By: Koen Verbeeck | Updated: 2023-07-20 | Comments (2) | Related: More > Snowflake
Problem
We want to analyze the data in our Snowflake data warehouse on our cloud data platform. However, not all of our users have SQL knowledge, so they cannot query the database directly. We want to implement a semantic model between the Snowflake database and the front-end tooling for our business intelligence solution. This would allow users to build reports quickly by just dragging and dropping fields. The data in Snowflake is too big to be imported into a model and Analysis Services Tabular doesn't support DirectQuery on top of Snowflake. How can we resolve this data access issue?
Solution
Snowflake is a software-as-a-service provider that offers a cloud-native data warehouse solution on both Microsoft Azure and Amazon AWS. In Snowflake, you can build your own data lake and data warehouse in the same solution. You don't need separate "big-data" technologies to analyze terabytes of data. However, not all users have the SQL knowledge to query the data directly in Snowflake. To resolve this issue, a semantic model is typically built on top of the data warehouse. In the Microsoft SQL Server Data Platform, this semantic layer is an Analysis Services (SSAS) model: either SSAS Multidimensional or Tabular Model, or a Power BI model (or even a PowerPivot model in Excel). Such a semantic layer allows the user to connect to the model, without the need of having any technical knowledge of the database. Reports or pivot tables can be created with ease by just dragging and dropping fields onto a canvas to build the visualizations.
The following screenshot is an example of such a pivot table on top of a semantic model:
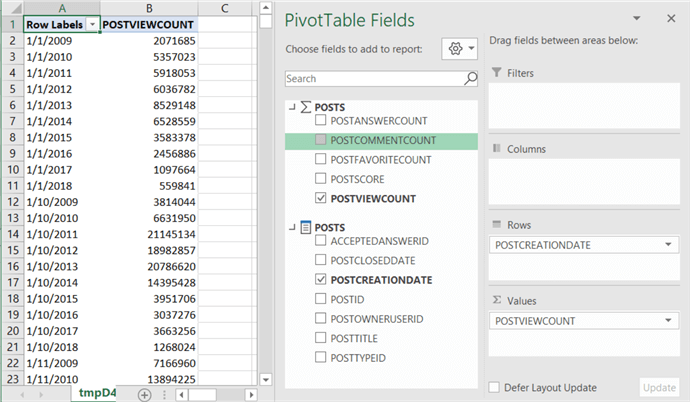
Most SSAS models allow you to import the data into the model. This gives better performance as data can be pre-aggregated (in the case of SSAS Multidimensional) or stored in memory in a highly compressed format (in the case of SSAS Tabular and Power BI). But sometimes, the data is just too large to be imported, there's either not enough storage or memory, or refreshes take too long. To solve this, you can connect the model live to the underlying database. The semantic layer is just a shell translating commands into SQL behind the scenes. In Tabular or in Power BI, this is called DirectQuery. Power BI has functionality for a native connector to Snowflake, but Tabular, on the other hand does not: it doesn't support Snowflake as a DirectQuery source.
What if you want to connect live to Snowflake, but don't have Power BI available? Luckily with the CData ADO.NET adaptor for Snowflake and SSAS Multidimensional, we can create a solution where users can connect live to Snowflake without the need for importing data. In this tutorial, we'll guide you on how to build a real-time data analytics solution.
Connect Live to Snowflake with SSAS Multidimensional
Install the CData ADO.NET Adaptor
Before we start in SSAS, we need to install the provider first. You can download a free trial from the CData website. The set-up is straight forward.
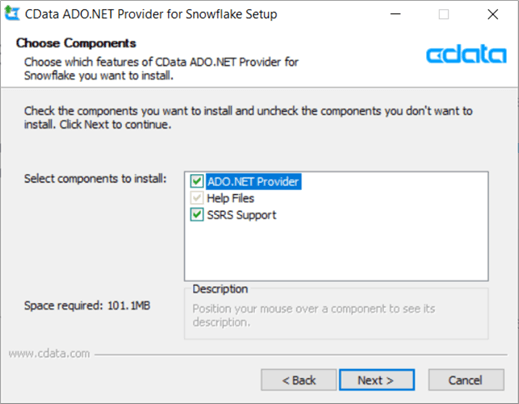
You have to accept the license, configure an install location and then choose which components you want to install:
You can choose a start menu folder and optionally integrate the product into Visual Studio:
Since it's a trial, you need to register with at least your name and e-mail address:
Hit Next until the wizard starts the installation.
