Problem
Our organization has become highly dependent on Power BI for our reporting and decision making. These tools have become our reporting tools of choice for our reporting teams and end users. We can easily build, manage and distribute reports across our departments, projects and our partner networks comprising our enterprise data. Unfortunately, we have been experiencing issues with inconsistent data among departments. Further we have challenges combining data and accurately report on key projects.
Solution
Recently, we uncovered the root cause of our reporting issues: poor data quality for portions of our data. Some data is out of date, while other data is not formatted consistently based on numerous source systems. We even have particular data does not properly match across reports and data integrity issues.
Now our reporting teams and end users are in a position where they need to run manual processes to “fix the data” on a regular basis. However, writing custom reports with “bad data” is time and resource draining. We have reports that will never be accurate for business decisions. How can we improve the quality of our data to have confidence in our reports?
Cost of Poor Data Quality
Poor quality data for any reason is very expensive in terms of man hours and decision making to all organizations. There are a number of ways to address the issue in the real-world with both SSRS and Power BI.
- First, with Power BI you can use Power Query to load data in the application. At that point we can write code to standardize data. But you may not have complete confidence in the validity of the data. Also, this validation logic will need to be duplicated for each report.
- Second, Power BI also has the ability to check for anomalies and use filters. This enables the exclusion of data from the data set. However, this can result in hard coded data outside of the norm. We are concerned this will get lost over time as the environment changes.
- Third, the data can be queried and loaded into a temporary table or even into Excel to “fix the data” then run the reports against the modified data with Reporting Services or Power BI. This process is generally against many corporate policies and complicates the ability to combine data and match data across departments and projects.
Data Quality Needs
What is really needed is to get ahead of data quality issues before data consumers reporting on the data begin analysis regardless of the reporting tool. With one version of the truth for all reports, there will be consistency when reporting across departments, projects and with partners. This solves one piece of the puzzle, but there is still a need for data validation and data cleansing to ensure accurate, trusted data. Most organizations on the Microsoft Data Platform use SQL Server Integration Services (SSIS) or Azure Data Factory (ADF) to extract, transform and load data. However, data validation and cleansing is not native functionality and much of the scripting needed for basic parsing is not intuitive requiring significant programming knowledge.
Melissa Data Quality Components
To address this need, one solution that I would like to introduce is Melissa’s Data Quality Components for SSIS. Melissa’s solution integrates directly with SSIS which is a familiar tool to SQL Server DBAs, Developers Business Intelligence Professionals and Data Stewards.
Here is how Melissa’s Data Quality tools can help you:

Melissa’s solution delivers:
- Seamless integration in SQL Server Integration Services to easily improve existing business data workflows
- Low learning curve for SQL Server DBAs, Developers, Business Intelligence Professionals and Data Stewards to properly validate and cleanse business critical data based on business rules, data governance and regulatory compliance
- Data profiling, cleansing, validation, remediation and enrichment for names, address, email address, phone numbers and more resulting in data completeness
- On premises and cloud-based solutions to support a variety of application use cases (healthcare, CRM, marketing, mailing, etc.)
- CASS Certified (USA based mailings) and SOA Certified (Canada based mailings) Software – Melissa will not only correct syntax and format the data with deep domain-based knowledge, but mark each record as valid
- Data-driven result codes for each data record to determine how the data was changed, the level of validity for the data, identify the error, and more
Let’s dive in and check out how Melissa’s solution can help organizations.
Melissa Data Quality Management with SSIS
To begin working with the Melissa Data Quality Components for SSIS, start by defining the source and destination of your data. Then in this example, on the SSIS Data Flow task we will drag and drop the MD Contact Verify component from the SSIS Toolbox. The Melissa Contact Verify interface validates and corrects the following customer data:
- Name
- Address
- Phone
This enables SQL Server Professionals to easily validate business critical data within a familiar toolset ensuring the organization has the best data quality for decision making. The data quality components have a user friendly interface that makes this seemingly complicate process simple. Let’s walk through the process step by step.

