Problem
Azure Synapse supports the concept of a lake database, which can be defined by either Spark Hive Tables or Common Data Model (CDM) exports. There is support for an active link from Data Verse to Synapse. This link allows Power Apps and/or Dynamics 365 to export data continuously to the lake database in CDM format.
Having a SPARK cluster run all the time to view read-only data can be costly. Because data is written once and read many times, how can we reduce the cost of our company’s reading activities?
Solution
Azure Synapse Analytics Serverless SQL pools allow the architect to replace the interactive SPARK cluster with a lower-cost service. Below is a high-level architecture diagram of Synapse Serverless Pools. Queries submitted to the Serverless SQL pool can view data stored in any lake database format once security is set up correctly.

Business Problem
Our manager has asked us to investigate how to read data stored in a lake database using Azure Synapse Analytics to reduce our overall cost. We will focus on tables created by the Apache Spark cluster. Here is a list of tasks that we need to investigate and solve.
| Task Id | Description |
|---|---|
| 1 | Create environment |
| 2 | Managed Tables |
| 3 | Unmanaged Tables |
| 4 | Limitations |
| 5 | Security Patterns |
| 6 | New Activity Directory User |
| 7 | New Standard SQL User |
There are many concepts to review and explain during this investigation. I’ve executed a word cloud Spark notebook in Azure Synapse to highlight the keywords. Database, security, table, and storage are very common words.

At the end of the investigation, we will understand how to manage SQL Serverless pools for Azure Synapse lake databases.
Create Environment
For our experiments, we need a storage account configured for Azure Data Lake Storage and Azure Synapse Workspace. Of course, we need to deploy and configure the Azure Synapse service. Additionally, we will want to test access to the lake database using a virtual machine with SQL Server Management Studio (SSMS) installed as an application. This test can be repeated with other user tools such as Azure Data Studio, Power BI Desktop, or Anaconda Spyder.
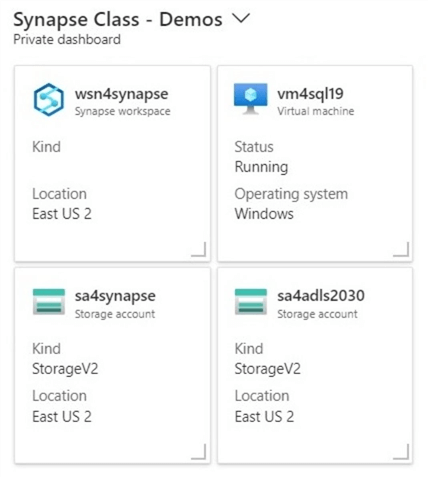
The above image shows my dashboard, which I use when teaching an Azure Synapse class. Why are there two storage accounts? The Synapse service requires a data lake storage account upon deployment. This account is named sa4synapse and stores the managed tables. The unmanaged tables are stored in the generic storage account, sa4adls2030.
Managed Tables – Lake Database
The first step is to create a Spark notebook that reads all the CSV files in a sub-directory into one data frame. The code below reads all S&P stock files for 2013 into a dataframe named df_2013.
%%pyspark
#
# 2013 - Read 500 + company stock data
#
# define schema
df_schema = "st_symbol string, st_date string, st_open double, st_high double, st_low double, st_close double, st_adjclose double, st_volume int"
# read in data
df_2013 = spark.read.load('abfss://sc4adls2030@sa4adls2030.dfs.core.windows.net/stocks/S&P-2013/', format='csv', header=True, schema=df_schema)
# show record count
print(df_2013.count())
Copy this code four more times and adjust for 2014 to 2017. The next step is to combine the data frames into one. The unionAll method allows us to complete this technical task.
%%pyspark # # union all five years # # combine data frames df_all = df_2013.unionAll(df_2014).unionAll(df_2015).unionAll(df_2016).unionAll(df_2017) # show record count print(df_all.count())
Now, we need to create a new database called stocks if it does not exist. It is important to note that our magic command has changed from %pyspark (Spark Python code) to %sql (Spark SQL code).
%%sql
--
-- Create database - stocks
--
USE default;
CREATE DATABASE IF NOT EXISTS stocks;
USE stocks;
To make the code restart-able, we should always drop an existing table before creating a new one.
%%sql
--
-- Drop Table - s&p500
--
USE stocks;
DROP TABLE IF EXISTS snp500;
The last step is to save our data as a hive table. When creating managed tables, the delta file format is used by default. The first time I ran this code, I left off the repartition command and ended up with 81 separate files. This is not a problem unless you must manually assign file and folder rights to a user.
%%pyspark
#
# create managed hive table
#
df_all.repartition(4).write.mode('overwrite').saveAsTable("stocks.snp500")
The query below shows Microsoft’s stock data sorted by trade date. Unfortunately, we have unexpected results. The st_date column is a string, not a date. This can be fixed by adding a new column using the withColumn method. The definition of this column should use the to_date method to cast the string to a date. I’ll leave this exercise up to the reader to complete.

