By: Svetlana Golovko | Comments (3) | Related: > Replication
Problem
We need to provide a department a copy of the production OLTP database with a subset of tables for close to real-time reporting. The OLTP database has a lot of transactions and can't be used for ad-hoc queries, so we would like to offload the business reporting to a separate database.
Some popular options for the reporting databases copies include Read-only AlwaysOn Availability Group Replica or Log Shipping. But we can't use these options as the new reporting database is going to have different indexes for reports and ad-hoc queries. Also, the new reporting database requires a different set of permissions.
Extracting data using SSIS (SQL Server Integration Services) packages or other types of data extracts won't work as well as this has to be "live data" and not all tables have timestamp columns that we can use.
The best solution in our case is transactional replication, but there are some limitations though. The source database is used by a third-party application. Some tables have clustered and/or unique indexes, but the database doesn't have primary keys. We can't make changes to the existing objects, but we can create new ones.
How can we (or can we) configure transactional replication without primary keys?
Solution
There is no direct reference in the replication documentation to primary keys as a requirement for transactional replication, but we were able to find a note under the Replication FAQs (frequently asked questions) here:
"...Transactional replication requires a primary key constraint on each published table."
Transactional Replication Basic Configuration
There are a couple of steps that you need to perform before you create a publication for transactional replication. See this tutorial for the transactional replication preparation steps.
After the distributor is configured and all other prerequisites are ready we can start the publisher configuration for the transactional replication.
Let's create a sample database to demonstrate the Primary Keys requirement for the transactional replication.
The database will have one table with a primary key and tree tables without (one without indexes, one with clustered index, and one with unique nonclustered index):
CREATE DATABASE [_DemoDb] GO USE [_DemoDB] GO -- create table with Primary key CREATE TABLE dbo.[_ReplPk]( c1 int NOT NULL, c2 varchar(20) NULL, CONSTRAINT PK__ReplPk PRIMARY KEY CLUSTERED ( c1 ASC)) ON [PRIMARY] GO -- create table without Primary key CREATE TABLE dbo.[_ReplNoPk]( c1 int NOT NULL, c2 varchar(20) NULL) GO -- create table with CLustered Index and no Primary key CREATE TABLE dbo.[_ReplNoPkClust]( c1 int NOT NULL, c2 varchar(20) NULL) GO CREATE CLUSTERED INDEX CIX_1 ON dbo.[_ReplNoPkClust] ( c1 ) GO -- create a table with Unique Index and no Primary key CREATE TABLE dbo.[_ReplNoPkUnique]( c1 int NOT NULL, c2 varchar(20) NULL) GO CREATE UNIQUE NONCLUSTERED INDEX UNIX_1 ON dbo.[_ReplNoPkUnique] ( c1 ) GO
After we created the database and tables, we can start the New Publication Wizard from SQL Management Studio (SSMS):
Click "Next" on the first screen of the Wizard:
Select the database we created for our testing:
Choose the "Transactional publication" type:
We can review our tables on the next screen.
Note, that we can only select one table in our demo database. It is the table that has a primary key on it:
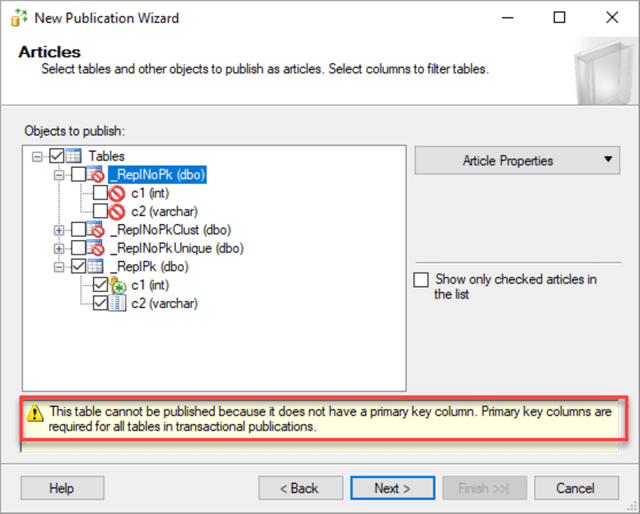
The rest of the tables have a warning that a table cannot be published because it doesn't have a primary key column.
