By: Tim Smith | Comments | Related: > PowerShell
Problem
We have thousands of comma-delimited files that have a header row, along with rows of data with the first column being the definition of the row (similar to a key value format, except the value is actually comma-delimited values). We would like to perform initial aggregates on to obtain the average in the numerical data before we import these data. If the values from our analysis are validated by our application, we will proceed with importing the data. Rather than import the data file-by-file into SQL Server and perform the aggregates on these data, we want to know if we could use PowerShell to read a file into a structure from a comma-delimited file from these files that we could use within our existing validation, where we compare a value to a value we expect. We suspect that we’ll only import up to 5% of the total files based on the history of validating the aggregate information.
Solution
With PowerShell, we have a few options for reading data from files which include some of the built in functions, such as Get-Content, to using the .NET library. Since we want to analyze the data we have, we'd like to read these data from a structure where we can do our analysis. Importing data into SQL Server offers a one route to do analysis, especially since the files are delimited and match the format.
In this tip, we will use the StreamReader library with the split method to read a comma delimited file into a hash table, where we can store information in a key-value pair format and use the value part of the pair to store an array of values. In this tip, we used StreamReader to read each line before writing the line if it had an invalid amount of characters. Similar to reading each line, we'll look at reading some of a file's data into a hash table, then explore what options we have for aggregates or getting details about a file prior to importing them.
Our first step will be to create two file formats - one with machine learning results and the other with weather data. We're using two different files types as an example here for testing. In reality, if we had thousands of files in different formats and didn't know what they were, we could use some of our examples below to explore the files.
open.txt
Test,Result1,Result2,Result3,Result4 Test1,1,1,0,0 Test2,1,0,1,0 Test3,0,1,1,0 Test4,0,1,0,0 Test5,0,0,0,1 Test6,0,1,0,0 Test7,0,0,0,0 Test8,0,1,0,0 Test9,0,0,0,0 Test10,0,1,0,0 Test11,1,0,1,1 Test12,1,1,1,0 Test13,1,0,1,0 Test14,1,0,1,1 Test15,1,1,1,1
weather.txt
City,2013,2014,2015,2016,2017 New York,72,71,70,70,70 Phoenix,90,90,90,90,90 Los Angeles,83,80,81,80,80 Omaha,73,72,70,72,70 Nashville,71,75,76,72,71
In the first file, we have output results from machine learning tests with the first value of the delimited file being the test number and the remaining values being the results of the tests – 1 passing and 0 failing. In the second file, we have cities with weather values saved by year. We’ll note how each line follows a key-value pair with the values being an array separated by commas.
In our first step, we want to create an empty hash table and array. As we iterate over each line in the file (the loop will stop when it can’t find a line), we’ll use the split function to create an array for our values in the key-value pair, and the key. In the below code, we only iterate over each line of the file we’re testing – in this case, open.txt - and we see the output in the below image.
$file = "C:\import\open.txt"
$resulthashtable = @{ }
$arrayiterate = @()
$readfile = New-Object System.IO.StreamReader($file)
while (($line = $readfile.ReadLine()) -ne $null)
{
$line
}
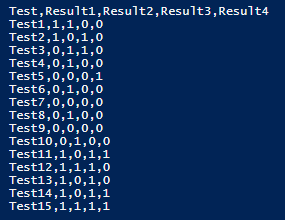
In our next step, we'll first add a line counter because we want to skip the first row and save this information to a header array (see in the else in the below code). If we think of these files as tables where the commas separate the columns and the new lines are new rows, our first line is a header, our first column is a varchar column, and the remaining columns are numeric. Since we initially want the numeric values in the remaining rows will be in the value of the key-value pair inside of an array, we will split the line by a comma starting at the 1rst location (the 0th location is the key in the key-value pair) and add all the numeric values to the array ($arrayiterate). We then add the key ($line.Split(",")[0]) along with the value, which is the array of values.
