By: John Miner | Updated: 2023-07-20 | Comments | Related: More > Import and Export
Problem
Today, many companies have existing computer systems that reside within their brick-and-mortar (on-premises) data centers. The Salesforce application (in-cloud) has become very popular Customer Relationship Management (CRM) system with many Sales departments. How can we add real time, bidirectional connectivity between Salesforce and SQL Server?
Solution
CData has developed several ways to move data between a Salesforce application and SQL Server database. These components have been bundled together into a product called DBAmp. DBAmp enables SQL Server professionals to:
- Seamlessly read and write Salesforce data from SQL Server
- Use 4 part naming convention in SQL Server with OPENQUERY to access objects in Salesforce
- Get real-time access to Salesforce data directly in SQL Server queries to simplify data access in applications and reporting
- Load Salesforce data into a SQL Server data warehouse with DBAmp stored procedures
- Ability to call DBAmp code from T-SQL stored procedures, SSIS, SSRS, Power BI and more
Please see the image below taken from the website detailing DBAmps offering.
Business Problem
The "Power Up Generators Inc." business is using Salesforce online to keep track of accounts, contacts, and opportunities. Our manager has asked us to create a dimensional model for reporting within our local SQL Server database. Additionally, we want to explore different ways to pull data from and push data to the cloud application.
Development System
All development of the solution will be done on a virtual machine in the Azure Cloud named vm4dbamp. I choose to use a Windows Server 2019 operating system. The image below shows the downloaded software for Google Chrome, SQL Server Developer Edition and SQL Server Management Studio stored in a temp directory. I am assuming that you already know how to deploy and configure each of these products.
There are a couple of prerequisites that need to be satisfied before installing the DBAmp software. The first prerequisite is to have an operating system version greater than 2008 R2 and a database engine version greater than 2008. Since I have the 2019 version of both products, we are in good shape.
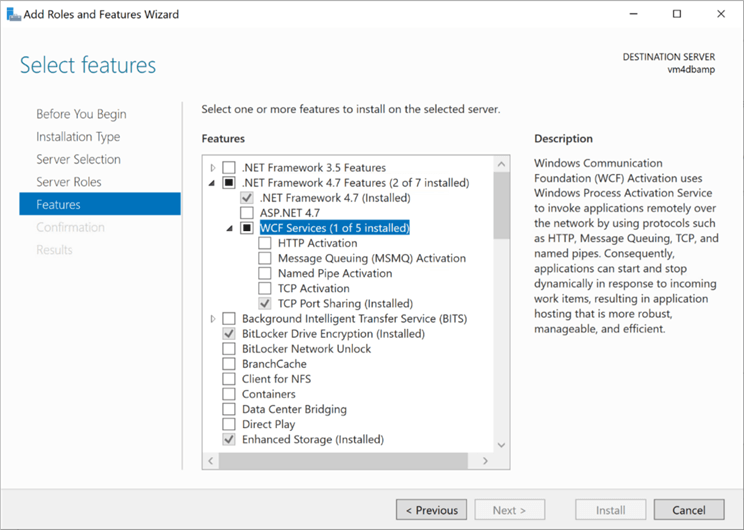
The second perquisite is to have the .NET framework 4.6 or greater installed on the operating system. The above image was taken from the server manager application. We can see that version 4.7 of the framework is currently installed.
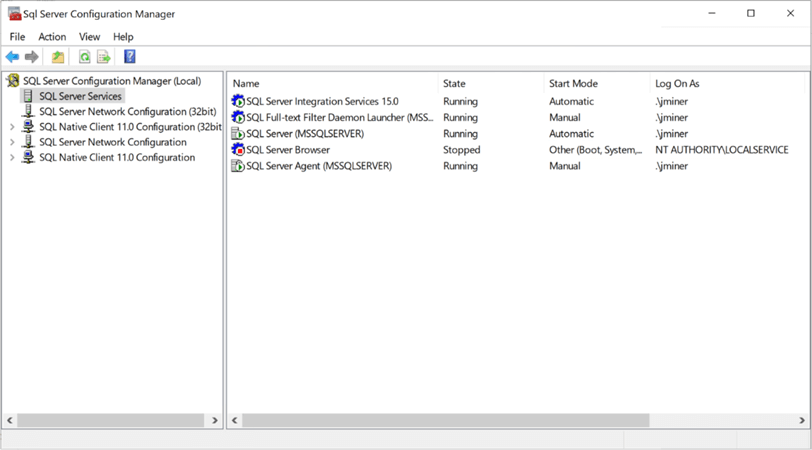
The third prerequisite is to have the various services running on a local or domain account. Since the virtual machine is not attached to an Active Directory Domain, I choose to use my local administrator account for this purpose. In the real world, I would use a domain account that has Power User rights on the virtual machine. The above image shows the SQL Server configuration manager application that was used to change the service accounts.
To recap, there are three main prerequisites for the product. There are other issues that we will encounter and address during our exploration of the product. However, we are now ready to install the DBAmp software.
Install DBAmp
The installation of the software is pretty straightforward. It has to be done on the database server since we are adding an OLE DB provider to the system. I am enclosing screen shots of the installation process for completeness.
The welcome screen tells the user which installation program is executing. Please click the next button to continue.
The customer information screen asks for the username, organization name and serial number. For this proof-of-concept exercise, I am using the trial version of the product. Please enter the required information and click the next button to continue.
The end-user license agreement screen supplies the customer with the legal details associated with using the software. Please accept the terms and click the next button to continue.
The installation folder screen allows the customer to choose a different folder than the default location. Please accept the default location and click the next button to continue.
The ready to install screen tells the customer this is the last chance to change any entered information before installing the program. Optionally, one can cancel the installation all together. Please click the install button to continue.
The completed installation screen tells you, the end user that the software is installed on the database server.
In summary, installing the software is extremely easy. Make sure you have permission to install the software on the database server. The next step is to configure the software using SQL Server Management Studio (SSMS).
Configure Linked Server
The real time bi-directional connectivity from SQL Server to Salesforce is supplied by CData’s OLE DB provider. The linked server named SALESFORCE is key to most, if not all the components. By the way, the name is only a suggestion. You can use any name you want. In this section, we will go over configuring both the OLE provider and the linked server. For general details on linked servers and ole providers, please see the MSDN online documentation.