The query below shows the total number of records in all 2,533 CSV files is 638,355. That is a lot of files!
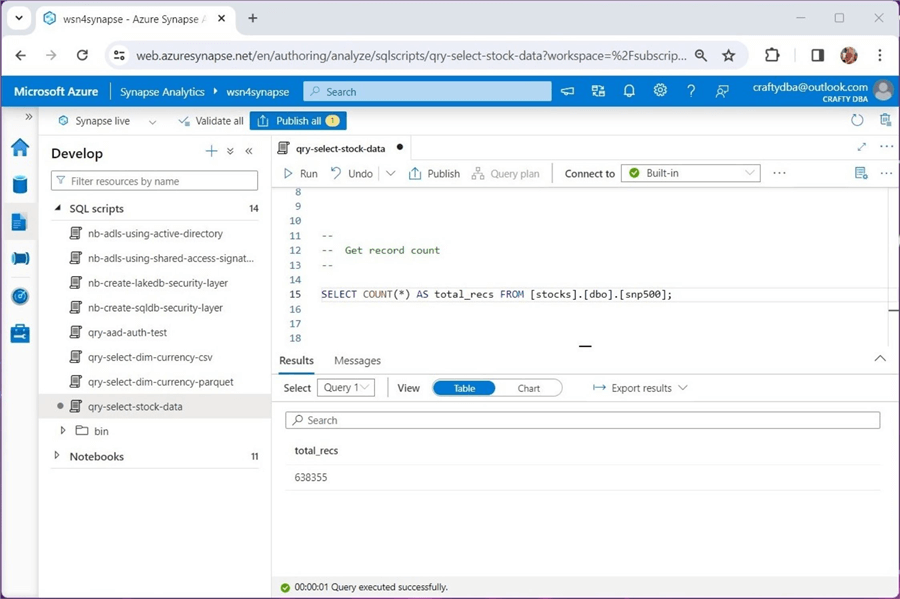
This example used the comma separated values (CSV) format, which is considered weak in nature. To make loading faster, it is important to supply a schema definition with this type of format. In short, creating managed tables in Azure Synapse using the Spark engine can be easily done. Just remember that dropping a managed table also deletes the underlying data files.
Unmanaged Tables – Lake Database
The AdventureWorks database is a sample database that could be used to learn about Microsoft SQL Server databases. The LT version of this database was a paired-down version of the OLTP database. I have loaded the delimited files into the data lake and converted them to Apache Parquet format. This format is considered strong in nature. The superior properties of Parquet are its binary format, known column names, known data types, and ability to be partitioned.
Creating a new schema (database) allows the developer to segregate the two data sets: stocks and bikes. Please see the code below that drops the database. Again, we are using Spark notebooks with the appropriate magic commands.
%%sql
--
-- Drop database - saleslt
--
USE default;
DROP DATABASE IF EXISTS saleslt CASCADE;
The next step is to create a database named saleslt. Let’s create our first table after completing this step.
%%sql
--
-- Create database - saleslt
--
CREATE DATABASE IF NOT EXISTS saleslt;
USE saleslt;
The code below creates the table named dim_currency. Because Apache Parquet is a strong file format, we only need to supply the location of the directory containing the parquet files. Please see the code bundle at the end of the article for creating all tables in the saleslt schema.
%%sql
--
-- Create Table - dim.currency
--
CREATE TABLE dim_currency
USING PARQUET
LOCATION 'abfss://sc4adls2030@sa4adls2030.dfs.core.windows.net/synapse/parquet-files/DimCurrency';
The query below shows the details of the currency dimension table. The notebook is using the Serverless SQL pool to query the data stored in the unmanaged hive table.

