By: Keith Gresham | Comments | Related: > Integration Services Performance
Problem
Sometimes a solution that worked fine on the day it was pushed to production will over time become too slow. One common cause is due to an ever increasing workload based on the sheer number of files that need to be processed. There's nothing wrong with the SQL Server Integration Services Package that is used to process these files. There's just too many files. You can throw new hardware at the problem, but you will eventually reach a point where processing the files one at a time takes too long.
There are solutions such as splitting the incoming data stream into multiple streams and processing each stream with a copy. This works, but has several disadvantages. If you need to change the flow logic you now need to change multiple instances of the package. Performance tuning to find the sweet-spot for the number of streams is a laborious task. If it runs on multiple servers you will need to keep different versions available. Read on for a better solution.
Solution
I will show you a method using a few lines of C# code that can greatly improve performance, and leave you with a very manageable solution.
Let's get started. This project assumes you have a basic understanding of SQL Server Integration Services (SSIS). We won't be covering how to create a work flow or setup a For Each Loop. If you get lost check the Next Steps section near the bottom for some helpful links. Copies of the packages are included in the Next Steps section.
Create Multiple Instances of a Single DTSX Package with C#
This solution shows you how to create multiple instances of a DTSX package using C# code. By having multiple instances of the package running we can greatly improve the time it takes to process a large number of files by having the loads occur in parallel.
Source Files
This project was created on SQL Server 2012 Developer Edition with the AdventureWorks2012 database as the source data. Here is a script to create some .CSV files that will be our source data. Change the @NetPath variable to a suitable location. The script will generate 6224 files consuming about 3 MB of disk space.
use [AdventureWorks2012]
GO
set nocount on;
if OBJECT_ID('tempdb..##Orders') is not null drop table ##Orders
create table ##Orders (SalesOrderID int, grp int, primary key (grp, SalesOrderID));
insert
##Orders (SalesOrderID, grp)
select
h.SalesOrderID, row_number() over (order by h.SalesOrderID) grp
from
sales.SalesOrderHeader h
where
h.TerritoryID = 4;
declare @MaxGrp int = (select max(grp) from ##Orders);
declare @Loop int = 1;
declare @cmd varchar(8000);
declare @SalesOrderID int;
declare @NetPath varchar(150) = 'E:\Temp\SSIS\';
while (@loop <= @MaxGrp)
begin
select
@SalesOrderID = (select SalesOrderID from ##Orders where grp = @loop),
@cmd = 'bcp "select ''SalesOrderID'',''SalesOrderDetailID'',''CarrierTrackingNumber'',''OrderQty'',''ProductID'',''SpecialOfferID'',''UnitPrice'',''UnitPriceDiscount'',''rowguid'',''ModifiedDate'' union all ' +
'select ltrim(d.SalesOrderID), ltrim(SalesOrderDetailID), CarrierTrackingNumber, ltrim(OrderQty), ltrim(ProductID), ltrim(SpecialOfferID), convert(varchar(20),UnitPrice), convert(varchar(20),UnitPriceDiscount), ltrim(rowguid), ' +
'convert(varchar(20),ModifiedDate,101) from AdventureWorks2012.sales.SalesOrderDetail d inner join ##Orders o on d.SalesOrderID = o.SalesOrderID and o.grp = ' + ltrim(@loop) + '" queryout "' + @NetPath + ltrim(@SalesOrderID) + '.csv" -T -c -t"|"';
exec xp_cmdshell @cmd, no_output;
set @Loop += 1;
end
Output Table
Here is a drop and create script for the table we will use as our target.
USE [AdventureWorks2012] GO if OBJECT_ID(N'sales.SalesOrderDetailImport',N'U') is not null drop table sales.SalesOrderDetailImport GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [sales].[SalesOrderDetailImport]( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))), [rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL, [ModifiedDate] [datetime] NOT NULL, CONSTRAINT [PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailImportID] PRIMARY KEY CLUSTERED ( [SalesOrderID] ASC, [SalesOrderDetailID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO
The File Loader Package
The purpose of the File Loader package is to do the work. It loops over a list of file names, loads data from each CSV file and inserts it into our target table.