We can reproduce some of the steps from the wizard using T-SQL. Note, that some parameters for the replication stored procedures are omitted here only to demonstrate the primary key requirement:
use [_DemoDb] GO -- Enable database for replication/publishing EXEC sys.sp_replicationdboption @dbname = N'_DemoDb', @optname = N'publish', @value = N'true' GO -- Add the transactional publication EXEC sys.sp_addpublication @publication = N'test', @sync_method = N'concurrent', @retention = 0, @repl_freq = N'continuous', @status = N'active', @independent_agent = N'true' GO -- Add an article to the publication EXEC sys.sp_addarticle @publication = N'test', @article = N'_ReplNoPk', @source_owner = N'dbo', @source_object = N'_ReplNoPk' GO
When we try to add an article to the transactional replication (sp_addarticle) for the table without a primary key we get this error:

Using Materialized Views to Replicate Tables without Primary Keys
This Microsoft documentation describes replication article types. The default article type is a table article, but we can also replicate views, indexed views, stored procedures, user-defined functions, and stored procedure execution.
As we can't replicate the tables without primary keys the solution for the replication problem in our case will be creating indexed views and replicating these views. These indexed views will contain columns from the tables that the business needs for the reporting.
The high-level solution will be:
- Create a segregated schema in the source (third-party) database to separate new objects from the vendor's objects.
- Create indexed views in the new schema.
- Create indexes on the new indexed views. Some of the views will have clustered indexes, others - unique indexes (based on the source tables indexes).
- Create a subscriber (reporting) database with table names the same as the source tables (for better portability of the existing reporting views). We will use the same schema name as the source tables schema as well.
- Create publication articles on the indexed views that will replicate data to the pre-created tables on the subscriber. These articles could be created with T-SQL only.
- Create a subscription.
To replicate the data using indexed views we will need to use the sp_addarticle stored procedure with @type parameter set to the "indexed view logbased".
SSMS only creates articles for the views with "indexed view schema only" type. To demonstrate this, we will create the indexed views in our demo database:
USE [_DemoDB] GO -- Set the options to support indexed views SET NUMERIC_ROUNDABORT OFF; SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT, QUOTED_IDENTIFIER, ANSI_NULLS ON; GO -- Create views with schemabinding CREATE VIEW dbo.vw_ReplNoPk WITH SCHEMABINDING AS SELECT c1, c2 FROM dbo.[_ReplNoPk] GO CREATE VIEW dbo.vw_ReplNoPkClust WITH SCHEMABINDING AS SELECT c1, c2 FROM dbo.[_ReplNoPkClust] GO CREATE VIEW dbo.vw_ReplNoPkUnique WITH SCHEMABINDING AS SELECT c1, c2 FROM dbo.[_ReplNoPkUnique] GO
We will run now the New Publication Wizard again and select our new indexed views for the publication, but at the end of it instead of creating the publication, we will save the wizard's results to a script.
Here are some observations during stepping through the wizard:
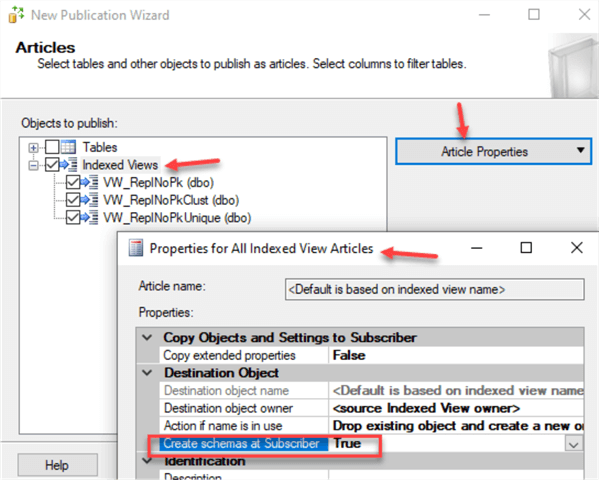
When we select our indexed views to create an article, we have the default option to create a schema at the Subscriber. That is not what we want. We want to replicate the content of our indexed views (not the view definition) to the tables on the Subscriber.
On the next screen we have a warning about SQL Server Enterprise Edition:
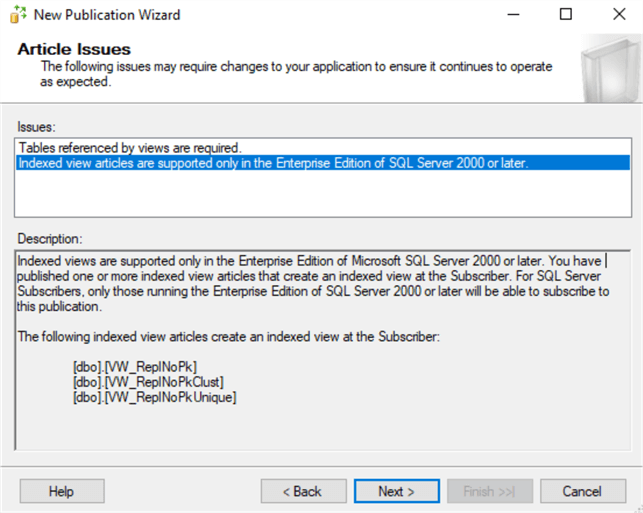
This is related to the fact that by default the Publication Wizard sets the option to create the indexed views on the Subscriber. We are not going to replicate indexed view definitions, so we can ignore both warnings under the "Article Issues".