This example uses the Apache Spark file format, which is considered strong in nature. We do not have to supply a schema definition since it is built into the binary file. In short, creating unmanaged tables in Azure Synapse using the Spark engine is a piece of cake. Don’t worry about dropping the table; the data will not be removed.
Limitations – Lake Database
Synapse Serverless pools are used to present data to the user in a read-only format. How can we determine if a hive table is managed (local) or unmanaged (external)? The describe table command can be used to find out the nitty-gritty details of the hive table.
%%sql -- -- Show hive table details -- describe table extended saleslt.dim_currency;
Place the above code in a Spark notebook. Execute the code to see the following output. We can see that the currency dimension is stored in our general storage account.

Let’s repeat this task for the stocks hive table.
%%sql -- -- Show hive table details -- describe table extended stocks.snp500;
Execute the code above in a Spark notebook to see the output below. We can see that the currency dimension is stored in our service storage account.

Lake databases have one major limitation. We can create views using the Spark engine, but views cannot be queried using the Serverless SQL pool. The image below shows that the system catalog named sys.views does exist, but the view named rpt_prepared_data is not listed. However, if we run a Spark SQL query, we can list the contents of the view.

To recap, the Serverless SQL pool can access both managed and unmanaged tables. Spark views are not currently supported. So far, we have no problems with security. That is because the craftydba@outlook.com account I’m using has full access to the Azure Subscription and full rights to both data lake storage accounts. In the next section, we will talk about security patterns.
Security Patterns
Many of the security patterns in Azure have two or more levels of security. The first level is access to the service. The second level is fine-grained access to what the service provides. Let’s start with the Azure Data Lake Storage. The role-based access controls (IAM) have two roles required for access to the data lake. The folders and files with the data lake can be given an access control list (ACL). Both IAM and ACL must be configured correctly so that a user can gain access to the lake database. Please see the table below for details.
| Service | Security Layer | Role / Rights |
|---|---|---|
| ADLS Gen 2 | IAM | Owner Contributor Reader |
| ADLS Gen 2 | IAM | Storage Blob Data Owner Storage Blob Data Contributor Storage Blob Data Reader |
| ADLS Gen 2 | ACL | Read Write Execute |
The Azure Synapse service has the following security layers:
| Service | Security Layer | Role / Rights |
|---|---|---|
| Azure Synapse | IAM | Owner Contributor Reader |
| Azure Synapse | Role Assignment | Many roles See documentation for details |
The image below shows that dilbert@craftydba.com is a contributor to the Azure Synapse workspace.
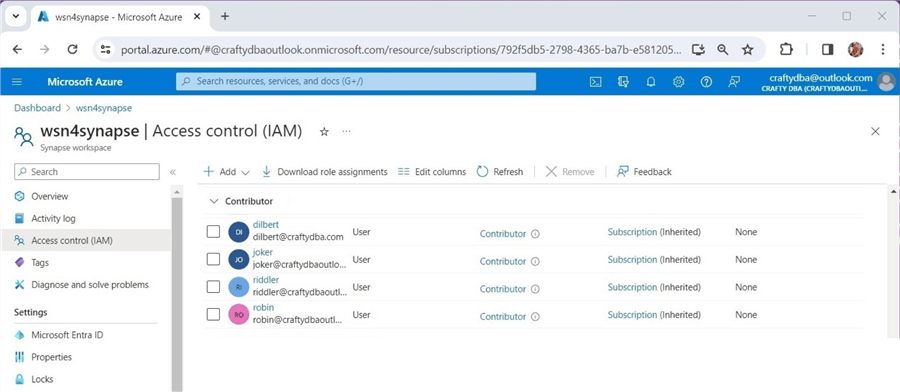
This active directory account has Synapse SQL administrator rights. The screenshot below was taken before I added joker@craftydba.com to the access control list.