$file = "C:\import\open.txt"
$resulthashtable = @{ }
[int]$lineno = 1
$readfile = New-Object System.IO.StreamReader($file)
while (($line = $readfile.ReadLine()) -ne $null)
{
if ($lineno -ne 1)
{
$arrayiterate = @()
$arrayiterate += $line.Split(",")[1..($line.Split(",").Count-1)]
$resulthashtable.Add($line.Split(",")[0],$arrayiterate)
}
elseif ($lineno -eq 1)
{
$arrayheader = @()
$arrayheader += $line.Split(",")[1..($line.Split(",").Count-1)]
}
$lineno++
}
$readfile.Dispose()
$resulthashtable
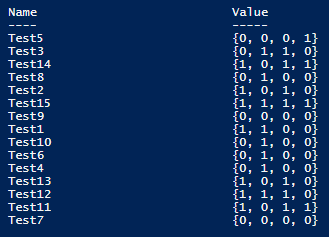
The line count helps us save the header data into the header array ($arrayheader), while the remaining file is parsed into our key-value pair, with the value being an array of numerical values. From the above image, we see the output of the keys (under Name) with the names of the test and under Value, the numerical values of each test inside of the array.
Our next step will be to add the ability to return an average for one of the elements within the value array. We could iterate over each of the values within the hash table and get the specific element number of the array, such as the second element of the array (Test2), or we could aggregate the sum of a specific value within the file reading loop. Since the hash table shows us how the set of numeric values is delineated when we read into it, we can use the same split method with the reader to get the sum of the values as we read the file.
In the below code, we eliminate the hash table and add two variables - a position value ($arpos) that determines which numerical element we'll be using and an aggregate value ($aggregate) that adds all the values of the numerical position we select. The first column of our file, if we think of it as a table, is all text, not numbers.
$file = "C:\import\open.txt"
$arpos = 1
$readfile = New-Object System.IO.StreamReader($file)
[int]$aggregate = 0
[int]$lineno = 1
while (($line = $readfile.ReadLine()) -ne $null)
{
if ($lineno -ne 1)
{
$aggregate += $line.Split(",")[$arpos]
}
else
{
$arrayheader += $line.Split(",")
}
$lineno++
}
$readfile.Dispose()
$aggregate
$lineno
($aggregate/($lineno-1))
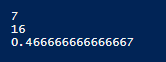
We see that we get a value of 0.5333333 (8 out of 15 values are 1). There is a possible bug, since we are not using the hash table anymore - in some cases StreamReader will see another line that does not exist (a blank) and thus our $lineno - 1 would have to change to $lineno - 2. We can use a hash table alternative, which will add extra steps if we only want to get the average, but avoids this bug and allows us to get other aggregate values, such as the minimum and the maximum. Because we are adding the aggregate values to the hash table, we take the average first so that the count is accurate, then we add the minimum and maximum by sorting the hash table.
$file = "C:\import\open.txt"
$arpos = 2
$readfile = New-Object System.IO.StreamReader($file)
$resulthashtable = @{ }
[int]$lineno = 1
[int]$aggregate = 0
while (($line = $readfile.ReadLine()) -ne $null)
{
if ($lineno -eq 1)
{
$key = $line.Split(",")[$arpos]
}
else
{
$resulthashtable.Add(($lineno-1),$line.Split(",")[$arpos])
}
$lineno++
}
$readfile.Dispose()
foreach ($value in $resulthashtable.Values)
{
$aggregate += $value
}
$hashres = @{ }
$hashres.Add("Avg",($aggregate)/($resulthashtable.Count))
$hashres.Add("Min",($resulthashtable.GetEnumerator() | Sort-Object Value | Select-Object -First 1).Value)
$hashres.Add("Max",($resulthashtable.GetEnumerator() | Sort-Object Value | Select-Object -Last 1).Value)
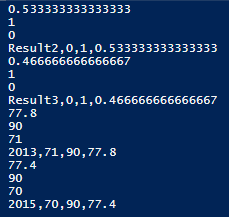
$hashres

Finally, we'll wrap this into a function and give the user the choice of returning the minimum, the maximum, the average, or all the details in a comma delimited list, which will start with the value name (such as Test2). With these options, we can then validate values from files prior to importing if we have rules of validation, such as weather data that cannot be above 140 degrees, or home price data that can't be below an average of 5000.