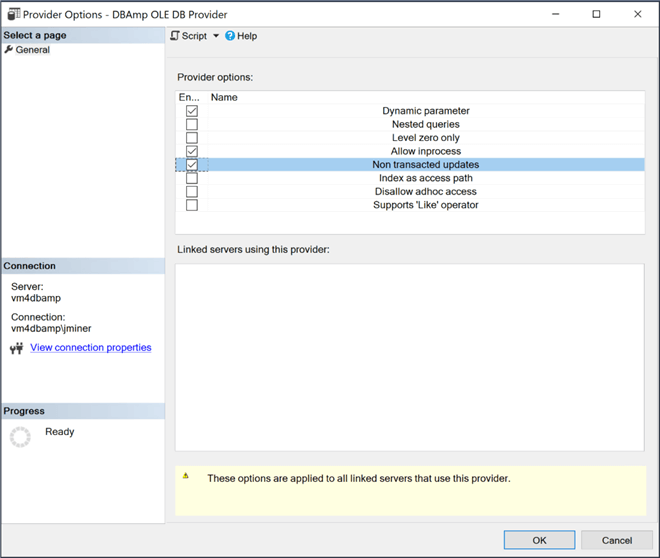
Find the DBAmp OLE DB provider in the object explorer under Server Objects, Linked Servers, and Providers. Right click the provider to change the properties (options). The image below shows that following options must be enabled: "dynamic parameters", "allow inprocess" and "non transacted updates". Any other options should be disabled.
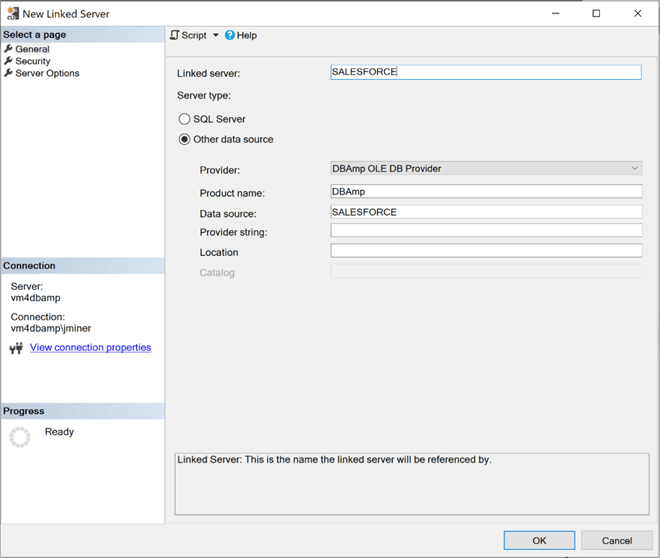
Right click to linked servers and choose the new linked server option. The first step is to set the general properties of the new server. I am going to set both server name and data source to "SALESFORCE". The product name is optional, but I choose to enter "DBAmp".
The second step is to configure the security to use when making a connection to the Salesforce Online (SFO) cloud application. My fully qualified name for the SFO application is [email protected]. The hard part to remember is that the remote password is a combination of both the application password and the security token. They are just appended together.
To configure the Salesforce connection, we need to request a security token. I am not an expert with this CRM product; However, I can google the instructions like the best of them. Here are the instructions to create a new security token. The token was emailed to the account associated with the CRM product, [email protected].
Since the SQL Server is running under my local user account, I am going to map the local "vm4dbamp\jminer" account to the remote "[email protected]" account.
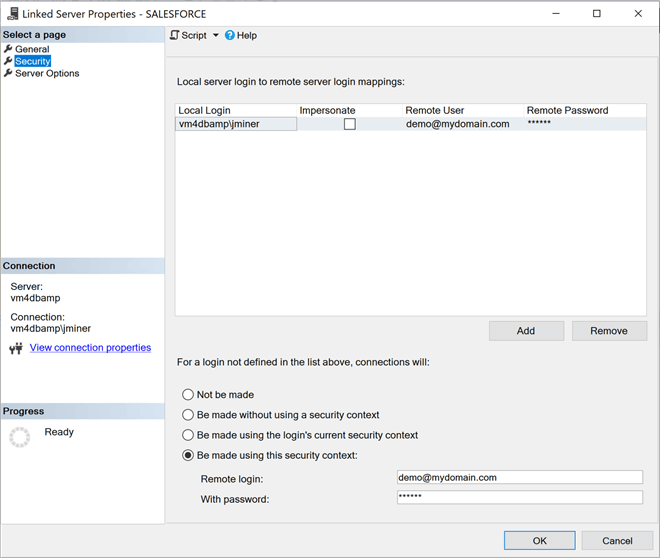
The third and last step is to set server options. The following options need to be set to true: "collation compatible", "data access", "rpc out" and "use remote collation". All other options should be set to false.
I am not an expert at Customer Relationship Management (CRM) packages such as salesforce.com. It is important to get familiar with the application interface. We can see that we have 13 account records.
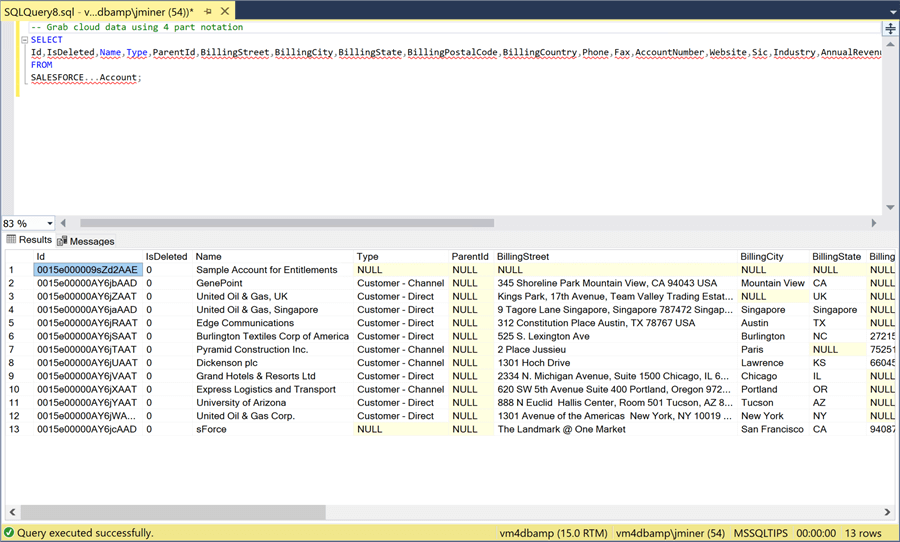
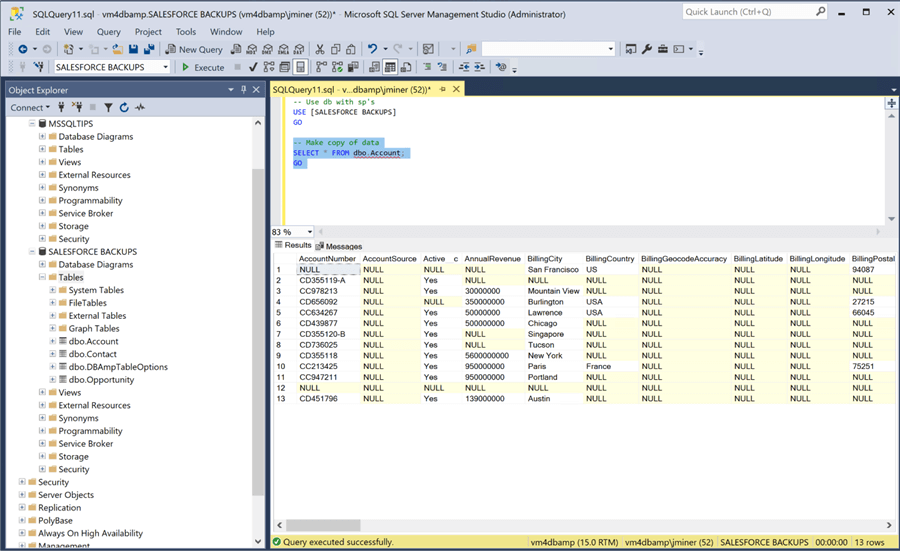
The easiest way to test the connect is to create a query using a four-part notation for the table name. The image below returns all records from the [Account] table using the [SALESFORCE] linked server connection. If you do not have any firewall preventing access to the internet, the SQL select statement should return records with just standard SQL code.