Additionally, this user has been given full rights to both data lake storage accounts. Let’s try accessing both the managed and unmanaged tables using SSMS, which is installed on the virtual machine called vm4sql19.

Please note that I chose to use Azure Active Directory password authentication. See the above image. Since two-factor authentication is set up, I am prompted on my authenticator application to enter a code.

The above query shows the S&P 500 stock data in the managed hive table, while the query below shows the currency dimension in the unmanaged hive table.

So far, we have discussed rights using Microsoft Entra ID, formerly known as Active Directory Security. However, Azure Synapse supports Standard SQL Security using logins, users, database roles, and database scoped credentials. The table below shows the four topics we will explore later.
| Database | Security Layer | Description |
|---|---|---|
| master | login | Create a login. |
| master | credential | Map SAS key to file. |
| user-defined | user | Map login to user. |
| user-defined | role | Give user rights. |
Today, we showed how to set up security for a single user. In real life, we would use groups when possible and add users to groups. In the next section, we will show the issues you might encounter when adding a new active directory user to Azure Synapse to get access to the lake database.
New Active Directory User
I have created some users in my domain based on DC Comics cartoon characters. A new company user called joker@craftydba.com wants access to the Synapse Lake Databases. Unfortunately, the Azure Administrator has only given him contributor rights (IAM) at the service level. If you see error 403, the user has not been given rights with the Synapse service.

This can be easily fixed by assigning rights to joker@craftydba.com via the access control form. The image below shows that “joker” has been given SQL administration rights.