Function CreateHashSummary-FromFile {
Param(
[Parameter(Mandatory=$true)][string]$file
, [Parameter(Mandatory=$true)][int]$arpos
, [Parameter(Mandatory=$true)][ValidateSet("Min","Max","Avg","All")][string]$option
)
Process
{
$readfile = New-Object System.IO.StreamReader($file)
$resulthashtable = @{ }
[int]$lineno = 1
[int]$aggregate = 0
while (($line = $readfile.ReadLine()) -ne $null)
{
if ($lineno -eq 1)
{
$key = $line.Split(",")[$arpos]
}
else
{
$resulthashtable.Add(($lineno-1),$line.Split(",")[$arpos])
}
$lineno++
}
$readfile.Dispose()
foreach ($value in $resulthashtable.Values)
{
$aggregate += $value
}
$hashres = @{ }
$hashres.Add("Avg",($aggregate)/($resulthashtable.Count))
$hashres.Add("Min",($resulthashtable.GetEnumerator() | Sort-Object Value | Select-Object -First 1).Value)
$hashres.Add("Max",($resulthashtable.GetEnumerator() | Sort-Object Value | Select-Object -Last 1).Value)
if ($option -ne "All")
{
$hashres[$option]
}
elseif ($option -eq "All")
{
($key + "," + $hashres["Min"] + "," + $hashres["Max"] + "," + $hashres["Avg"])
}
}
}
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 2 -option Avg
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 2 -option Max
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 2 -option Min
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 2 -option All
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 3 -option Avg
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 3 -option Max
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 3 -option Min
CreateHashSummary-FromFile -file "C:\import\open.txt" -arpos 3 -option All
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 1 -option Avg
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 1 -option Max
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 1 -option Min
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 1 -option All
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 3 -option Avg
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 3 -option Max
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 3 -option Min
CreateHashSummary-FromFile -file "C:\import\weather.txt" -arpos 3 -option All
Our next step from here could look something like the below code, where we iterate over 24 comma delimited weather files from warmer climates each month and validate these files are within certain ranges, outputting the names of the files that are within the range we want. In this example, we use all the validation, but in some cases we may only use the average or the minimum depending on the data set.
$files = Get-ChildItem "C:\import\" -Filter *.txt
foreach ($file in $files)
{
$count = 0
$validate_exampleone = CreateHashSummary-FromFile -file $file.FullName -arpos 1 -option All
if (($validate_exampleone.Split(",")[1] -lt 15) -or ($validate_exampleone.Split(",")[2] -gt 140))
{
$count++
}
$validate_exampletwo = CreateHashSummary-FromFile -file $file.FullName -arpos 1 -option Avg
if (($validate_exampletwo -gt 25) -and ($validate_exampletwo -lt 140))
{
$count++
}
if ($count -eq 2)
{
$file.FullName
}
}
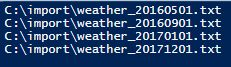
Out of the 24 files from each month, we see that only 4 files met our criteria. If you tend to get thousands of comma-delimited files and only import 5% due to possible values that are outside the range you're seeking (or possibly inaccurate), this script may be useful in contexts where the files follow the same format.
Next Steps
- The split function can be called on other characters, such as the vertical bar (|), period (.), etc. Since we were looking at comma delimited files, we used this as the delimiter in this function and we could make this part of the function dynamic, if we received files that were delimited by another character.
- We can this for pre-validating data in some cases, or we may use it for taking averages of our data, if that's our only need. We may have data where we only want to look at the average of values over a period of time or for a specific parameter from a file and never import into a database.
- If data don't follow the same structure within the comma delimited file, meaning that temperatures may be in a different column order, it may be faster to import the data into SQL Server, run a data validation script, and drop the table if it does not pass. This alternative of reading through a file works best when the files types are identical in structure.






About the author
 Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.
Tim Smith works as a DBA and developer and also teaches Automating ETL on Udemy.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