Name Verification
When we double click on the Contact Verify Task, we can begin to configure our source and destination mappings. In the first example related to Name parsing, the FullName input can be parsed into 14 Melissa components with the “MD_” prefix including splitting two names such as “Tom and Mary Smith” into their respective output columns. The Name service can also add gender to names and develop salutation titles for mailing purposes which is derived new data. There is some custom ability available via the Name configuration file, which allows you to override the default settings, and to add, remove or edit names from the compiled list, allowing you to fine tune processing behavior to suit your data standardization rules.

Address Verification
The Address Verification in Melissa’s Contact Verify component is very similar in formatting to the Name component. Contact Verify can process US and Canadian addresses. With Address Verification, Melissa guarantees CASS Certified data to reduce the USPS mailing costs. Contact Verify can also generate the USPS CASS Summary Report for US addresses. As well as the SOA form for Canadian addresses. The address data can be further improved on the GeoCode tab to by appending Latitude and Longitude with rooftop level accuracy with the results from the Address Verification for US address only. Canada GeoCode is available to the postal code level.

Phone and Email Validation
The Phone/Email tab enables validation and standardization of both sets of data. For Phone processing, the options are available to output format desired. As well as to parse the phone data into their respective fields.

Further, by clicking on the “Standardization Options & Additional Output Columns…” button, Melissa provides additional standardization, lookups, verification and output to ensure the email address data is valuable for correspondences, customer service and marketing.

Contact Verify offers Mailbox Verification Premium Mode for real time, live, validation of email address by using domain specific logic and SMTP commands to validate email boxes. Other options for Contact Verify email include correcting email syntax for illegal characters and misspelled domain names, DNS lookup to validate email addresses by locating an MX Mail Exchange for the domain, and fuzzy lookup to try and validate the email address by applying fuzzy matching algorithms to the domain.
Data Survivorship and Lineage
Another valuable feature with the Melissa Contact Verify component is the ability to retain the original values for the final data set in order to compare with your source system. As an example, you can pass a Primary Key from your source system to the final data set in order to tie back to updated data to the original source system.

Metadata Reporting
On a per record basis, Melissa includes extensive error handling to mark the success, updates (splitting names, updating names, etc.) and errors in order to know all of the actions to take per row. With the Output Filter Expression interface, you have the ability to browse and update the final Melissa reports to efficiently troubleshoot your data set.

Execute the SSIS Package with the Contact Verify Logic
Once you have completed configuring the Contact Verify interface in SSIS, simply run the package to cleanse the name, address, phone and email data.

In this sample SSIS Package we have included a Data Viewer to review the output. As you can see the update Melissa data includes an “MD_” prefix, followed by the original data and finally the result codes on a per row basis in the MD_Results column.

What about international data validation?
Global Verify is another SSIS component from Melissa that follows the same process as Contact Verify for United States based data. But with International addresses, Melissa covers 240 countries around the globe. This component is able to output the final results in Latin or native formats, depending on the needs. Furthermore, Melissa offers Live validation for both Phone and Email. This can ensure that your marketing campaigns see less bounce backs or disconnected phone numbers. Global Verify is being constantly enhanced by Melissa for both the on-premises and web service editions. The on-premises version is updated quarterly and updates to the web service are regularly deployed.
SQL Server Data Appending and Corrections with Melissa’s Personator
Poor data quality includes incomplete data sets which complicates reporting in SQL Server Reporting Services and Power BI. Often times there is a need to validate data based on a single column. This could be name, email, phone, address or social security number. This is where another valuable Melissa solution called Personator provides tremendous value. Personator can be dragged and dropped directly from the SSIS Toolbox into the palette of the Data Flow task. Next, append, validate and correct data based on the available data in your system including name, address, phone, email, social security number, etc.
The Melissa configuration interface is similar to completing the process with Contact Verify (as previously shown). For brevity, in the image below we highlight the differences in the interface. Including defining the input data to use as the basis for data appending as well as the appending options including Check, Verify, Move and Append. Options are based on subscription. The final results for the Verification and Appending are determined based on a column selection. This includes Auto, Social Security, Phone, Email or Name, which is used as a pivot point when enriching the data.

