server is running the database engine, accessing and controlling the databases on the local disks. The standby server’s database engine is not running. Only when the primary server becomes unavailable, as a result of an outage, will the standby server take over the role as the new primary and start the database engine. And because the databases are being replicated from the primary server to the standby server using some form of disk-based, block-level replication, the standby server does not worry about not being able to access the databases because it has its own copy.
The concept is similar to how SQL Server failover clustered instances (FCIs) work, but it uses technologies like Storage Spaces Direct (S2D) on Windows Servers instead of a SAN. There are third-party tools, like SIOS DataKeeper, that can assist with disk-based, block-level replication.
On Linux, you can use the open-source distributed replicated block storage software DRBD, which stands for distributed replicated block device.
Database-level High Availability Solutions
Beyond simply relying on hardware to create multiple copies of the database for high availability, you can use PostgreSQL’s native data replication capabilities. Let’s look at these.
Introduction to Write Ahead Logging in PostgreSQL
Similar to SQL Server, PostgreSQL uses a log file to keep track of all transactions in the database. This is to guarantee data consistency and durability, the C and D in the ACID properties of databases. Changes to a PostgreSQL database are first written to a file called the write-ahead log (WAL).
If a transaction occurs on a database, PostgreSQL creates a log entry that contains all the essential information to recreate this transaction, if necessary. This log entry is then written to the WAL file.
At regular intervals, PostgreSQL performs a checkpoint process that persists the changes recorded in the WAL files and the database. Since the WAL file contains all the changes made to the database, PostgreSQL can use this information to read these log entries in case of a server restart and either roll forward all committed transactions or roll back uncommitted transactions to maintain data consistency.
By default, the size of the WAL file is 16MB. When a WAL file is full, PostgreSQL creates another one. A more detailed description of how write ahead logging works in PostgreSQL is beyond the scope of this tip.
Write Ahead Logging (WAL) Shipping
Since the WAL files contain essential information to recreate all the transactions in the database, you can use the WAL file to create a standby server containing an exact copy of the database. Configuring the primary server in continuous archiving mode allows for copying the WAL files from their current location to another location. Then, configuring the standby server in continuous recovery mode allows the standby to read the WAL files copied from the primary server.

This is similar to how SQL Server log shipping works. However, instead of copying and restoring backup files of the SQL Server transaction log, PostgreSQL copies and restores the WAL files themselves.
A step-by-step configuration of WAL shipping between two PostgreSQL servers will be covered in a future tip.
Streaming Replication
Streaming replication allows PostgreSQL to copy the WAL records directly (instead of the WAL files) from the primary server to the standby server. PostgreSQL does not have to wait until a WAL file is full on the primary server before it copies over to the standby server. You can think of this as WAL-records-based replication versus WAL-file-based replication with WAL shipping. As WAL records appear, the primary server streams the WAL records to the standby server. You can think of streaming replication as real-time WAL record shipping.
Streaming Replication Configuration
Configuration for streaming replication can be either synchronous or asynchronous (default).
In synchronous streaming replication, PostgreSQL considers a transaction committed only after being persisted on another synchronous standby server. This prevents any further operations until a transaction commit saves all the related WAL entries to disk. The primary server must wait for confirmation from the standby server that the corresponding WAL entries for a specific transaction were written to disk. This ensures as near-zero data loss as possible.
In asynchronous streaming replication, the primary server commits the transactions (WAL records written to the WAL file) first before sending them to the standby server. The primary server does not need to wait for confirmation from the standby server that the WAL entries have been written to disk. This configuration could potentially cause some data loss due to the delay between the WAL entries writing to disk on the primary server versus the standby server.
This is similar to how SQL Server Always On Availability Groups work, both synchronous commit and asynchronous commit replication modes.
A step-by-step configuration of streaming replication between two PostgreSQL servers will be covered in a future tip.
NOTE: Both WAL shipping and streaming replication are forms of physical replication. The PostgreSQL databases on the primary server and the standby server are exactly the same, all the way to the files on disk.