Let's review the script that was generated by the Publication Wizard with the default options.
When we scroll to the line with "sp_addarticle" we can see that the article type is "indexed view schema only":

This will replicate only the indexed view definition, but not the data.
Final Solution using Materialized Views for Transactional Replication
Let's clean up our demo database and create objects in the source database (publisher) and the destination (subscriber):
Cleanup objects that we created for the previous demo:
USE [_DemoDB] GO -- cleanup demo objects DROP VIEW dbo.vw_ReplNoPk GO DROP VIEW dbo.vw_ReplNoPkClust GO DROP VIEW dbo.vw_ReplNoPkUnique GO
Create the final indexed views for the replication:
USE [_DemoDB] GO -- create the new (non-vendor) schema CREATE SCHEMA indviews GO -- Set the options to support indexed views SET NUMERIC_ROUNDABORT OFF; SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT, QUOTED_IDENTIFIER, ANSI_NULLS ON; GO -- Create views with schemabinding CREATE VIEW indviews.vw_ReplNoPkClust WITH SCHEMABINDING AS SELECT c1, c2 FROM dbo.[_ReplNoPkClust] GO CREATE VIEW indviews.vw_ReplNoPkUnique WITH SCHEMABINDING AS SELECT c1, c2 FROM dbo.[_ReplNoPkUnique] GO
Create a subscription database and destination tables that will match the source tables (not the indexed views):
USE [master] GO CREATE DATABASE [_DemoDB_Subscriber] GO USE [_DemoDB_Subscriber] GO CREATE TABLE dbo.[_ReplNoPkClust]( c1 int NOT NULL, c2 varchar(20) NULL) GO CREATE TABLE dbo.[_ReplNoPkUnique]( c1 int NOT NULL, c2 varchar(20) NULL) GO
Note, that if we don't create indexes on the indexed views before we create a publication article we will get this error:
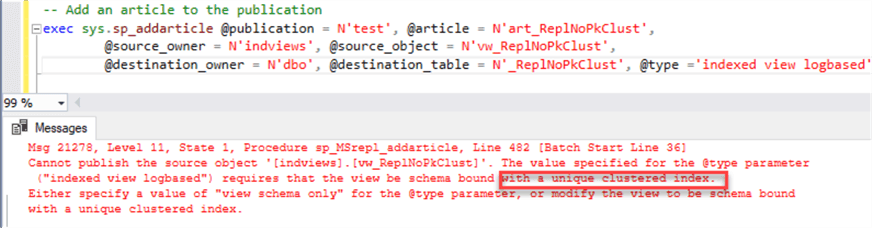
We need to create unique clustered indexes on our indexed views:
USE [_DemoDB] GO CREATE UNIQUE CLUSTERED INDEX CI_vw_ReplNoPkClust ON indviews.vw_ReplNoPkClust ( c1 ASC) ON [PRIMARY] GO CREATE UNIQUE CLUSTERED INDEX CI_vw_ReplNoPkUnique ON indviews.vw_ReplNoPkUnique ( c1 ASC) ON [PRIMARY] GO
Now we are ready to create the replication articles:
USE [_DemoDB] GO -- Add articles to the publication EXEC sys.sp_addarticle @publication = N'test', @article = N'art_ReplNoPkClust', @source_owner = N'indviews', @source_object = N'vw_ReplNoPkClust', @destination_owner = N'dbo', @destination_table = N'_ReplNoPkClust', @type ='indexed view logbased', @pre_creation_cmd = N'truncate' GO EXEC sys.sp_addarticle @publication = N'test', @article = N'art_ReplNoPkUnique', @source_owner = N'indviews', @source_object = N'vw_ReplNoPkUnique', @destination_owner = N'dbo', @destination_table = N'_ReplNoPkUnique', @type ='indexed view logbased', @pre_creation_cmd = N'truncate' GO
The next 2 steps are adding the snapshot agent and adding the subscription:
-- adding the snapshot agent EXEC sys.sp_addpublication_snapshot @publication = N'test', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0, @frequency_subday = 0, @frequency_subday_interval = 0, @active_end_time_of_day = 235959, @active_end_date = 0,@publisher_security_mode = 1 GO -- adding the subscription EXEC sys.sp_addsubscription @publication = N'test', @subscriber = N'SQLSERVER1', @destination_db = N'_DemoDB_Subscriber' GO
The last step will be to copy or move our reporting view to the subscription database:
USE [_DemoDB_Subscriber]
GO
CREATE VIEW dbo.[_vw_Report_1]
AS
SELECT c.c1, c.c2, u.c2 AS u_c2
FROM dbo._ReplNoPkClust c JOIN
dbo._ReplNoPkUnique u ON c.c1 = u.c1
GO
We now have a workaround for replication of tables without primary keys.