The next common error is not having access to the serverless SQL pool. Please see the image below for the error message. This was generated by reducing the rights of the user to Synapse SQL User.
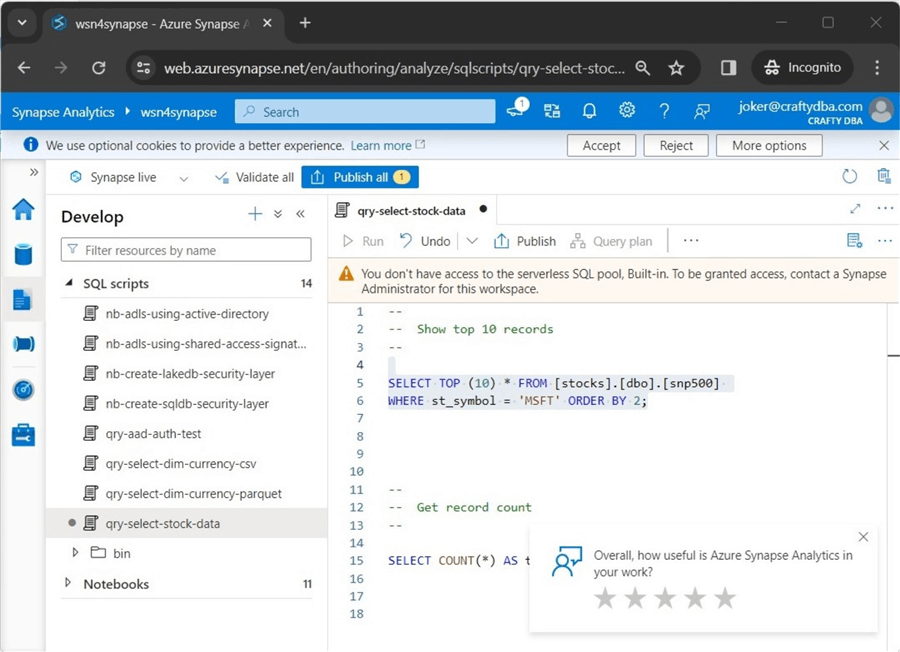
This can be fixed by adding the user to the sysadmin group for the server if they need access to all databases or giving them the Synapse SQL Administrator role. See this Microsoft Learn web page to set up access. Please note that the T-SQL queries for server roles and database roles show the details.
The next error is very common. We cannot list the contents of the ADLS directory since we were not given IAM and ACL rights. Please see the image below for details.
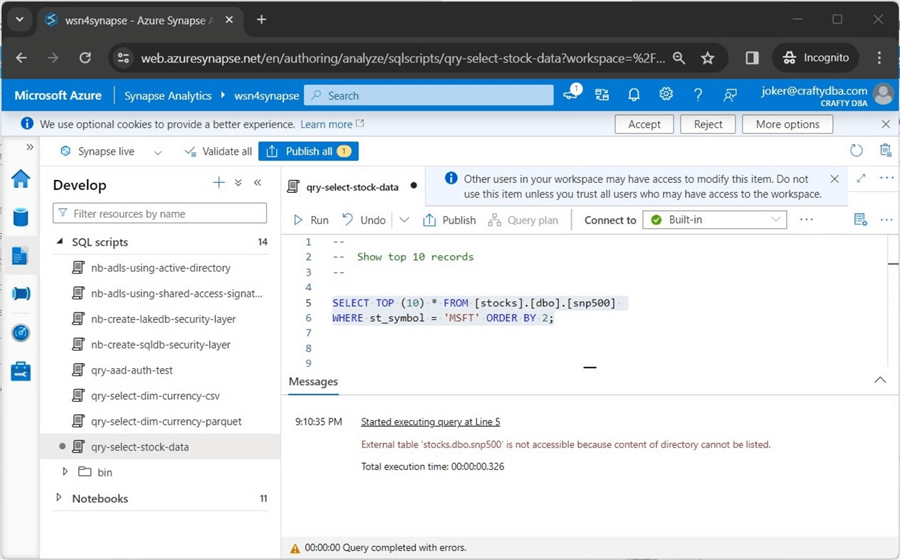
The first task is to assign IAM rights to the user named “joker.” The image below shows the two roles given to the user account.

One might try assigning rights in Azure Synapse Workspace. The image below shows the path to the managed hive table called stocks. This is not the best tool for the job since the user needs access to every folder and file.

The best tool for the job is Azure Storage Explorer. The image below shows the user being assigned permissions for access – the current folders and/or files and default – inherited rights for future folders and/or files.

The above action gives the user “joker” rights to the container named sc4synapse. Right-click and select the propagate access control list option. This will replicate the rights at the container level to all child objects.

We can re-execute the query in Azure Synapse Workspace to display stock data for Microsoft.

Please log into SSMS using the “joker” account and Azure Active Directory Password authentication. The screenshot below shows we have access to the managed table.

Finally, if we try querying the currency table in the saleslt database, we get the listing error again.

The unmanaged table resides in a different storage account and storage container. To make this error disappear, grant “joker” access to general Azure Data Lake Storage named sc4adls2030. In a nutshell, granting access to Active Directory accounts is relatively easy.
New Standard SQL User
The design pattern for Standard SQL security leverages existing T-SQL commands. Let’s start by creating a new login called Dogbert. Execute the code below in a SQL query notebook.
--
-- 1 - create a login
--
-- Which database?
USE master;
GO
-- Drop login
DROP LOGIN [Dogbert]
-- Create login
CREATE LOGIN [Dogbert] WITH PASSWORD = 'sQer9wEBVGZjQWjd', DEFAULT_DATABASE = mssqltips;
GO
-- Show logins
SELECT * FROM sys.sql_logins
GO
The next step is to create a user for each database and grant access to the database. The code below grants Dogbert access to the saleslt database.
--
-- 2 - give rights to Dogbert – sales database
--
-- Which database?
USE saleslt;
GO
-- Create user
CREATE USER [Dogbert] FROM LOGIN [Dogbert];
GO
-- Give read rights
ALTER ROLE db_datareader ADD MEMBER [Dogbert];
GO
We get a login issue if we try to access the stocks database right now. Execute the above code for the stocks database.