Logical Replication
Logical replication allows PostgreSQL to replicate data from a primary server to a standby server by reading the WAL file and translating WAL records into corresponding data manipulation language (DML) statements. Then, these DML statements go to and execute on the standby server. Since only DML statements replicate, you have the option to either replicate the entire database or a subset of the data, mostly tables.
Logical replication uses the publishing metaphor: the primary server acts as a publisher, the standby server acts as a subscriber, and the data to be replicated are “publications.” This is similar to how SQL Server replication works.
While logical replication is a great way to replicate data from the primary server to the standby server, it can be a challenge to use it as a high availability option if the goal is to minimize downtime and data loss. If the goal is high availability, the primary server and the standby server should look exactly the same. Logical replication is a great option for both distributing data for scalability and consolidating data from multiple sources.
Cluster Resource Manager
Earlier in this tip, I mentioned the “application that provides high availability capabilities.” The database engine relies on these applications, i.e., cluster resource managers, for high availability.
I’m sure you’re familiar with the Windows Server Failover Cluster (WSFC). WSFC is a type of cluster resource manager that SQL Server (both FCIs and AGs) relies on for high availability on a Windows Server environment. Without the WSFC, there’s no high availability. SQL Server can only replicate the data from a primary server to a standby server, just like how read-scale Availability Groups work. The WSFC is responsible for automatic failover, failure detection, and automatic client redirection from the primary server to the standby server.

Client applications connect to a virtual IP address. The cluster resource manager redirects the client application from the virtual IP address to the primary server. When the primary server becomes unavailable, the cluster resource manager automatically promotes the standby server as the new primary server. It also redirects client applications from the virtual IP address to the new primary server.
Linux Open Source Cluster Resource Managers
On Linux, there are several open-source cluster resource managers. One that SQL Server can use for either FCIs or AGs is Linux Pacemaker. You can use Linux Pacemaker for PostgreSQL when implementing disk-based options for high availability. While Linux Pacemaker is a great cluster resource manager, it is more for general purpose high availability and not designed with PostgreSQL in mind. This is where other open-source PostgreSQL HA solutions come in.
Patroni
Patroni is an open-source tool for implementing and managing high availability PostgreSQL solutions that leverage streaming replication. It’s a cluster resource manager built with PostgreSQL in mind. It works with other open-source tools like etcd, a distributed key-value store to keep track of the cluster configuration, and HAProxy, a robust high availability, load balancing, and proxying for TCP and HTTP-based applications. You can think of etcd as the cluster database in the WSFC while HAProxy is the virtual IP but with better capabilities like network load balancing.
repmgr
repmgr is similar to Patroni in that it is also an open-source tool for implementing and managing high availability PostgreSQL solutions that leverage streaming replication. But unlike Patroni, it does not rely on etcd for keeping track of the cluster configuration. It creates its own dedicated database to store the cluster configuration. This database gets replicated from the primary to the standby server as part of streaming replication. It also works with HAProxy for client application connectivity.
pg_auto_failover
pg_auto_failover is an open-source PostgreSQL extension for implementing and managing high availability PostgreSQL solutions that leverage streaming replication. Similar to repmgr, it has its own way of storing and keeping track of cluster configuration. It creates a PostgreSQL database on a third server called the monitor server. An agent running on both the primary server and the standby server controls the PostgreSQL service and communicates with the monitor server. pg_auto_failover controls and dictates the state of the primary server and standby server based on their health. It also works with HAProxy for client application connectivity.
There are many more cluster resource management tools available for PostgreSQL, both commercial and open-source. Evaluating and implementing these must be driven by your high availability requirements, skills, and available support.
A step-by-step of how to use these tools to provide high availability to PostgreSQL will be covered in a future tip.
Next Steps
- Explore the PostgreSQL documentation on the different high availability options.
- Read more on PostgreSQL tips to get familiar with how PostgreSQL works.