Note, that you should understand your data and be careful not to break the application when you create unique clustered indexes on the indexed views. In our case, all tables had either a clustered index or unique nonclustered index.
Disadvantages of using Materialized Views with Replication
One of the disadvantages of using materialized views with replication might be:
When executing DML1 on a table referenced by a large number of indexed views, or fewer but very complex indexed views, those referenced indexed views will have to be updated as well. As a result, DML query performance can degrade significantly, or in some cases, a query plan cannot even be produced. In such scenarios, test your DML queries before production use, analyze the query plan and tune/simplify the DML statement.
Note, that the note above talks about a "large number of indexed views" per table or "complex indexed views".
As we use a single indexed view per table and it is very simple (it selects columns from one table only) we do not worry about significant performance impact. It's always good though to test it in your environment, especially when you replicate tables that have a very high number of transactions. Some applications may hold a lock where you don't expect it. So, test-test-test.
Another disadvantage is that in case you need to make changes to the source tables, you may have to perform specific steps (depending on the nature of changes). So, for an application that has frequent schema changes, this might be quite a cumbersome process.
Some of the schema changes related issues you may have are:
Updating a column's data type:
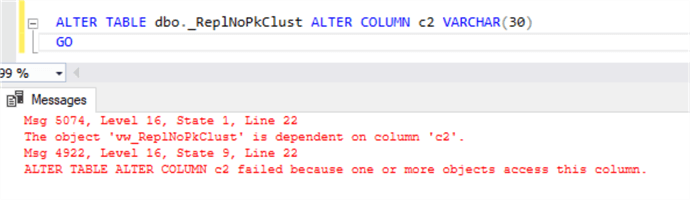
Adding the new column to the table and view. Note, that if you can add the new column to the table, but if you want to replicate it you will need to update the indexed view as well:
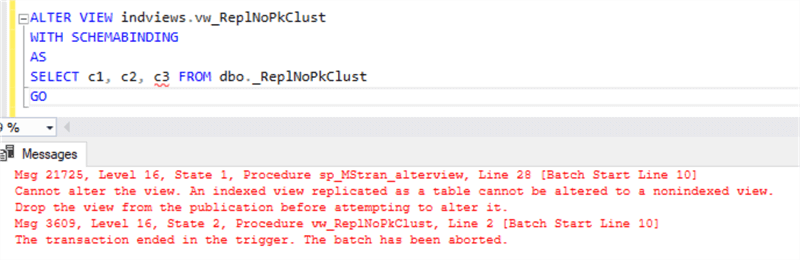
In both cases, you need to drop the replication article to make the changes, and in the case with the data type change, you need to drop the indexed views as well. Make sure you can afford replication re-initialization (it may take some time and you may have tables lock during a snapshot creation).
So, the steps for the database schema change (depending on the kind of the change) might be as follows:
Remove the subscription for an article that references view/table that required the schema change
- Drop the replication article
- Drop an indexed view that references the table that will be altered
- Make changes to the table
- Re-create the indexed view
- Re-create the replication article
- Re-initialize the subscription for the article
Keep this in mind and have your change procedure in place to make sure you can successfully upgrade your application. It's always good to have a replication setup in your test environment as well, so you can validate all steps for your source table changes.
Please note that this tip doesn't cover other aspects of replication (such as security, specific replication options, availability groups setup, etc.). This tip demonstrates a workaround for replicating the tables that don't have primary keys.
Next Steps
- Read more tips about replication here.
- Check this tutorial for preparing the server for replication.
- Read this article about replication security best practices.
- Find out about Azure Managed instance transactional replication here.






About the author
 Svetlana Golovko is a DBA with 13 years of the IT experience (including SQL Server and Oracle) with main focus on performance.
Svetlana Golovko is a DBA with 13 years of the IT experience (including SQL Server and Oracle) with main focus on performance. This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