At this point you can configure the Output, Pass-Through Columns and Output Filter tabs. This is similar to the Contact Verify interface. Once completed, simply run the SSIS Package to have your data appended or updated to improve the data accuracy. Personator also includes additional data. Such as birth date, date of death, gender, marital status, children, length at residence, household income, etc. This can provide new insights into the existing data set.
SQL Server Data De-Duplication with Matchup from Melissa
Often times identifying duplicate data is difficult. Knowing that “John Smith”, “John R. Smith” and “John Robert Smith, JR.” are the same person is not a simple string match. This type of discrepancy can easily skew reports yielding poor decision making. This is where a third component from Melissa comes into play – MatchUp. This component is for data matching, de-duplication, linking and identification of the golden (accurate) record within the data set using special techniques. The techniques include:
- Last Updated: Will choose the record with the most recent date in the date field(requires date field)
- Most Complete: Will choose the record with the most complete data by specifying a field to use as a focal point
- Data Quality Score: Selects the record based on the quality of your data gathered by Melissa’s Address, Name, Phone, Email, Geocode services or overall Data Quality Score
- Custom Expression: Develop custom expressions based on deduping requirements
SSIS Functionality for MatchUp
MatchUp has the same integration with SQL Server Integration Services as the prior two components. For brevity, we will only cover differences. MatchUp relies on Matchcodes values which are a set of columns to determine duplicates within a data set. There are 25+ Matchcode options out of the box. These include address, international address, name, fuzzy matching and more, as shown below. You also have the ability to customize the Matchcode options for your unique needs.

Once the Matchcode option is selected then Field Mapping is determined between the Matchcode data type and the input fields as shown below.
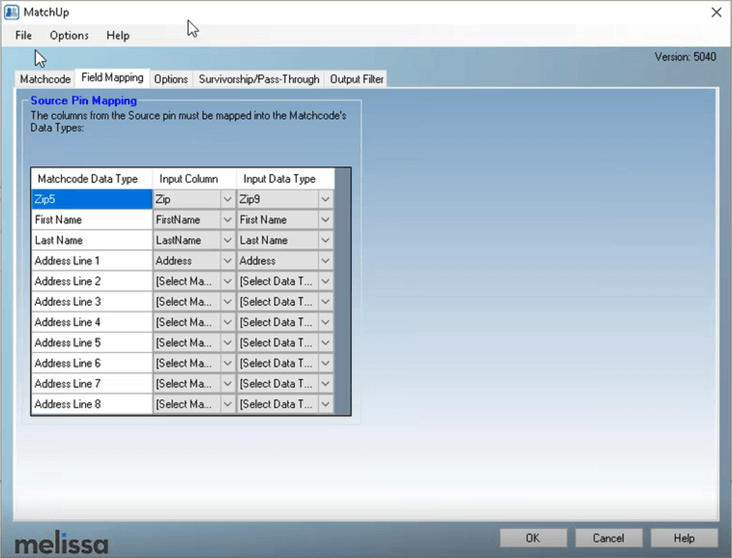
The final MatchUp configurations are related to the Duplicate Count, Duplicate Group and MatchcodeKey values after the data has been analyzed. Based on these results, the Golden Record is determined as the best record from the Duplicate Group which could be based on the most recently updated date, best data quality score, most complete record or a custom expression, with the ability to configure each of these options. If a lookup source is provided, MatchUp can use that data source as a filter.
MatchUp Lookup Options
MatchUp provides the following lookup options:
- List Suppress:
- The source records that match any record from the Lookup will be marked as Suppressed
- List Intersect:
- Only Source records that match any record from the Lookup will be returned with an Output Result Code (Unique or Has Duplicate result code). The second to nth Source records that match the Lookup record will be marked with a Duplicate Result Code. Source pin records that do not match any Lookup pin records will be returned with a Non-Intersected Result Code.
- No Purge:
- Source records that match other Source records will not be matched. In other words, a suppressed group or an intersected group will be returned as suppressed or intersected, but each record will have their own Dupe Group number.