The next error is that the CREDENTIAL for the parquet files that comprise the managed table is missing.

The code below creates a wild card credential for the snp500 directory. This T-SQL command uses a Shared Access Signature (SAS). Please use the hyperlink to learn more about how to create one. Unlike storage account access keys, a SAS can be limited in scope and duration. Make sure to set the expiration date for at least six months out. Remember to rotate the key before it expires.
--
-- 3 - Hard code for synapse managed table
--
-- Which database?
USE master;
-- Create credential
CREATE CREDENTIAL [https://sa4synapse.dfs.core.windows.net/sc4synapse/synapse/workspaces/wsn4synapse/warehouse/stocks.db/snp500/*.parquet]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sp=rle&st=2024-02-04T17:37:12Z&se=2025-02-05T01:37:12Z&spr=https&sv=2022-11-02&sr=c&sig=
The last thing to do is to execute a while loop to process the T-SQL statements. Remember, cursors are not supported in the SQL pool syntax.
--
-- 5 - Use while loop to exec cmds
--
-- count statements
DECLARE @N INT = (SELECT COUNT(*) FROM [control_card].[sqlstmts_2_exec]);
-- set counter
DECLARE @I INT = 1;
-- while there is work ...
WHILE @I <= @N
BEGIN
-- drop credential
DECLARE @sql_code1 NVARCHAR(4000) = (SELECT drop_credential FROM [control_card].[sqlstmts_2_exec] WHERE rid = @I);
EXEC sp_executesql @sql_code1;
-- create credential
DECLARE @sql_code2 NVARCHAR(4000) = (SELECT create_credential FROM [control_card].[sqlstmts_2_exec] WHERE rid = @I);
EXEC sp_executesql @sql_code2;
-- grant access
DECLARE @sql_code3 NVARCHAR(4000) = (SELECT grant_access FROM [control_card].[sqlstmts_2_exec] WHERE rid = @I);
EXEC sp_executesql @sql_code3;
-- increment counter
SET @i +=1;
END;
GO
The next step is to validate that the credentials were applied to tables in the saleslt database. The screenshot below shows a select top one thousand query generated by SSMS.

Granting access to standard security users is more complex. It involves server logins, database users, database rights, and file credentials. The hardest part is assigning a credential to each directory and/or file. However, we demonstrated that it could be done for both managed and unmanaged tables created by the Apache Spark Engine.
Summary
Many companies are creating data lakes in the Azure Cloud. It can be expensive to leave a Spark cluster running 24 hours a day for reporting needs. One way to reduce this cost is to use Azure Synapse Serverless Pools.
Azure Synapse supports the concept of a lake database, which is defined by either Spark Hive Tables or Common Data Model exports. We focused on both managed tables placed in the service storage and unmanaged tables kept in general storage. The Apache Spark engine was used to create tables using both weak and strong file types. Regardless of table type, access to both the Synapse Service and Data Lake Storage is required to query data.
Data Lake Storage requires two levels of access. The IAM layer has both a general role and a specific role related to storage. The ACL layer allows the architect to apply read, write, and execute permissions to both folders and files. Storage is key to any data lake!
The Azure Synapse Service has two layers of security. The first is the IAM layer that allows you into the workspace. The second gives you the right to work within the environment. There are two flavors of security that you can offer your end users. Microsoft Entra ID, formally Active Directory (AD) with Password, is common nowadays. However, older applications might require Standard SQL Security, meaning the administrator must manage server logins, database users, database rights, and file credentials. Regardless of the security you use, please use AD groups and/or database roles to reduce the total management cost.
Enclosed are the following artifacts to start your journey with Azure Synapse for Lake Databases: CSV files, Parquet files, SQL scripts, and Spark notebooks.
Next Steps
- Learn how to read delta tables from Azure Data Factory
