By: Koen Verbeeck | Updated: 2022-07-20 | Comments | Related: 1 | 2 | 3 | 4 | More > Professional Development Interview Questions Developer
Problem
I have an interview soon for a position as an ETL developer using the Microsoft Data Platform. What are the kind of technical questions I can expect?
Solution
The questions featured in this tip are questions the author would ask if he would be the interviewer, but some questions also come from actual interviews. If you know of other interesting questions, feel free to add them in the comments.
Interview Questions
What is ETL?
ETL is the process where we Extract data from one or more sources, then Transform the data, and finally Load it into a destination. The transformation step can take many forms: you might be cleaning up some data, removing duplicates or NULL values, or you can apply business logic to the data. For example, you might need to calculate the profit margin from the unit price, the quantity, and the production cost.

Loading the data can be done into a variety of data stores, such as relational databases like SQL Server or Azure SQL Database, but also a data lake such as Azure Data Lake Storage or a Delta Lake in Azure Databricks. ETL is commonly needed in data warehouse projects, but you can also build data pipelines for data migration/integration projects. About any process that extracts data, transforms and loads it into a destination can be considered an ETL process.
Typically, on-premises ETL development is done using Integration Services (SSIS), while development in the cloud is done using Azure Data Factory (ADF).
In typical data warehousing projects, building the ETL can take somewhere between 60% and 80% of all development effort, and should thus not be underestimated. For more information, check out the tip ETL to Extract, Transform and Load Data for Business Intelligence.
What is ELT and when would you use it?
ELT is a variation on the traditional ETL process (see question above). Instead of transforming the data on-the-fly before loading the data into the destination, it’s rather stored as-is from the source in a persistence layer. Then, you can choose your desired compute to handle the transformations. ELT is popular in cloud scenarios because it typically scales better than ETL. For example, sorting and aggregating data has better performance in SQL than in an SSIS data flow because those transformations need the data to be loaded entirely into memory. So, if you have performance issues in your data flows because of memory constraints, it might be a good idea to switch to an ELT pattern.
To implement ELT data pipelines, you can use the following tools:
- SSIS. You extract and load the data within a data flow. Then you execute SQL scripts using the Execute SQL Task.
- ADF. Extracting and loading is done using the Copy Data activity. Once the data is persisted, you can execute SQL using the Script activity (like in SSIS), or use other forms of compute like Azure Functions, Azure Databricks notebooks and so on.
- Azure Databricks. You can write notebooks in Scala, R or Python to extract and load data into a data lake. Then you can use the same languages and even SQL to transform the data.
For more information, check out the tip What is ELT for SQL Server?.
Full load or incremental load?
Early in the ETL design process, you must decide if you’re going to load data incrementally, or if you’re going to load all the data at each run of the process. Sometimes, you don’t have a choice: if there’s no method to determine which rows have changed or added in the source, you need to extract the full data set. Loading incrementally has the obvious advantage that it is much faster; you’re only processing a small subset of the data. This can important if you want a real-time or near-real-time ETL process. However, it’s harder to implement, more difficult to debug and you might need to develop a separate flow to handle the initial load.
Full loads, on the other hand, are easier to implement and easy to troubleshoot but since you’re dealing with the full data set you might encounter performance issues. Modern data platforms can now handle multi-million row inserts with ease, so performance might not be an issue for small and medium size data sets.
An option might be that you initially develop the ETL load as a full load to make speed, but that you put a potential incremental load in the backlog as technical debt. If the need arises, you can switch to an incremental load.
How can you save on costs when building ETL in the cloud?
There are a couple of guidelines you can consider when using cloud services:
- Check the regions. If you have multiple Azure regions nearby, compare prices between them. Not all regions have the same prices.
- Verify if you are eligible for the Azure hybrid benefit. This means you already have a SQL Server license, which you can just reuse in Azure. This can lead up to huge cost savings, for example when creating an Azure-SSIS IR:
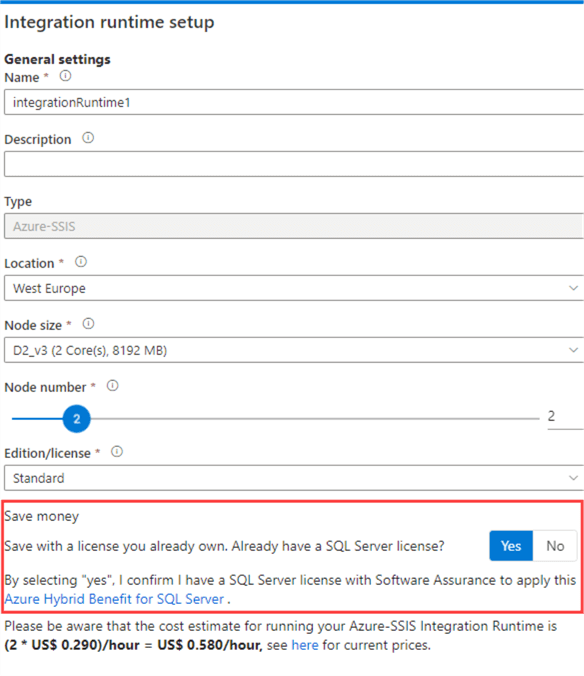
- If applicable, check if you actually need Enterprise edition. In SSIS, for most use cases a Standard edition is just fine (see also the screenshot above).
- If you don’t need it, pause it. For many cloud services, like Azure Synapse Analytics Dedicated SQL Pools or Azure Databricks, you can pause the service. This will save you money. Not everything can be paused, like an Azure SQL DB (unless you’re using the serverless tier), but you can scale the service down. You can for example scale the database up when the ETL is running and when the models are refreshing (Analysis Services or Power BI), but when the database is doing nothing, you can scale it back down to save costs.
- Storage is cheap, compute isn’t. If you’re dealing with big data, it’s cheaper to store the data in a data lake instead of in a database. In a data lake, you can choose the compute that best fits your needs.
- Some options of compute are cheaper than others. The Copy Data activity can be expensive when you need to run a lot of small iterations (since you’re billed for every minute started). In such cases, it might be a better idea to replace the Copy Data activity with an Azure Function or an Azure Logic App. An example is given in the blog post How you can save up to 80% on Azure Data Factory pricing.
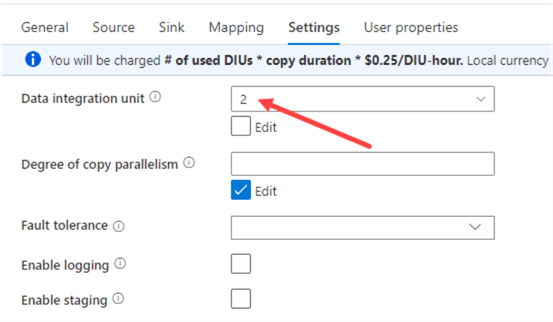
- In ADF, if you’re dealing with small or medium data sets, change the DIU size of the Copy Activity to 2. The default is Auto, which will take 4 as a minimum. By changing this setting, you automatically save 50% on your Copy Data activity cost.
Next Steps
- Do you know more ETL-related interview questions? Feel free to post them in the comments!
- Stay tuned for more tips with ETL interview questions!
- For more info about ELT, check out the tip ETL vs ELT Features and Use Cases as well.
- You can find more info about technical interviews in the tip 7 Ways to Prepare for a Technical Interview and the webcast Interview Coaching for SQL Server Professionals.






About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2022-07-20