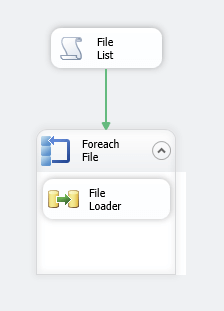
It starts with a Script Task that loads a System.Object named FileList with the list of file names that we want to load.
public void Main()
{
Dts.VariableDispenser.LockForRead("User::FileDirectory");
Dts.VariableDispenser.LockForRead("User::FileMask");
Dts.VariableDispenser.LockForRead("User::ThreadCount");
Dts.VariableDispenser.LockForRead("User::ThisThread");
Dts.VariableDispenser.LockForWrite("User::FileList");
Variables vars = null;
Dts.VariableDispenser.GetVariables(ref vars);
string fileDirectory = vars["User::FileDirectory"].Value.ToString();
string fileMask = vars["User::FileMask"].Value.ToString();
int threadCount = Convert.ToInt32(vars["User::ThreadCount"].Value);
int thisThread = Convert.ToInt32(vars["User::ThisThread"].Value);
var Directory = new DirectoryInfo(fileDirectory);
List srcFiles = new List();
if (Directory.Exists)
{
var sortedFiles = from f in Directory.GetFiles(fileMask).Select((fi, Index)
=> new { RowID = Index % threadCount, FileName = fi.Name })
where f.RowID == thisThread
orderby f.FileName
select f.FileName;
srcFiles.AddRange(sortedFiles);
}
vars["User::FileList"].Value = srcFiles.ToArray();
vars.Unlock();
Dts.TaskResult = (int)ScriptResults.Success;
}
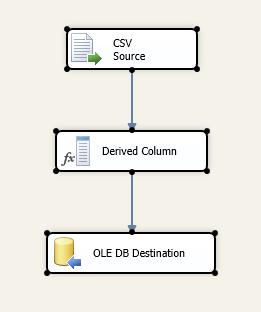
The FileList object is iterated over by a For Each Loop which passes the File Name to a Data Flow that contains our source and destination objects. The output from the CSV Source is feed into an OLE DB Destination which is our target table. The Derived Column object is used to fix an incoming GUID value by adding curly braces.
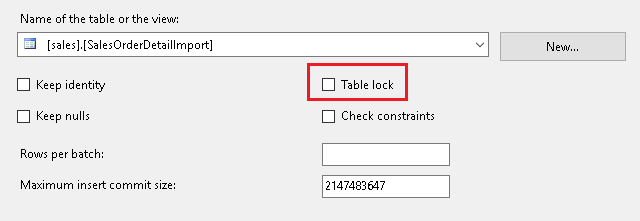
One important requirement is to disable table lock in the OLE DB destination. If you leave table lock enabled the instances will take turns writing to the destination table and you will see little improvement.
We want to split the whole set of files into groups and assign each group to be processed by a separate instance of our package. We assign a group to a particular instance through two integer values and modulus math (%). The first value is the total number of instances we will create and is called ThreadCount. The second value is the instance number for a particular instance and is zero-based. It is called ThisThread. See the bolded code in the C# code that fills the FileList object to see how these values are used.
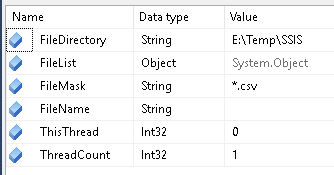
In the above example the two values, ThreadCount and ThisThread, are set so that this instance will process all the files. We now have a package that by changing the two integer values we can split the workload and assign a specific group of files to be loaded. For example if we set the values to ThreadCount = 4 and ThisThread = 1 we would split the files into 4 groups and process the 2nd group of files with this instance.
The Instance Manager Package
The purpose of the Instance Manager Package is to create a simple interface for creating multiple instances of our loader package. The Instance Manager Package starts with a SQL Task to truncate our target table.
Everything else is handled in this Script Task.