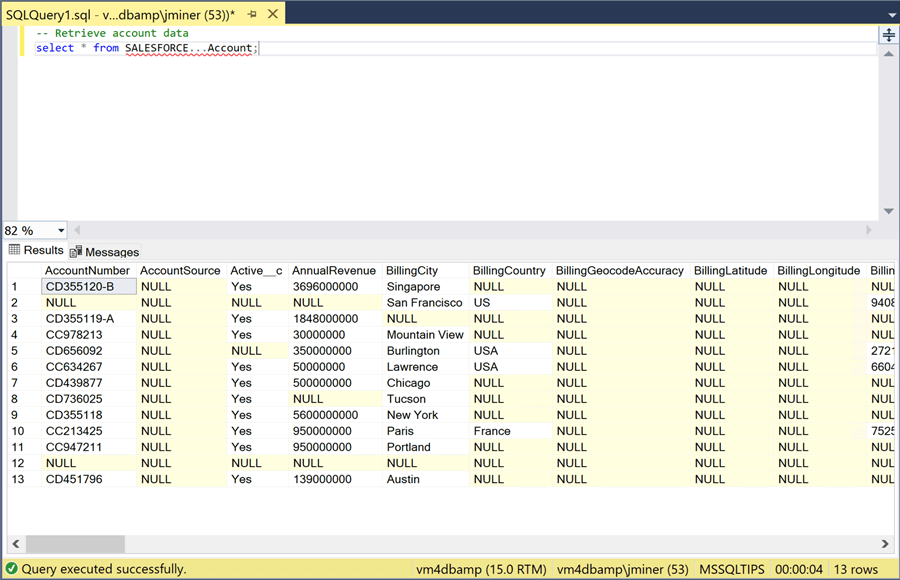
One bad practice is to write queries that select all the columns of a table. When we create a dimensional model in the next section, we will supply the column names to reduce the total amount of data transferred from SFO to SQL Server. In a nutshell, configuring the OLE DB Provider and creating the linked service is quite routine. Just make sure you concatenate the user password and security token when creating the remote password. I always get stuck on this detail.
Creating the Dimension Model
Dimensional modeling always uses the concepts of facts (measures) and dimensions (context). The fact tables are composed of numeric values that can be aggregated and foreign keys that relate the table to various dimensions. The dimension tables are descriptors that define the facts. Today, we are creating a dimensional model for leads for the Power Up Generator Inc. company.
The table below describes each table in the database named MSSQLTIPS. There are three different schemas that are used to segregate the tables. The STG schema contains the raw data pulled from Salesforce. The DIM and FACT schemas complete the traditional table naming in the dimensional model.
| No | Table | Description |
|---|---|---|
| 1 | DIM.CONTACTS | Contacts related to leads and sales. |
| 2 | DIM.DATE | Describe current date in hierarchical order. |
| 3 | DIM.LEADSOURCE | Describe how the lead came in. |
| 4 | DIM.LEADSTAGE | Describe the stage of the lead. |
| 5 | DIM.LEADTYPE | Describe the type of lead. |
| 6 | FACT.LEADS | This table has information about leads. |
| 7 | STG.SFO_ACCOUNTS | The raw account data from salesforce. |
| 8 | STG.SFO_CONTACTS | The raw contact data from salesforce. |
| 9 | STG.SFO_OPPORTUNTIES | The raw opportunity data from salesforce. |
The following relationships exist between the LEAD FACT table and various dimension tables.
| Table 1 | Table 2 | Description |
|---|---|---|
| FACT_LEADS | DIM_CONTACTS | Each lead has one main contact. |
| FACT_LEADS | DIM_DATE | Both created and closed date represented as numeric keys. |
| FACT_LEADS | DIM_LEADSOURCE | How did the lead come into the sales department? |
| FACT_LEADS | DIM_LEADSTAGE | What stage of the sales process is the lead? |
| FACT_LEADS | DIM_LEADTYPE | Is this a new or existing customer? |
There are many ways to create and populate a dimensional model. In my last article, we used SQL Server Integration Services (SSIS) with CData’s adapters to store data from Salesforce into temporary delimited text files. This is great since we have the names of the columns that we need for are very specific SELECT query. The image below shows the use of a four-part notation when the name of the table is being referenced. This technique leverages the linked server to pull the data from SFO to our query window in SSMS.
Most of the tables in the dimension model are based off the raw data from the accounts, contacts and opportunities tables. For this proof of concept, we will load the dimension and fact tables one time during database creation. In the real world, we will want to create an UPSERT process since we will have data based upon existing surrogate keys and we might have large amounts of data being loaded into the model
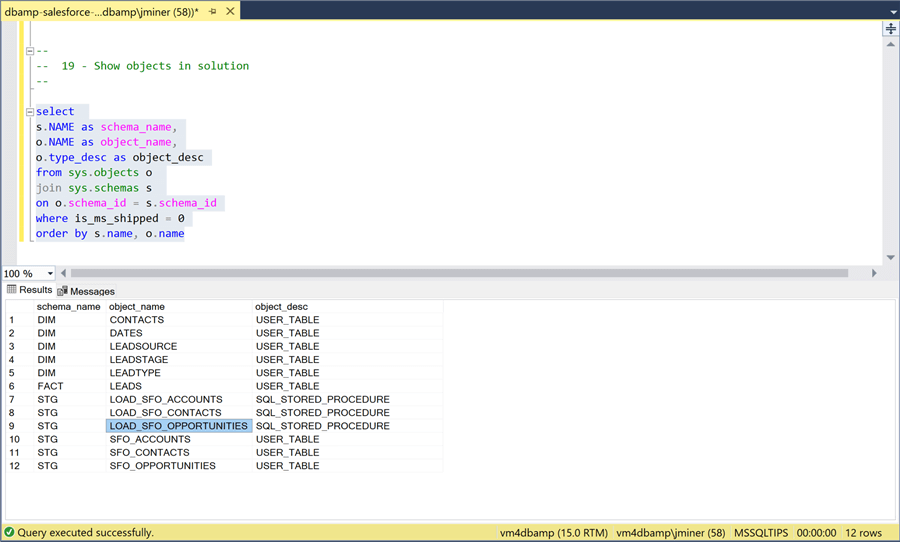
The above image shows the tables and stored procedures in our solution. Instead of writing an Extract, Translate and Load program using SSIS, we can now write a stored procedure. The procedure truncates the raw staging table and then uses the linked service to repopulate the table with the latest data. Enclosed is the complete TSQL script to create the database.
