By: Rick Dobson | Comments (5) | Related: 1 | 2 | 3 | 4 | > Other Database Platforms
Problem
Do you need to make SQL Server data available for a SAS Analytics package? Do you also need to accept some data back from a SAS package and also process the returned values? How can a SQL Server professional with limited or no SAS experience accomplish these goals?
Solution
SAS is a popular tool in such areas as healthcare and retail analytics. Therefore, if data you manage as a SQL Server professional has analytical applications in these or other areas, you may very well find yourself preparing data for SAS analytics professionals or even running SQL Server data through a SAS analytics package without support from SAS professionals. Since SQL Server and SAS are from different software vendors, newcomers to the task may find interoperability challenging.
This tip is the first in a two-part series on presenting a simple set of techniques to handle interoperability between SQL Server and SAS with minimum hassle. In this first installment, you get a hands-on feel for the topic starting with coverage of the reasons and steps for creating a staging table in SQL Server for transfer to SAS. This first installment takes you from a SQL Server staging table for SAS through to its transfer to a SAS data set. Tip support materials include a script for creating a table and populating it with values for export from SQL Server to SAS as well as a .csv file with data values that are ready for transfer to SAS. This installment in the series closes with some ways of enriching the solution and resources for learning more about SAS.
Some Background Thoughts about the Solution
Interoperability between SQL Server and SAS is complicated especially by incompatible data types. Natively, SAS supports just two data types:
- Characters up to a 32,767 character maximum
- Double precision floating point numbers
Because SQL Server data typing is much richer than SAS, translating SQL Server values for use with SAS can be challenging. Even the topic of representing and processing missing data values is substantially different between SQL Server and SAS. SQL Server represents missing data values with NULL values, but SAS has a minimum of two ways of representing missing values: a period (.) for numeric missing values and a blank space (' ') for character missing values. In some cases, these incompatibility issues may not matter, at other times, they will matter. In any event, when SQL Server professionals need to have their data interface with SAS packages, you should learn as much as possible about data typing and missing value representation and processing issues between SAS and SQL Server as your time permits.
The solution illustrated here takes advantage of SQL Server and SAS wizards to ready data and enable its transfer between SQL Server and SAS. Because the approach takes advantage of .csv files to transfer data between SQL Server and SAS, data typing issues are not explicitly addressed in any ways besides the way SQL Server and SAS wizards handle the creation and reading of .csv files.
Create and Populate a Staging Table for SAS
SAS analysis packs typically expect data from a single table. SQL Server professionals will frequently need to populate this table from multiple relational tables in a SQL Server database. You can think of this part of the solution as a two-step process. First, create a staging table with columns corresponding to the SAS pack variables. Second, populate the columns with values.
The following script illustrates the type of code that you might use to generate a SQL Server table on which to base a SAS data set. Name the columns according to the variable names for the SAS pack for which you are preparing data. Use data types that have default translations from SQL Server as close as possible to those required by the SAS pack.
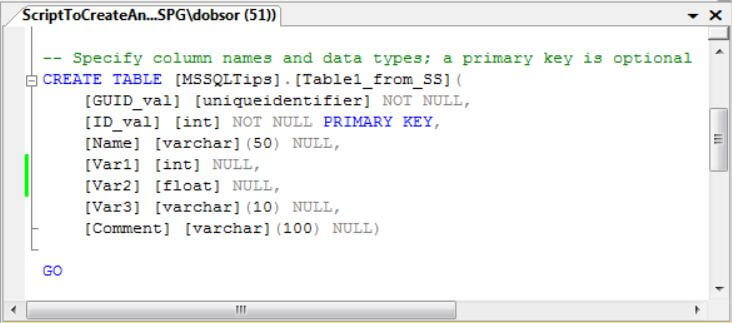
The script includes a primary key. The use of a primary key is strictly optional because SAS does not recognize SQL Server primary keys when data is transferred via .csv files. Nevertheless, you may find a primary key in the staging table useful for ordering your data for visual inspection before exporting them to SAS. SAS packs routinely use a numeric indicator to track rows in a SAS data set. Therefore, you may want a staging table column with an exact numeric data type, such as int or bigint, for this role. If you choose a bigint data type, be aware that very large bigint values can exceed the upper limit of a SAS numeric data type. Your original source data may use a uniqueidentifier data type to identify rows. SAS can map SQL Server uniqueidentifier values to character variables. If the SAS package you are using needs a numeric value for identifying rows, SQL Server uniqueidentifier values will not be appropriate.
After you create a table for the data to be exported to SAS, you need to populate the table. One approach to this task is to use an INSERT statement that derives source data from a SELECT statement or a SQL Server object, such as a view. The SELECT statement can de-normalize data from multiple SQL Server tables to your staging table for SAS. The de-normalization allows the staging table to have one row per entity, such as a person or a visit, although that entities may be in a one-to-many relationship with other columns in the source SQL Server database.