Hit Finish to close the wizard. And that's it! The provider can now be used with the different products of the Microsoft Data Platform on your machine: SQL Server Integration Services (SSIS), SQL Server Analysis Services (SSAS) and SQL Server Reporting Services (SSRS).
Create a Sample SSAS Cube with the CData Provider
To familiarize yourself Snowflake, you can go through the Snowflake tutorial. An in-detail introduction on how to create dimensions and cubes in SSAS Multidimensional is out of scope for this tip, but you can learn the basics in the SSAS tutorial. You can also find a short instructional video on how to use CData in SSAS on YouTube.
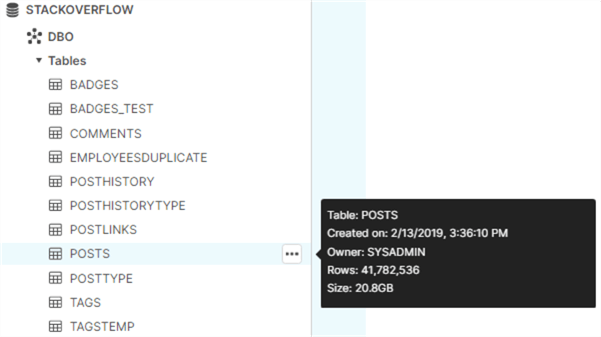
We're going to build a small cube on top of a Snowflake data warehouse. I've uploaded the open-source data set of StackOverflow into a Snowflake database. In our example, we're going to use the Posts table, which has about 41 million rows and is 20.8GB in size. Definitely too big to be imported into Visual Studio on my machine.
The first step is to create a new data source connection.
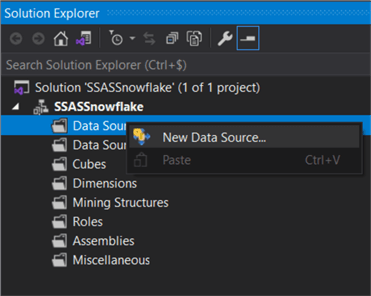
From the providers dropdown, choose the CData ADO.NET provider for Snowflake. It should be listed under .NET Providers.
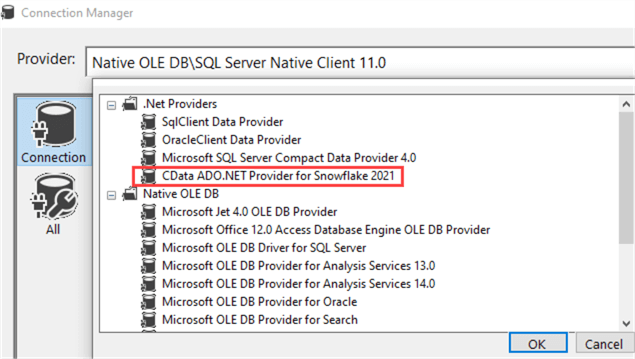
CData regularly updates the provider, which is why there's a time indicator at the end of the name. In the screenshot, it's 2021. You'll be taken to the properties page, where you need to fill in information such as username, password, the name of the warehouse (this is the compute engine, not the database itself!) and the URL to your Snowflake account for the connection string.
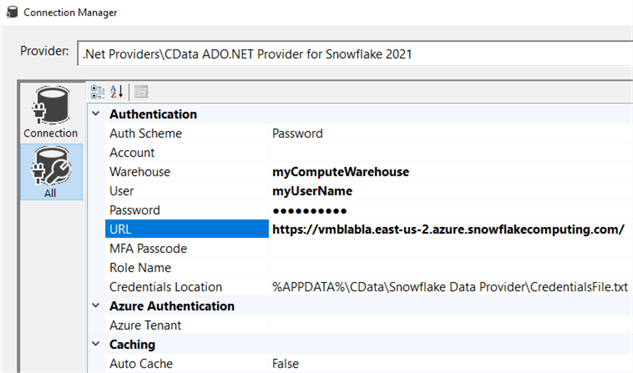
You can also specify the database and the schema:
At the end of the wizard, set the impersonation information to Inherit. Next, we're going to create a data source view. After selecting our Snowflake data source, SSAS will retrieve all metadata information of the Snowflake database. You can monitor this in the Snowflake query history:
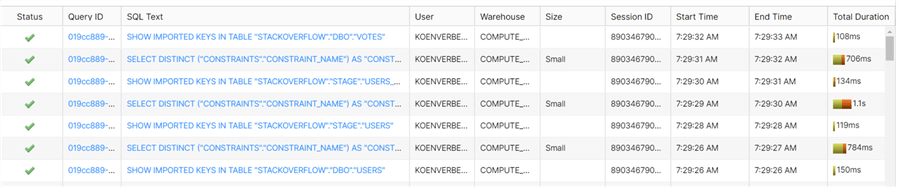
Depending on the number of objects in your database, this can take a while. In this example, we only select the Posts table.