Existing database developers will really like the DBAmp product since existing TSQL skills can be used to write stored procedures that perform the ETL actions.
Testing the Dimension Model
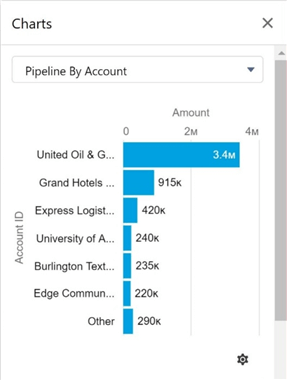
It is very important to make sure that reports in the Cloud Applications can be reproduced in our dimensional model. Therefore, I am going to write some SQL statements to make sure that sample reports can be recreated. The image below was taken from Salesforce application, and it shows the pipeline (leads) by account.
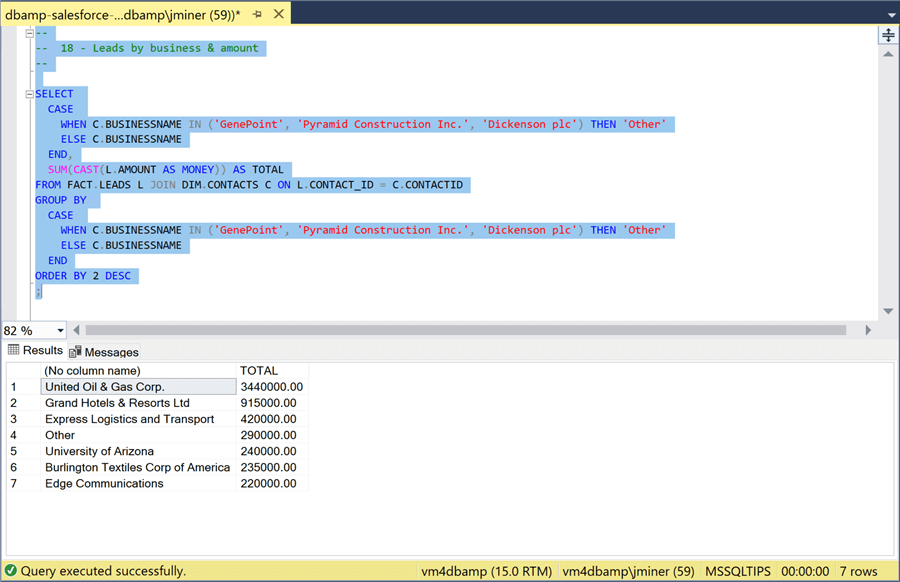
To recreate the report, we have to use a case statement to group three companies into a label named "other". We just need to join the LEADS FACT table to the CONTACTS DIM table and aggregate the opportunity amount.
The image below was taken from Salesforce application, and it shows the pipeline (leads) by stage.
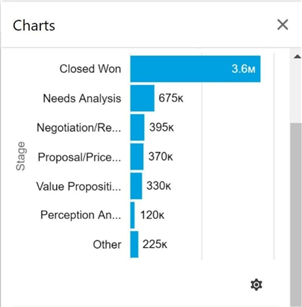
To recreate the report, we have to use a case statement to group three stages into a label named "other". We just need to join the LEADS FACT table to the LEADSTAGE DIM table and aggregate the opportunity amount.
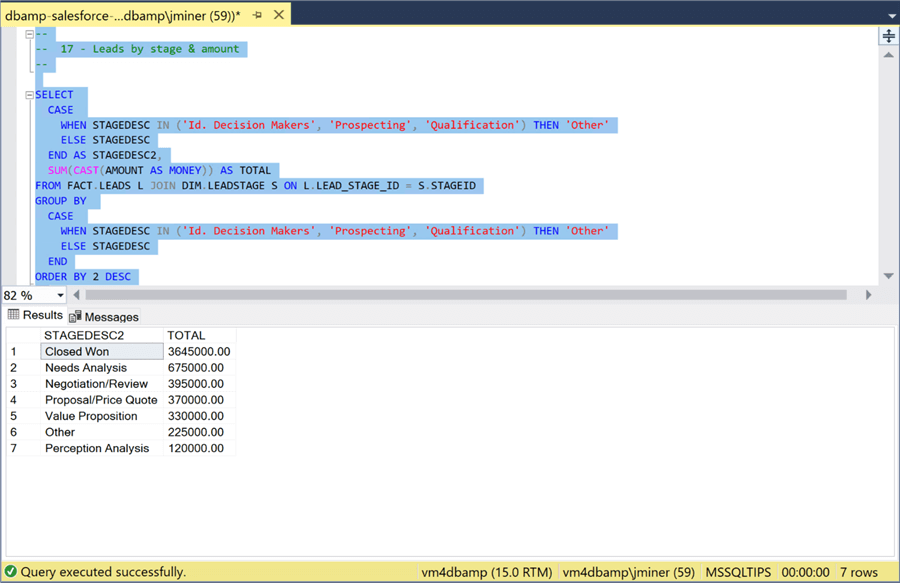
So far, we have pulled data from the Salesforce application to local staging tables. But there are several questions to be asked to improve performance and maintenance. For instance, is there performance concerns when data is joined or aggregated using the four-part table naming notation? Additionally, if we want more tables to be brought over to our local SQL Server database, do we have to write stored procedures for each table?
Local versus Remote - Processing
To date, we have used the four-part notation for table names to leverage the linked server named "SALESFORCE". This statement pull data to the local database and executes data processing locally. However, we can also use the OPENQUERY relational operator to pass the query to the source system. The query is processed on the remote system and the results are returned to the local database.