Using Wizards to Migrate a SQL Server table to a SAS Data Set
When you are able to use default settings for the SQL Server Export wizard and the SAS Import File wizard, you can export a table from SQL Server as a flat file in a comma separated values format (.csv) such that SAS can read the file and construct a SAS data set that has the same data values as the SQL Server staging table. This process can even succeed when the source data includes both character and numeric values -- some of which may be missing.
Start the process by launching the SQL Server Export wizard and specify the database containing your staging table for SAS as the Data Source. Designate a Flat File Destination on the Choose a Destination screen and browse to the path where you want your .csv file. Select CSV files as the file type and designate a name for the file, such as ForTable1_from_SS. Also select the check box for column names in the first row. Then, specify that you want to copy data from one or more tables and views before selecting the name and schema for the staging table. After this selection, you can use the remaining default Export wizard settings.
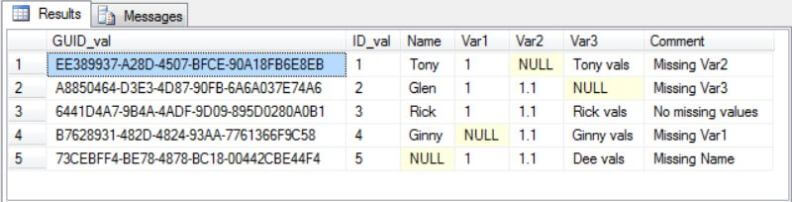
The following two screen shots illustrate some sample data for a staging table before and after export from SQL Server. The script available as a download with this article for creating and populating a staging table includes the sample data. Missing values are represented in the Results pane by NULL values; this view is before processing by the Export wizard. Notepad displays the exported data in a .csv file named ForTable1_from_SS. NULL values in the staging table appear as two commas with no value between them. Uniqueidentifier values are delimited by braces.

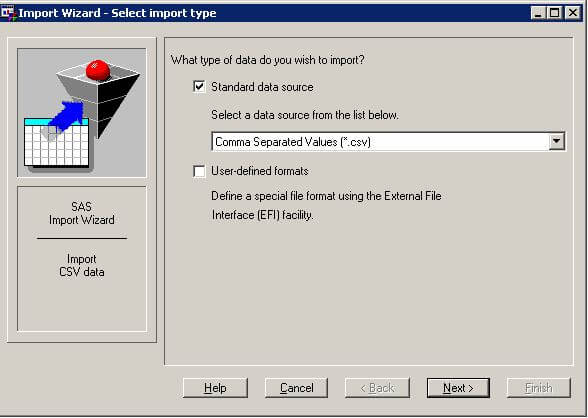
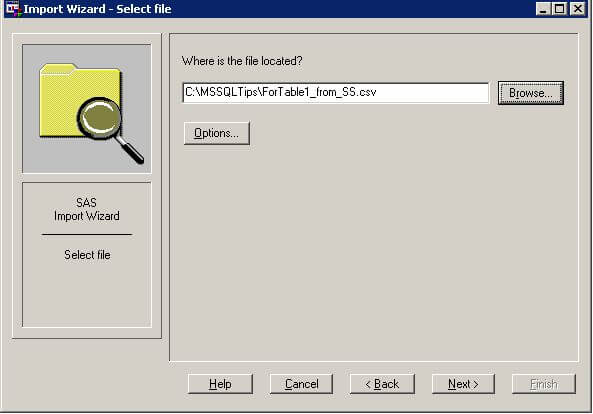
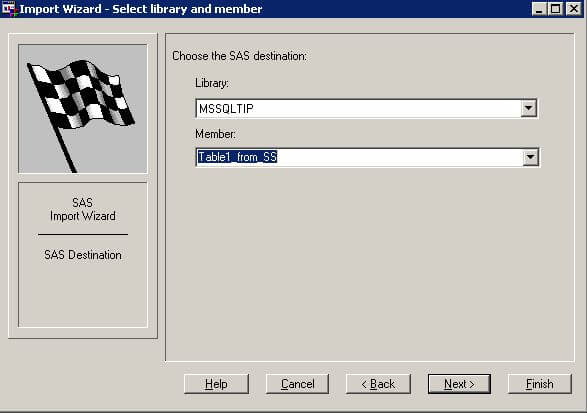
After creating a file of data values in .csv format, copy the file to a computer on which you are running SAS. Then, start SAS and make a menu choice of File, Import Data. This opens the first of the three screens that you see below. By default, the SAS Import Wizard is ready to accept a file in .csv format. Click Next to advance to the second screen below that allows you to browse to your .csv file. For this demonstration, the ForTable1_from_SS.csv file that was created with the SQL Server Export Wizard is in the MSSQLTips folder of the C: drive. Click Next to advance to the third screen below that allows you to indicate the name for your SAS data set and where it will be stored. By default, SAS creates the new data set in a temporary library named WORK. To facilitate easy re-use of the data set after the current session ends, you can instead choose to save the data set in a permanent library. The third screen below designates MSSQLTIP as the permanent library to store a data set named Table1_from_SS. After specifying what to name your data set and the SAS library in which to store it, you can click Finish.