public void Main()
{
try
{
Dts.VariableDispenser.LockForRead("User::FileDirectory");
Dts.VariableDispenser.LockForRead("User::FileMask");
Dts.VariableDispenser.LockForRead("User::DTSXPackageDirectory");
Dts.VariableDispenser.LockForRead("User::DTSXPackageName");
Dts.VariableDispenser.LockForRead("User::ThreadCount");
Variables vars = null;
Dts.VariableDispenser.GetVariables(ref vars);
string fileDirectory = vars["User::FileDirectory"].Value.ToString();
string fileMask = vars["User::FileMask"].Value.ToString();
string dtsxPackage = Path.Combine(vars["User::DTSXPackageDirectory"].Value.ToString(), vars["User::DTSXPackageName"].Value.ToString());
int threadCount = Convert.ToInt32(vars["User::ThreadCount"].Value);
vars.Unlock();
var Threads = new List();
for (int i = 0; i < threadCount; i++)
{
int thisThread = i;
var thread = new Thread(() => RunPackage(threadCount, thisThread, fileDirectory, fileMask, dtsxPackage));
thread.Start();
Threads.Add(thread);
}
while (Threads.Any(t => t.ThreadState == System.Threading.ThreadState.Running))
{
Thread.Sleep(1000);
};
Dts.TaskResult = (int)ScriptResults.Success;
}
catch
{
Dts.TaskResult = (int)ScriptResults.Failure;
}
}
static void RunPackage(int threadCount, int thisThread, string fileDirectory, string fileMask, string dtsxPackage)
{
Application app = new Application();
Package pkg = app.LoadPackage(dtsxPackage, null);
Variables vars = pkg.Variables;
vars["FileDirectory"].Value = fileDirectory;
vars["FileMask"].Value = fileMask;
vars["ThisThread"].Value = thisThread;
vars["ThreadCount"].Value = threadCount;
pkg.Execute(null, vars, null, null, null);
}
The code will loop and create some number of instances of the package based on the value of ThreadCount. In each loop we create a local variable called thisThread and assign it the loop counter value so it remains static. In the function call to RunPackage we initialize the package variables to the values for this particular instance of our package. Once are the threads are running we continuously test the list of threads until all of them have finished. This is done in the while loop. When all the threads have finished the Script Task ends.

Now all we need to do is change the value of ThreadCount in our Instance Manager Package to create a specific number of package instances. Our workload will automatically be split evenly between each instance.
Time to Test the Performance of our Solution
I recorded the elapsed time as reported in the Progress Information tab.
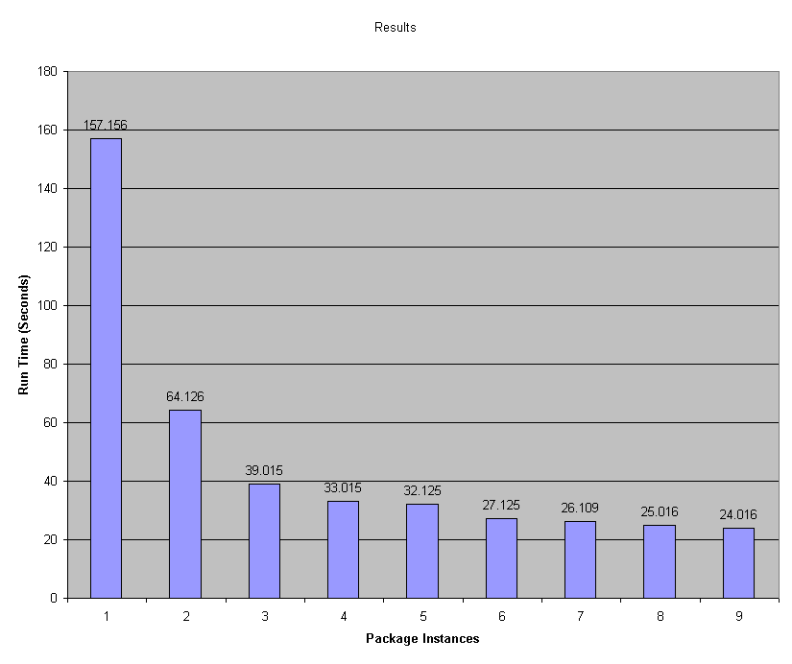
With the ThreadCount set to 1 we have a single instance of our package which we will use as our baseline. Our baseline run took 157 seconds to complete. For each subsequent run the ThreadCount was incremented by 1. This continued while each subsequent run produced better results. With the ThreadCount set to 9 we had our best run which took just 24 seconds to complete. This is a near 7-fold improvement over our baseline! At ThreadCount set to 24 it took 1 second longer than our best time. At this point the overhead of additional instances is offsetting any improvements.
Conclusion
This technique makes it very easy to scale up and down based on changing workload, hardware and process. Almost every process will benefit from 2 or 3 instances. Some will benefit from 24 or more. And in the end you have one package to manage. I hope you find this tip useful.
Next Steps
- Help with Techniques Used But Not Covered in this Tip:
- Loop through Flat Files in SQL Server Integration Services
- How To Implement Batch Processing in SQL Server Integration Services SSIS
- More on improving Performance:
- SQL Server 2008 Transaction Logging Enhancements
- SQL Server Integration Services SSIS Best Practices
- Project Downloads






About the author
 Keith Gresham is a Senior Database Developer with 15 years of experience with SQL Server and has a broad experience in manufacturing and energy with a focus on software development.
Keith Gresham is a Senior Database Developer with 15 years of experience with SQL Server and has a broad experience in manufacturing and energy with a focus on software development.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