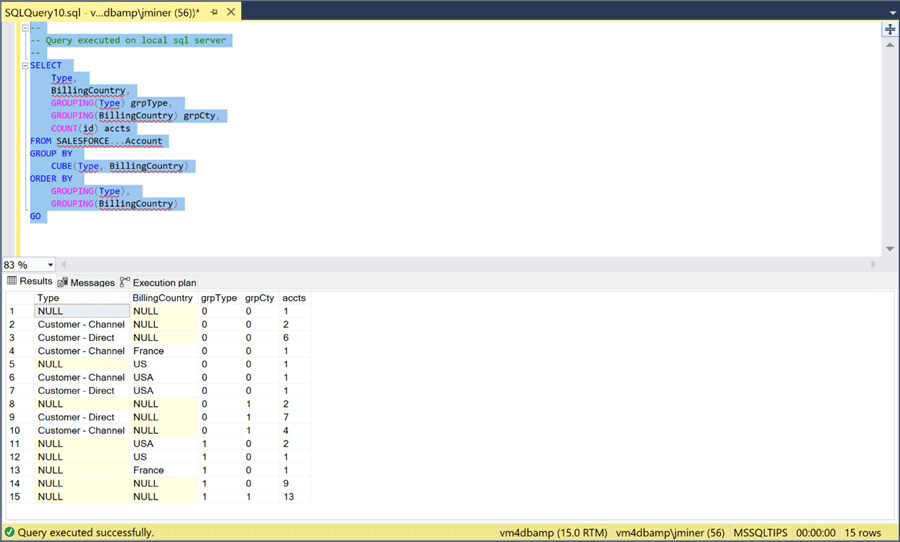
Let us use an example from the DBAmp documentation. The query below executes a GROUP BY CUBE operation. Behind the scenes, several aggregations over the same table must occur to produce the results. As for per execution speed, it takes less than a second since we have only 13 accounts.
A better way to figure out if the above query will have performance issues with a large amount of data is to look at the execution plan. When writing queries, table spools place a copy of the resulting data in TempDB. If the data is large, it might spill to disk. In short, table spools are resource intensive.
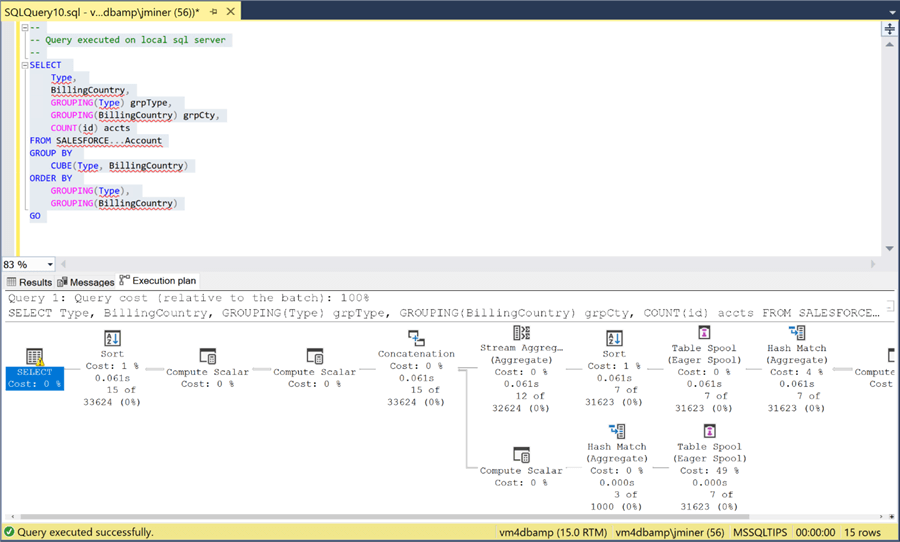
The same query has been passed to Salesforce application using the OPENQUERY relational operator. If we look at the execution plan, we can see that the results are just scanned and displayed in the query window. Thus, all processing is done within the cloud application.
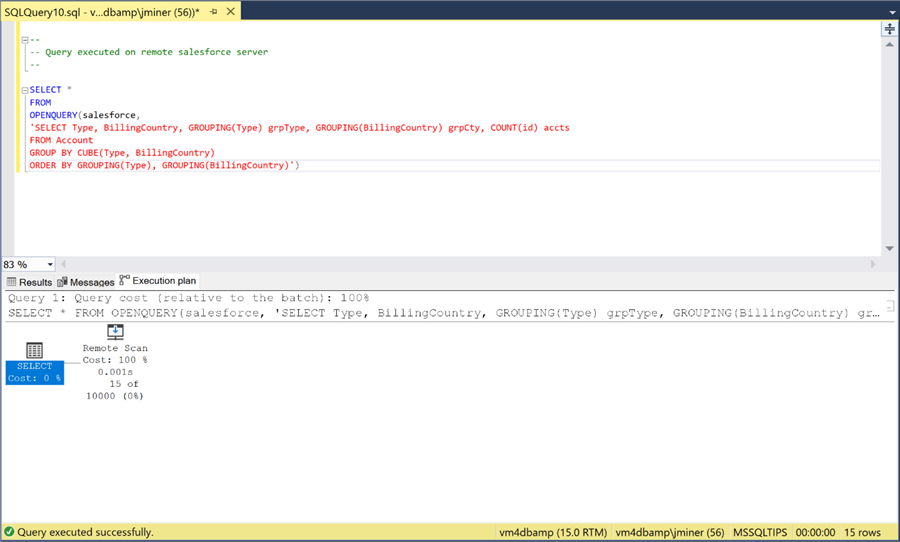
To recap, joins between tables are usually expensive if indexes are not in place. If you are using the four-part notation for table names, consider investigating the OPENQUERY relational operator. It places the execution load of the query on the remote database instead of the local database.
Mirroring Salesforce Table Data
The DBAmp product has two advanced functions that we want to investigate. The SF_Mirror stored procedure allows the user to call a custom stored procedure to pull table data from Salesforce application to the local database. This eliminates the need to write custom code. The SF_TableLoader stored procedure allows the user to push data from the local database to the Salesforce application.
Following the documentation, please create a new database called "SALESFORCE BACKUPS". Within the installation directory, you will find the "Create DBAmp SPROCS.sql" script. Please execute this script within the new database.
![CDATA - DBAMP - Create [SALESFORCE BACKUPS] database and install stored procedures.](/tipimages2/7053_connect-salesforce-to-sql-server-with-dbamp-from-cdata.026.png)
The script creates 41 new stored procedures in the database. Right now, we are concentrating on testing the SF_Mirror stored procedure.
