Problem
You could learn the basics of Data Factory (in Azure, Synapse, or Microsoft Fabric) in a course or a tutorial. But real knowledge typically comes with experience. What are the things to look out for? What are the best practices? Those kinds of things take time to discover on your own. If you’re fortunate, you have a mentor or a senior colleague who can point them out to you. In this tip, we try to share some nuggets of wisdom regarding Azure Data Factory (ADF).
Solution
Part 1 of this tip focuses on two important aspects of Data Factory:
- The different reincarnations of Azure Data Factory. The same product is present in Azure Synapse Analytics, albeit with some small changes. And in Microsoft Fabric, you also have Data Factory, but with a bigger gap in features. For example, connection management is very different in Fabric than in the other two Data Factories.
- The cost of running pipelines. In Fabric, this is calculated into the CU usage of your capacity, but in Azure and Synapse, the cost depends on a variety of factors. If you’re not careful, costs can spin out of control.
If you haven’t already, check out part 1 for more details on those two topics. In this second part, we tackle the remaining tips of our top 5 must-knows.
Change the Default Settings!
As with almost all tools or services, it’s worth checking out the default settings and whether you want to change them. When configuring a new instance of Data Factory these are setting I change.
Billing Overview Per Pipeline
There is an option to split your bill in Azure per pipeline, instead of the more high-level factory instance.
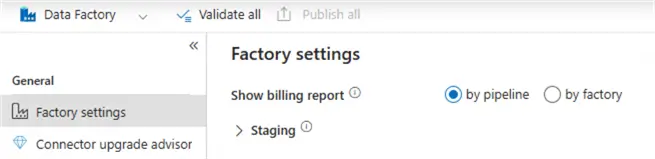
This gives a more detailed overview and allows one to find expensive pipelines quickly. Remember from part 1 that those pipelines are not necessarily huge pipelines with many activities; a frequently executed pipeline or a pipeline with a ForEach loop iterating over many items can become quite expensive. This setting doesn’t exist in Fabric.
Concurrency of a Pipeline
An ETL flow typically has a main pipeline that orchestrates the execution of other child pipelines. In most cases, you want only one instance of this pipeline to be executed at a given point in time, just like a SQL Server Agent job can have only one execution at a time. You don’t want one pipeline instance truncating your staging tables while another instance is busy copying data into those same tables. However, by default, ADF doesn’t prevent you from launching multiple executions of a pipeline. You can set the number of concurrent executions in the settings of the pipeline:
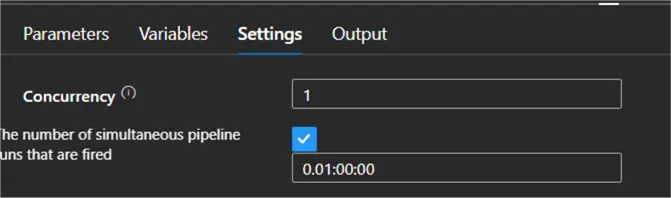
Set it to 1 if you don’t want any parallel executions. If the pipeline is already running and it’s started again (manually or by a trigger), it will wait until the first execution is finished before it starts executing.
Activity Time-outs
The default time-out for an activity is 12 hours! This means that if an activity hangs for some reason (for example, a webhook activity that is waiting for an Azure Function to respond, but the Function has crashed), it will take 12 hours before ADF stops the execution of the pipeline. Since cost is calculated per minute, this is a scenario you’d like to avoid.
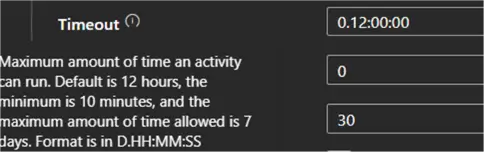
Rather, set the time-out to something more sensible for your activity, such as 10 minutes or an hour.
Copy Data Activity Maximum Data Integration Units
In part 1, it’s explained that the cost of a Copy Data activity depends on the Data Integration Units (DIU) and the execution time. You can set the max number of DIU in the settings.