Verifying the Data after Transfer to SAS
In response to clicking the Finish button, SAS creates the data set. If you completed the steps successfully, you can inspect the data set design and values with the following lines of SAS codes.
- PROC CONTENTS DATA=MSSQLTIP.Table1_from_SS;
- PROC PRINT DATA=MSSQLTIP.Table1_from_SS; RUN;
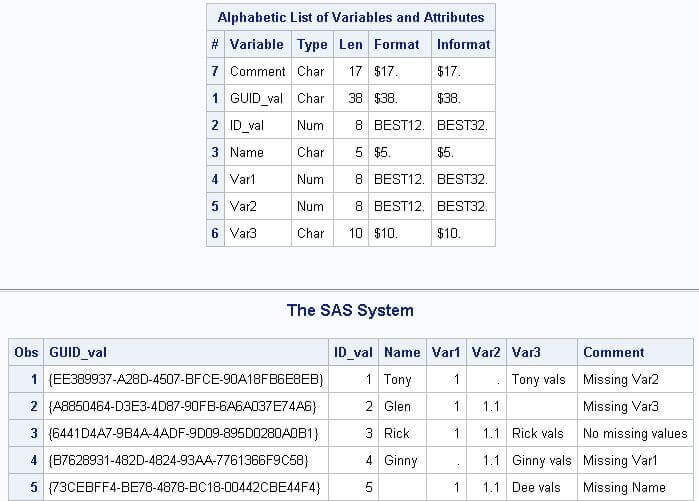
The following excerpt from the output of the above script shows the design and contents of the SAS data set. The top part of the screen excerpt displays metadata for the data set from the PROC CONTENTS. For example, you can see that ID_val column, which contained int data type values, is a numeric SAS variable. In contrast, the GUID_val column is a character variable of length 38; this LEN specification includes 36 characters for the numbers, letters, and dashes in the GUID representations and two additional characters for the opening and closing brace delimiters. The bottom portion of the display reveals the data contents from the PROC PRINT. Most rows in the data set have either a character or numeric missing value. The Comment column, indicates which, if any, column is missing. Those column values with a missing number appear with a period (.) as the column value. Columns with a missing character value just appear blank.
Next Steps
The second installment in this series will demonstrate the operation of a simple SAS pack with the transferred data from this tip. You'll also learn how to use the results computed in the SAS pack back in SQL Server. In both this installment and the next one, the goal is to rely heavily on wizards. This makes the approach easily adaptable by SQL Server professionals with limited SAS experience.
If your interoperability requirements between SQL Server and SAS require features that the wizards do not support, there are multiple options that can be pursued. For example, you can use a SSIS package to ready the SQL Server data for import by SAS as well as to transform returned data from SAS to appropriate SQL Server data type values. In addition, you can save the script created by the SAS File, Import wizard and then edit the saved script to perform additional transformations that a SAS pack may require. When you run the edited script, you will be invoking a customized SAS data step. If you are just getting started with transferring data from SQL Server to SAS, you can benefit by learning as much as possible about how SAS stores and uses data. I recommend you focus on ways of reading data with a custom SAS data step. Also, learn about the different ways that SAS handles missing values and dates from the ways SQL Server represents and processes these kinds of data. Here are some URLs that you can use to start learning more on your own while you waiting for the second installment in this series as well as other tips on SQL Server/SAS interoperability.
- The link to the MSSQLTips SSIS tutorial
- The link to an earlier MSSQLTips article on dynamic flat file connections without C#
- The link to the MSDN site on the Microsoft.SqlServer.Dts.Tasks.ScriptTask namespace
- The link to the MSDN site on the Microsoft.SqlServer.Dts.Runtime namespace






About the author
 Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.
Rick Dobson is an author and an individual trader. He is also a SQL Server professional with decades of T-SQL experience that includes authoring books, running a national seminar practice, working for businesses on finance and healthcare development projects, and serving as a regular contributor to MSSQLTips.com. He has been growing his Python skills for more than the past half decade -- especially for data visualization and ETL tasks with JSON and CSV files. His most recent professional passions include financial time series data and analyses, AI models, and statistics. He believes the proper application of these skills can help traders and investors to make more profitable decisions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