![CDATA - DBAMP - View stored procedures in the [SALESFORCE BACKUPS] database.](/tipimages2/7053_connect-salesforce-to-sql-server-with-dbamp-from-cdata.027.png)
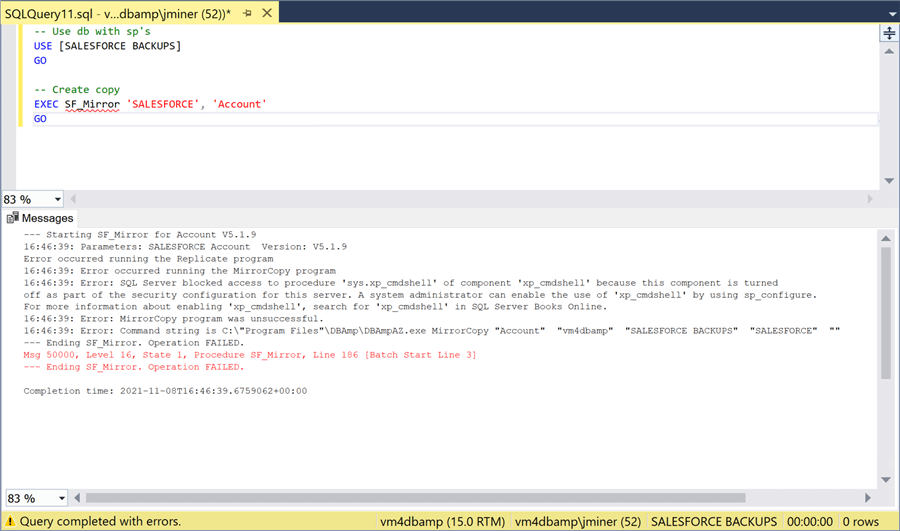
The image below shows the correct syntax to create a copy of the [Account] table in the [SALESFORCE BACKUPS] database. The execution of the stored procedure results in an error message. The stored procedure is just a wrapper to a system call to the DBAmpAZ.exe program. If we go back to the documentation, the stored procedures require the xp_cmdshell system stored procedure to be enabled. For this demonstration, I am going to enable it using this article. However, this introduces a potential security attach vector for our database. A better solution is to create a proxy account that has limited rights to the server. Please use this article to create the account in the future.
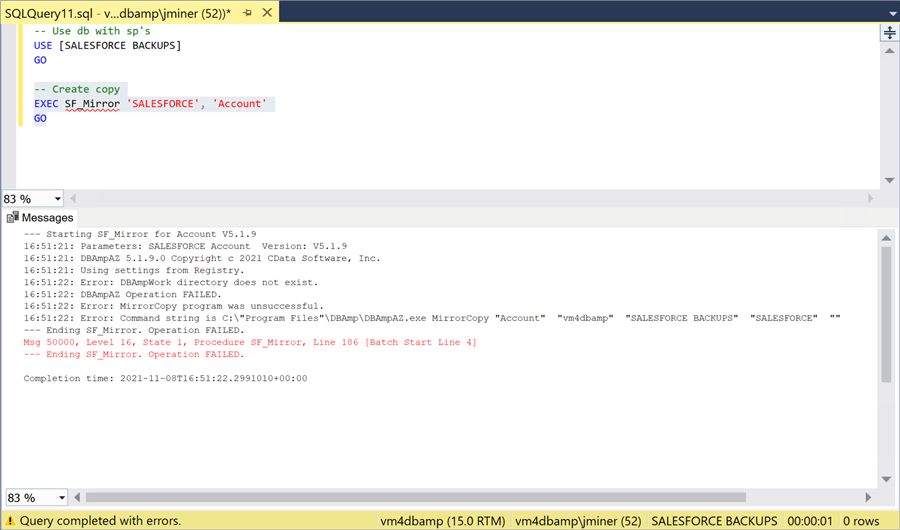
Now that we can create a system call, let’s try executing the stored procedure again. This time we obtain a different error message. It is stating that the work directory does not exist.
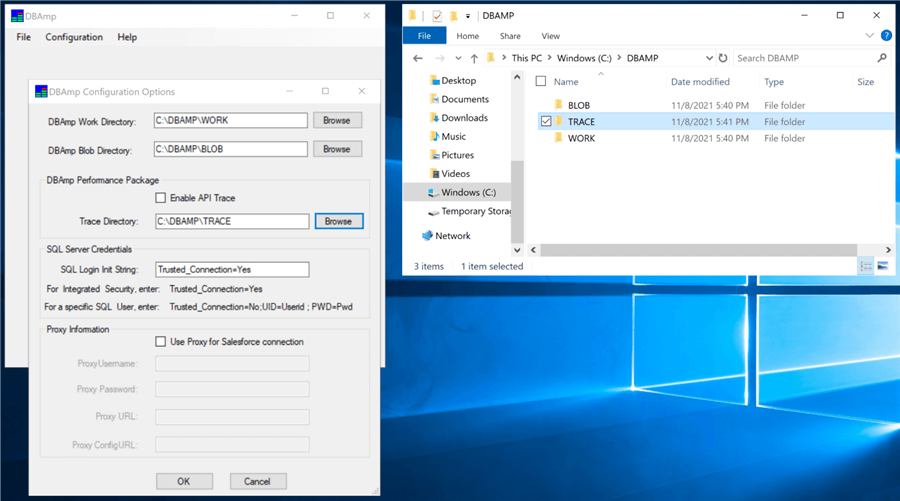
If we look at the documentation, the DBAmpAZ.exe program is looking for registry settings for three directories. We can use the DBAmp configuration program to select the directories and write these settings to the registry. The image below shows a directory for the BLOB, TRACE and WORK directories.
Hopefully, we have satisfied all requirements for the stored procedures. If we execute the SF_Mirror stored procedure, we can see the output and a success message. That is awesome. We now have a single stored procedure that uses the Salesforce BULK API to mirror tables between the two systems.
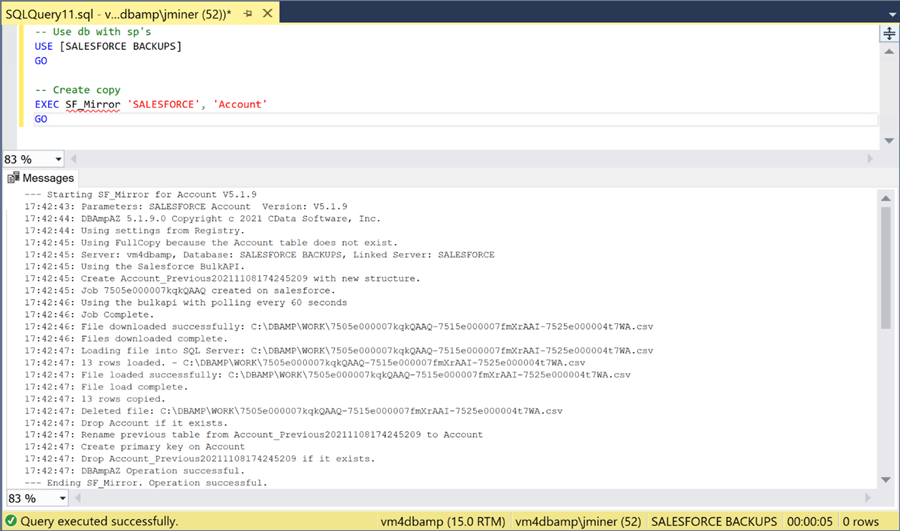
I wrote code to execute the SF_Mirror stored procedure for the [Account], [Contact] and [Opportunity] tables. These are the three main staging table used by our dimensional model. The SELECT statement below returns the correct number of account records.