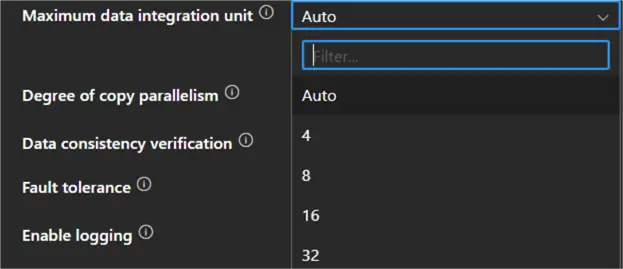
By default, this is set to Auto, which means ADF will choose the number of DIU depending on the data load, and it might auto-scale. The dropdown doesn’t show all possible values, though. According to the documentation, values between 4 and 256 are possible (most of the time, 4 is chosen as the default).

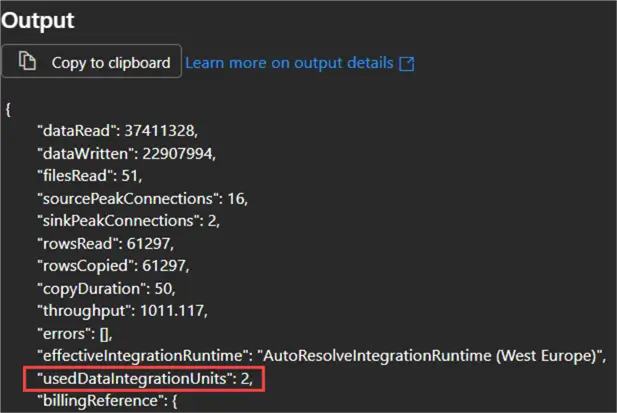
However, some time back, the value of 2 could be selected from the dropdown as well, which would lead to 50% savings on your Copy Data activity! This was useful for smaller data loads. You can still type in the number 2 if you want. Data Factory will show an error, but the pipeline can be validated and saved without an issue.

When we execute a Copy Data activity with this setting set to 2, we can observe the following output:
A similar Copy Data activity with the DIU setting set to Auto has the following output:
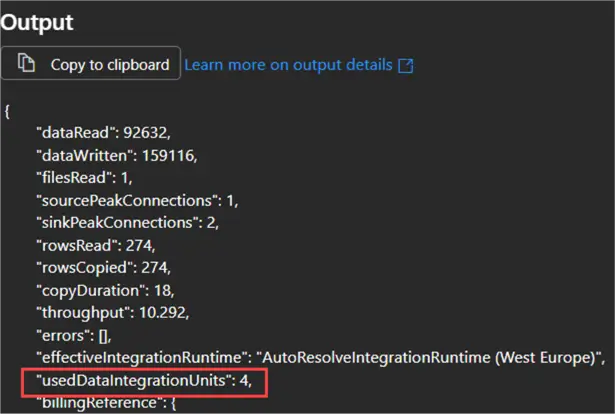
Set the Time to Live of Azure Runtime
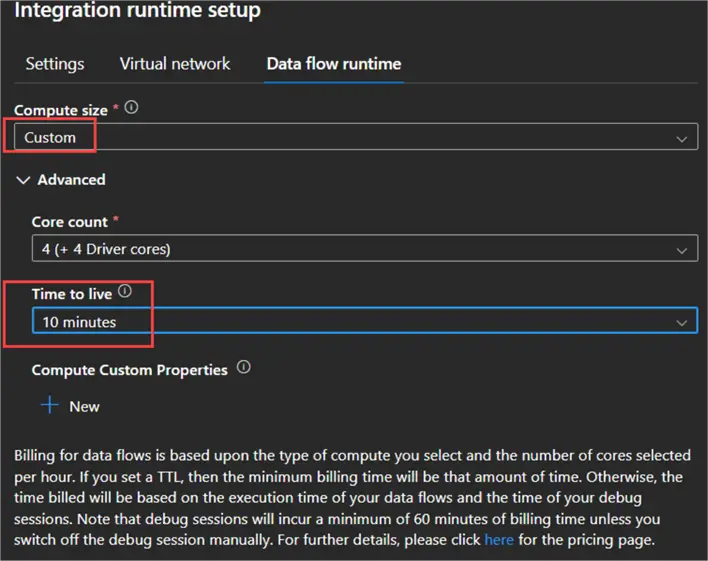
Suppose you are creating dataflows in Data Factory (Azure or Synapse). These are executed by a Spark cluster hosted in an Azure Integration Runtime. The startup time of a cluster can take a couple of minutes, so ideally, multiple dataflows share the same session instead of having to start up the cluster each time. To ensure the cluster is still live when the next dataflow begins, you can set the Time to live of the runtime. After a dataflow finishes, the cluster will remain idle for that period. If no other dataflow starts, it will shut itself down.