Once the analysis is complete, we can see the three sets of duplicates from the sample output below. The data groupings are sorted together and each row is uniquely identified in the group based on the MD_MatchcodeKey which specifies the logic used to analyze the record.
MatchUp also includes Survivorship techniques to avoid losing critical data amongst a set of duplicates by merging data into a single output.
Advanced Survivorship Techniques
- Prioritize Critical Data
- First Data: Selects the first piece of data from the specified column
- First Non Empty: Selects the first piece of data that is not null
- Most Frequent: Selects the piece of data that appears most frequent
- Retain Data
- Join: Joins data together from the specified field
- Join with spaces: Joins data together delimited by spaces
- Stack Groups: Make new individual output fields for the data from the duplicates
- Perform Math Functions
- Add: Will add the contents of the specified field
- Average: Will return the average of the contents of the specified field

How can Melissa help my organization?
Change is constant. Data is always changing – becoming stale, outdated and inaccurate. Melissa’s Data Quality Components for SSIS enable SQL Server Professionals to provide their organization with high quality data for reporting and decision-making purposes including:
- Validation– Ensure data accuracy
- Appending– Update missing data components for a complete data set
- Matching– Match data among various systems
- Parsing – Carving out individual data components
- Standardization – Data consistency based on your needs
- De-duplication – Identify duplicates and determine the most accurate record
- Business Critical Data – Name, Address, Phone, Email Address, etc. in the United States and 240 countries
- Intuitive Toolset – Simple wizard-based interface
- Live Validation – Mailbox level Email validation and live Phone validation
- Seamless Integration – Simple installation with drag and drop functionality directly in Integration Services
- Time Savings – Easily improve the quality of your data with existing business processes
How do I get started with Melissa’s Data Quality Components for SSIS?
- Think about the frustration trying to report on inaccurate and incomplete data as well as the impact to your organization to make proper decisions.
- Learn more about all Melissa’s Data Quality Components for SSIS will do to help your organization.
- Download your personal evaluation version of Melissa’s Data Quality Components for SSIS.
- Schedule a personal demo of Melissa’s Data Quality Components for SSIS with a member of the Melissa team and then put the tool through its paces in your environment with your data. See how easy it is to improve the data quality at your organization.
- Communicate how Melissa’s Data Quality Components for SSIS can help your organization:
- Time savings for data validation and cleansing
- Seamless integration into existing SSIS Processes
- Significant functionality out of the box with the ability to customize as needed
- Radically improved data quality for reporting and decision making
- Move from poor to good data quality
- After working with Melissa’s Data Quality Components for SSIS, measure the tangible and intangible benefits to your reporting processes and determine your next steps to radically improve the decision making in your organization.
Next Steps
- Learn about the value of Melissa’s Data Quality Components for SSIS.
- Get a personal demo of Melissa’s Data Quality Components for SSIS.
- Download Melissa’s Data Quality Components for SSIS.
- Check out these webinars:
MSSQLTips.com Product Spotlight sponsored by Melissa, makers of Data Quality Components for SSIS.

Jeremy Kadlec is a Founder, Editor and Author at MSSQLTips.com with more than 300 contributions and 25+ years of SQL Server experience. Jeremy leads a team of more than 300 authors helping millions of SQL Server professionals around the globe every second of the day for the last 20 years. He is also the CTO @ Edgewood Solutions and a six-time SQL Server MVP based on his community contributions. Jeremy brings 25+ years of SQL Server DBA and Developer knowledge to the community and holds a bachelor’s degree from SSU and master’s degree from UMBC.



Appreciating the commitment you put into your website and in depth information you provide.
It’s awesome to come across a blog every once in a while that isn’t the same unwanted rehashed information. Great read!
I’ve saved your site and I’m including your RSS feeds to my Google account.