There are a lot more features within the DBAmp product. I just do not have time to cover them all in one article. For instance, the SF_MirrorAll does a complete transfer of all tables between the two systems. We can configure which tables are mirrored using a control table named [DBAmpTableOptions]. Typically, these stored procedures pull over all columns when mirroring data. However, there are several stored procedures in the DBAmp product take a SOQL (Salesforce Online Query Language) query as input. This query can select a subset of the columns in the remote (Salesforce) table. For example, the SF_BulkSOQL stored procedure creates a local table given the results of executing the SOQL query on the remote table. Additionally, the SF_BulkSOQL_Refersh stored procedure keeps the local (SQL Server) table in-synch with the remote (Salesforce) table. Again, the stored procedure uses a SOQL query as input; detects changes between the local and remote tables; and executes the appropriate INSERT, UPDATE, and/or DELETE statements.
Loading Table Data into Salesforce
A developer can use the four-part notation to perform INSERTS, UPDATES and DELETES against the Salesforce application database. However, these actions will be slow since we are using an OLE DB connection. Do not fret, the SF_TableLoader stored procedure can use either the BULK API or the SOAP API. Please refer to the documentation for details.
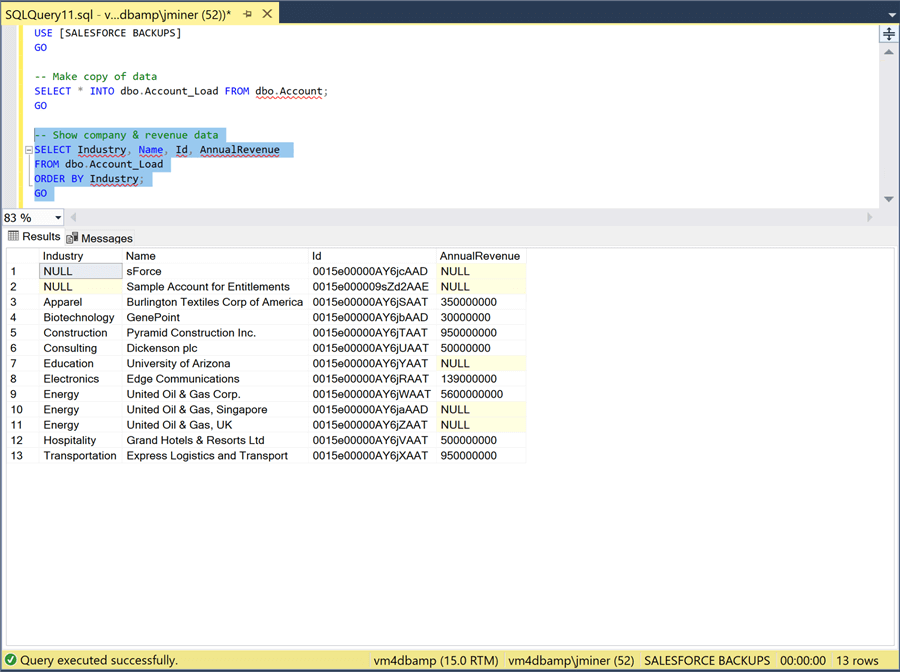
The first step in using this stored procedure is to create a load table. The requirement is to have the table name be a superset of the name in the Salesforce database. For instance, to load the [Account] table, we are going to use the [Account_Load] table. The script below creates this new table from the mirrored table.
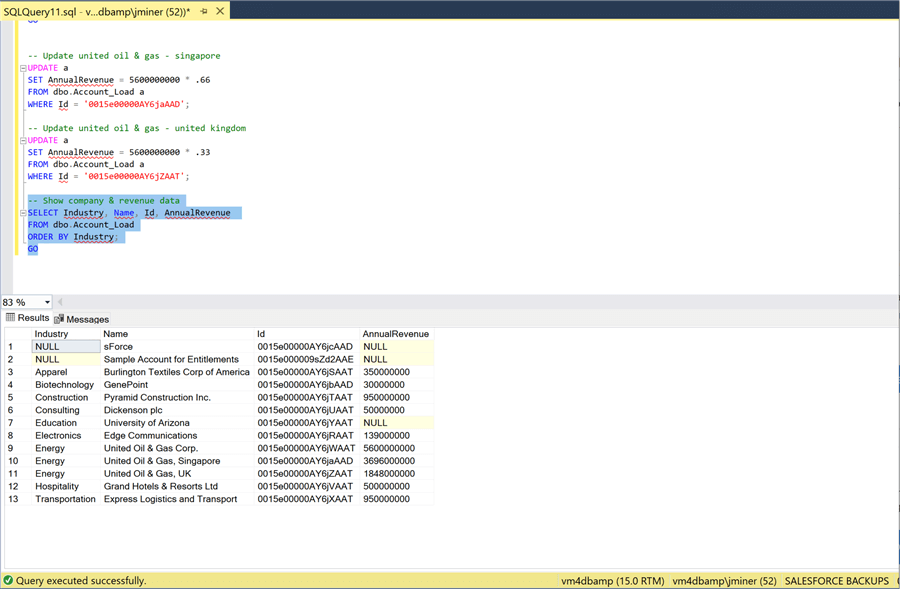
During my use of the Salesforce application, I noticed that the revenue for the Singapore and United Kingdom branches of the United Oil & Gas Corporation did not have annual revenue posted. To make things simple, I decided that the revenue is split 66/33 between the two branches. The image below shows an update statement that makes this change to the local table named [Account_Load].
The call to the stored procedure is very simple. It takes the action, linked server name and table name as inputs. The output shows that the same DBAmpAZ.exe program is called. It is using the SOAP API to move data from the local server to the remote database.