Git Integration
Like any piece of software, Data Factory should be integrated into a code repository. For the moment, git integration is supported in Azure Devops or GitHub. Git integration allows you to work with multiple developers on the same instance of Data Factory without overwriting each other’s changes using branches. It also allows you to deploy your Data Factory instances from one environment to another using CI/CD pipelines.
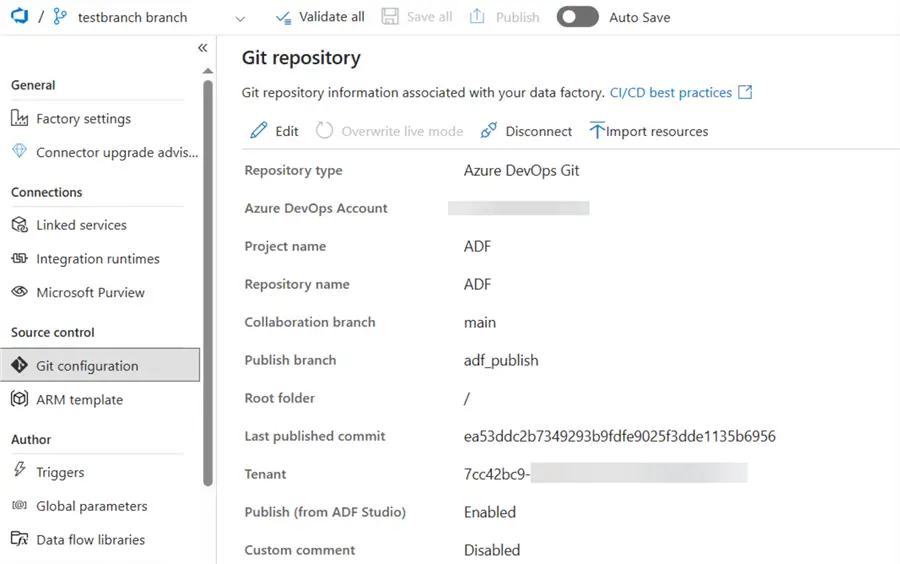
Typically, the development environment is integrated into git, while the other Data Factory (test, acceptance and/or production) are in live mode. You don’t edit pipelines in those other environments; changes are pushed through from the development environment using the CI/CD pipelines.
You can find more information in the tips Using Azure DevOps CI CD to Deploy Azure Data Factory Environments and Deploy CI/CD Changes for Azure Data Factory with Azure DevOps.
All versions of Data Factory (Azure, Synapse, and Fabric) support git.
ADF Shines as an Orchestrator
Now that we know how billing is calculated and that Copy Data activities and dataflows are the most expensive objects in Data Factory, we can conclude that ADF is a good orchestrator. This means that ADF shines in ELT scenarios: data is copied from the sources into a destination (a database or a storage location like a lakehouse) without any transformations (which is exactly what the Copy Data activity does). Once it’s in your desired location, you can orchestrate transformations using external activities (which are the cheapest in ADF), such as the Script or Stored Procedure activity, or a notebook activity when working with Spark.
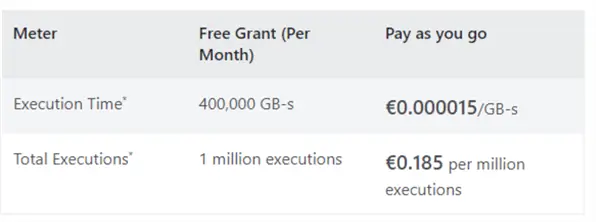
If the ingestion part is too expensive, you can try changing the maximum DIU as explained before, or by trying to load data incrementally. Another option is to outsource the ingestion part to something that is cheaper, such as Azure Functions or Azure Logic Apps. For example, when using the consumption plan for Azure Functions, the first million executions are free!
Next Steps
- If you have other tidbits of wisdom about ADF, please share them in the comments!
- If you want to learn more about ADF, check out the tutorial or this overview of all ADF tips.
- You can find Microsoft Fabric-related tips in this overview.