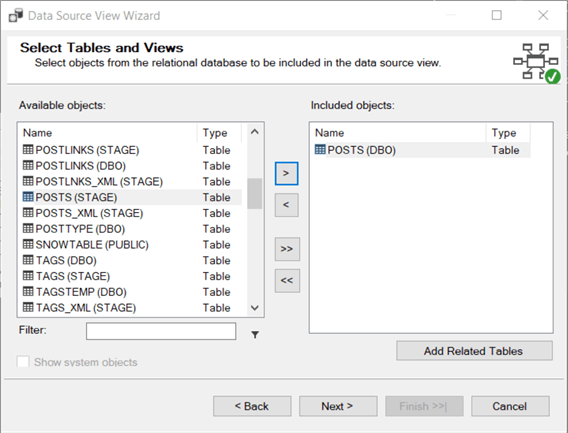
Now we will add a cube into the project.
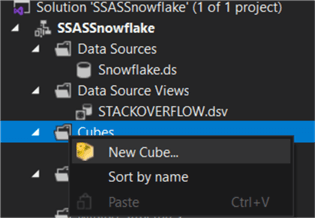
The Posts table is selected as the source for our measure group:
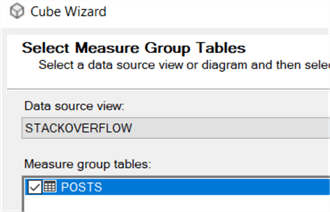
StackOverflow keeps track of different counts, as well as the score of the post. These will be our measures. The last count is automatically added by SSAS and is the row count of the table.
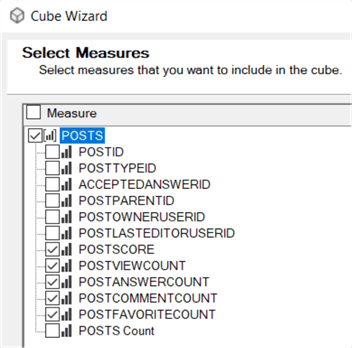
We will create a dimension on top of the Posts table as well:
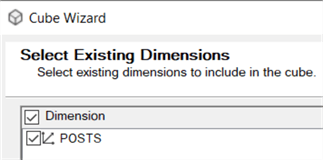
The PostID is the key column of the dimension. The Posts cube and dimension are now created and added to the project. In the dimension editor, we've added some columns to the attributes.
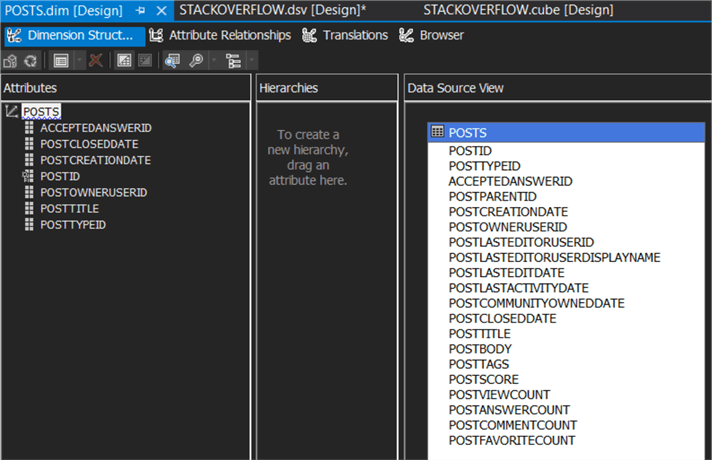
Configure the Cube to go Live
The dimension and the cube are finished, but by default SSAS will import all of the data when you process the cube. We rather want the data to stay where it is. We can do this by setting the storage options to ROLAP, which stands for Relational OLAP (Online Analytical Processing). In the cube editor, go to the partitions tab. For each partition, you can configure the storage mode. Select a partition and click on Storage Settings.
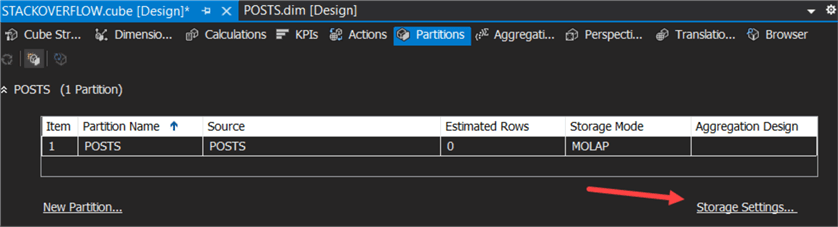
You can see the default storage mode is MOLAP, which is short for Multidimensional OLAP (Online Analytical Processing).