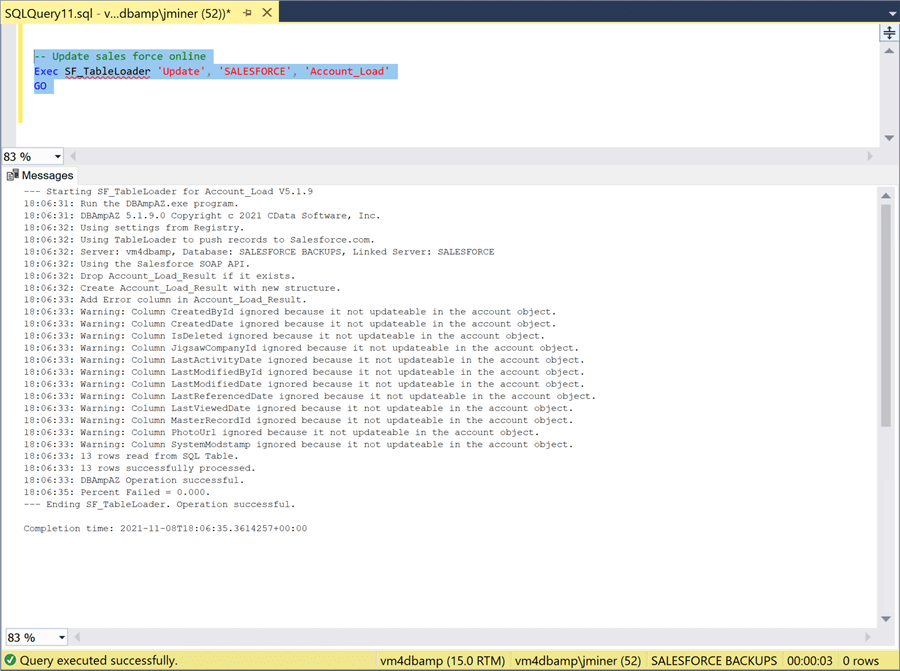
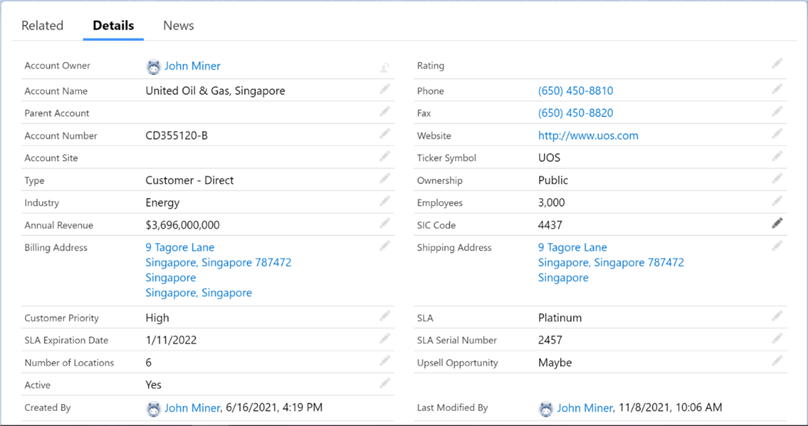
The only way to verify the updates is to use the Salesforce application. The Singapore branch has a yearly revenue of 3.696 B.
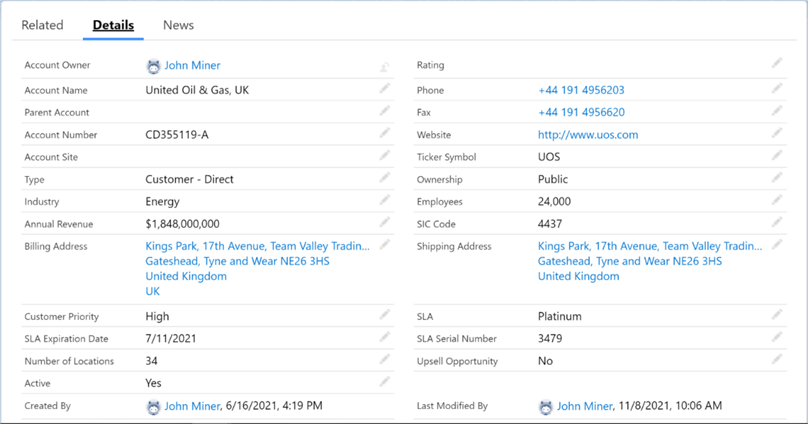
The United Kingdom branch has a yearly revenue of 1.848 B. If we add up the numbers, we have a result of 5.544 B. I was expecting 5.600 B as an annual revenue for the whole company. You can see that I made a rounding error. We are off by 1 percent. When it comes to billions of dollars, that is a lot of money. I will let you adjust the TSQL Script so that the second update is 34 instead of 33 percent.
In short, the SF_TableLoader stored procedure give you more options on how to update the remote Salesforce database table with a local SQL Server table.
Summary
Today, many companies have both new and old technology. As a seasoned SQL Server developer, how can we read data from and write data to the Salesforce application?
The DBAmp product includes numerous components centered around an OLE DB provider for the Salesforce application. It is very easy to install the software on the database server and create a linked server. Reading and writing data to the remote cloud application can be done with either four-part table naming or using the OPENQUERY relational operator. The first technique might use local resources when joining tables. This may result in slow performance due to higher resource usage. The second technique pushes the query execution onto the database used by the cloud application. Only the results are returned to the local SQL Server.
The hypothetical company named "Power Up Generator Inc." wanted to take data from the Salesforce application and create a dimensional model in our local SQL Server database. Instead of writing SSIS packages, stored procedures were used to copy data from Salesforce to our local database. Additional code was created to populate both the DIM and FACT tables. However, this code does not support UPSERT’s. In the real world, we would want to do incremental loads on the larger tables.
Up to now, the demonstrated techniques we used do not leverage the BULK APIs supported by most database vendors. The installation and configuration of the DBAmp stored procedures does take a little work. However, the executable that is called by the stored procedures uses both the BULK and SOAP APIs. Instead of writing tens of stored procedures, we can use a single stored procedure named SF_Mirror to copy over up to date table data. Likewise, the SF_TableLoader stored procedure allows a developer to update the remote Salesforce table using a local update table. There are many options associated with these stored procedures. Please read the documentation carefully.
I purposely did not talk about SSIS development since I think the DBAmp product is suited for a company that is just using the Salesforce application. If you are using more than one cloud application, I suggest you look at the adapters that are sold by CData. However, SSIS can leverage the linked server that we setup during the proof of concept. Just use either a four-part notation with an OLE connection or call the stored procedure with an execute SQL Task. Again, the choice is up to the system designer on what to use.
Here is an honest review of the CDATA’s DBAmp product. It was very easy to obtain and install the OLE DB provider for SQL Server. If you have worked with four-part table naming or the OPENQUERY relational operator in the past, it is very easy to build a system such as a dimensional model (data mart) on top of this technology. For greater speed and ease of use, take a look at the SF_Mirror and SF_TablerLoader stored procedures. Some organizations might be leery of security hole that is opened by enabling the xp_cmdshell stored procedure. This risk can be mitigated by using a proxy account to call the executable. Reduce the privileges of the account so that the risk is minimal. I really like the fact that a detailed help file is located on your hard drive after the install. I suggest you consult this documentation for more details. In summary, I would not hesitate to recommend the use of CDATA’s DBAmp product for bi-directional connectivity to the Salesforce application from a Microsoft SQL Server database.
Enclosed is a zip file that contains T-SQL code used in the article. I hope you enjoy the details as much as I did!
Next Steps
- Learn more about DBAmp – Data Integration Features, Customer Use Cases, Pricing, etc.
- Get a 30-Day Free Trial of DBAmp
- Contact Support with any questions
- Learn about all the CData software solutions including connectors for numerous technologies
MSSQLTips.com Product Spotlight sponsored by CData.
About the author
 John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.
John Miner is a Data Architect at Insight Digital Innovation helping corporations solve their business needs with various data platform solutions.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
Article Last Updated: 2023-07-20