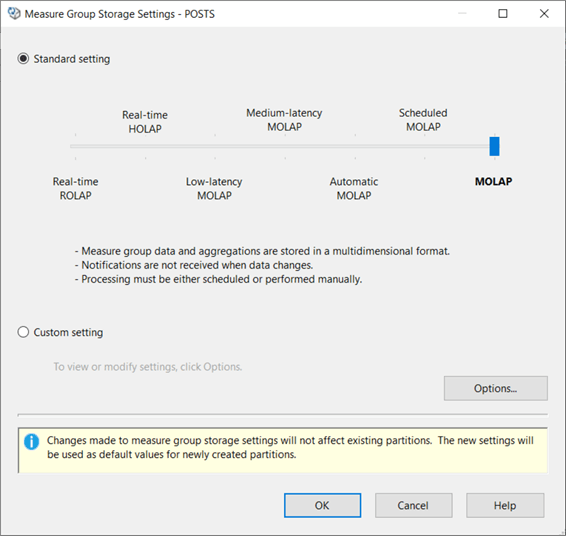
As you can see, there are many different storage options, offering all kinds of hybrids between MOLAP (everything is read onto disk) and ROLAP (everything stays at the source database). For more information, check out the documentation. Slide the slider all the way to the left. A warning will be displayed at the bottom:

When using SQL Server, SSAS will use notifications to detect if the cache is outdated. Since we're using Snowflake, this is not an option. We can change this configuration by going to Options. Simply disable the checkbox for proactive caching.
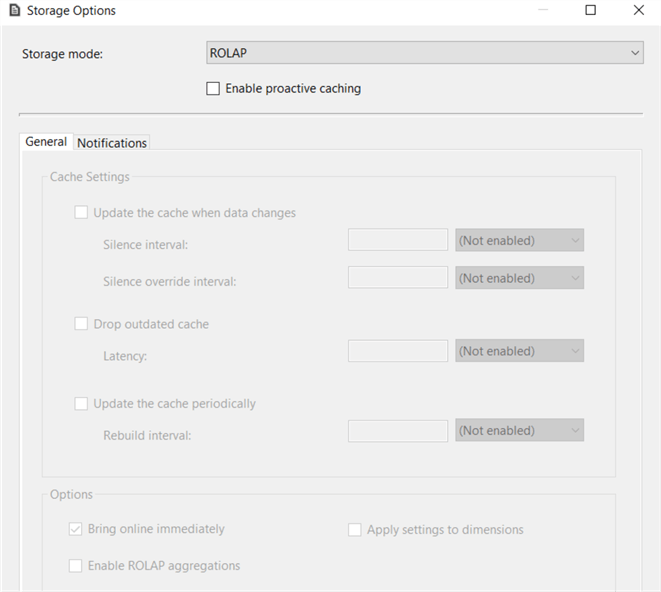
The fact data will now be fetched live from Snowflake, but we need to configure the dimension as well. There's no partition tab in the dimension editor. In the properties pane, we can find the StorageMode under the Storage section:
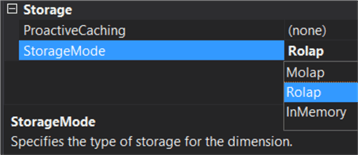
By setting it to ROLAP, we've also configured our dimension to use live data from Snowflake. We can now deploy and process the cube, which should be fast since no data is actually being transferred.
Querying the Cube
Now it's time to test our solution. You could look at the members of an attribute in the dimension browser. For example, the Post Type ID attribute:
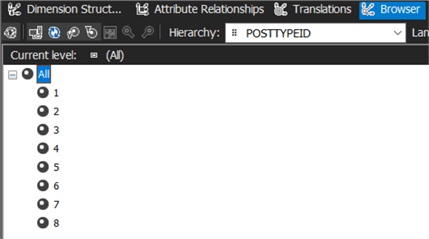
In the Snowflake query history, we can indeed see a SQL query was issued to retrieve the distinct post type IDs from the Posts table. 8 rows are returned:
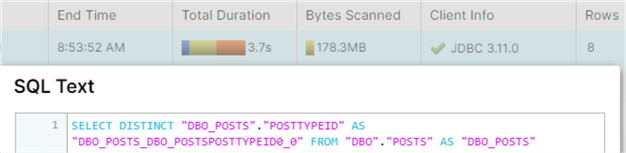
In the cube browser, we can click on the Excel item to open an Excel Workbook containing a pivot table connected to our cube:
There we can start an analysis of the data by just dragging and dropping members of the field list.
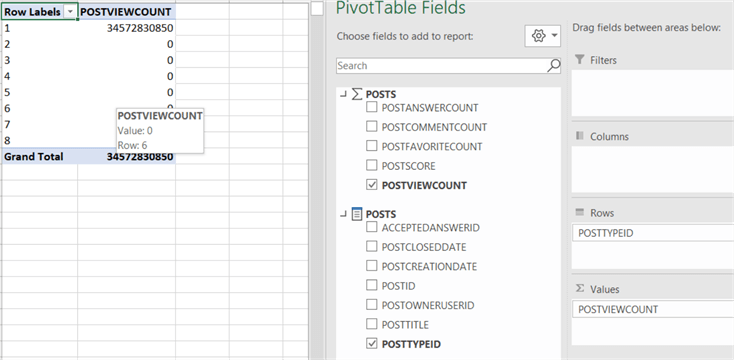
Again, we can see the query in Snowflake:
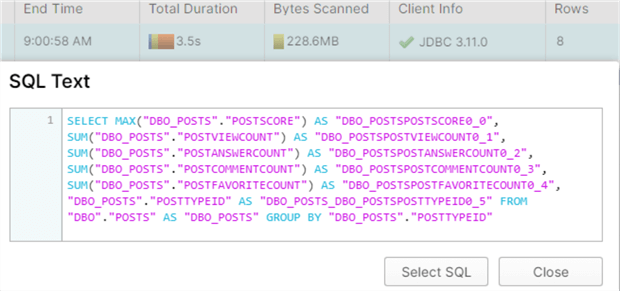
Typically, SSAS will fetch all measures of the measure group in the same query. When you add another measure to the pivot table, the results will be almost instantaneous since SSAS has cached the result. Keep in mind Snowflake has a result set cache of its own, meaning you can see tremendous performance improvements when a query hits the cache.
Something to be aware of is that Snowflake can house terabytes of data and can return results quite quickly. But the front-end tool doesn't always accommodate this. For example, a pivot table of post type on the rows and creation date on the columns results in a query returning 41.8 million rows.
Snowflake returns the data in 8 seconds, but the data is not grouped. SSAS didn't ask for an aggregated result set, but rather asked for the raw data itself:

Even though Snowflake returns the results quickly, SSAS can't process all the data in a timely fashion and Excel cannot display that many rows. You can avoid scenarios like this by not creating high-cardinality dimensions. In our sample set-up, the Posts dimension has the same number of rows as the Posts fact table.
Conclusion
In this tutorial, we showed you how to use the CData ADO.NET provider for Snowflake to set up a connection to Snowflake in an Analysis Services Multidimensional project. You can configure SSAS to use ROLAP, which implies that queries against the cube are translated to SQL and sent to Snowflake. By using ROLAP, you can create live reports on top of the Snowflake data warehouse. Any tool that can connect to SSAS can now connect live to Snowflake.
Keep in mind, if the size of the database in Snowflake is manageable, you can import the data into SSAS to get the full benefits of an OLAP cube.
How do I get started with CData?
Getting started with the CData ADO.NET Provider for Snowflake is as easy as downloading a free, 30-day trial. You can read more about all of the CData Snowflake connectivity solutions, APIs and see sample integration guides and data connectivity tutorials on the CData website for on-premises and cloud technologies. With CData Software's connectivity solutions, you gain pure SQL access to your Snowflake data warehouses in virtually every Business Intelligence (Data Mining \ Data Analysis, MDX, Analytics, AL, ML, etc.), reporting (Power BI, SSRS, SharePoint, Excel, etc.), and ETL tool (SSIS), platform (SQL Server database, Oracle, additional relational databases, etc.), and application (SAP, SalesForce, CRM, HR, etc.).
Next Steps
- More information about CData:
- For more information about live connection in SSAS:
MSSQLTips.com Product Spotlight sponsored by CData.
About the author
 Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.
Koen Verbeeck is a seasoned business intelligence consultant at AE. He has over a decade of experience with the Microsoft Data Platform in numerous industries. He holds several certifications and is a prolific writer contributing content about SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at PASS, SQLBits, dataMinds Connect and delivers webinars on MSSQLTips.com. Koen has been awarded the Microsoft MVP data platform award for many years.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-07-20
