Problem
I’ve taken SQL Server advice from dozens of people over the years, many of whom I’ve linked to in previous articles. On several occasions, I’ve heard that using OPTION RECOMPILE on simple statements can cause excessive CPU usage if a query runs frequently. This claim has always piqued my curiosity. I’ve taken this claim at face value for a while, but recently, I wanted to revisit it and see if it still holds true. Maybe the claim was valid in their environment in the past, but does it still apply today? Let’s find out together.
Solution
In this article, I’ll explore what OPTION RECOMPILE does and when you might want to use it. We’ll also discuss which performance metrics you can monitor to observe its effects. Then, we’ll focus on whether using OPTION RECOMPILE on a simple, frequently executed query causes excessive CPU usage due to plan recompilation. By the end, you’ll know when to use a recompile hint and whether there are major side effects.
Exploring OPTION RECOMPILE
A good start is understanding what OPTION RECOMPILE does in SQL Server. Microsoft defines OPTION RECOMPILE as a query hint that tells the SQL Server database engine to generate a new, temporary plan for the query and immediately discard it after the query finishes.
SQL Server generates an execution plan during the optimization phase of the query execution. When building a plan, SQL Server considers objects like indexes, statistics, and query hints. By default, SQL Server tries to cache and reuse the plan for efficiency. Sometimes, you don’t want to reuse the same plan, and that’s where adding the hint OPTION RECOMPILE comes in. You can apply this hint to individual statements within a query or recompile the entire stored procedure.
Why Recompile?
You might want to use the OPTION RECOMPILE hint for a few reasons. Let’s consider two common scenarios.
Parameter Sniffing
You’ve likely heard of parameter sniffing and maybe even suffered from its effects. Here’s a quick rundown: When SQL Server caches an execution plan, it uses the first set of parameters passed in. On the next runs, SQL Server reuses the values. The problem arises when parameter values change significantly between executions.
Take a date range as an example. Let’s say the first time you run a query, you pass in a range from January 1, 2024, to January 7, 2024—just seven days. However, the next time you run the query, imagine passing in a wider range from January 1, 2024 through January 7, 2025. Based on those new values, it might be better for SQL Server to create a new plan.
One way to combat parameter sniffing is to use OPTION RECOMPILE. Since the engine generates a new plan on each execution, it optimizes the plan to fit the parameter values better.
Skewed Data
Someone could argue that skewed data is the same as parameter sniffing, and I wouldn’t say they were wrong. I tend to think of it a little differently though. Skewed data refers to the uneven distribution of data. For example, imagine you have a sales table with one million rows. You have 500 salespeople, but only 10 produce the most sales orders. Those 10 highly motivated salespeople skew the records.
If you supply the salesperson in the WHERE clause, SQL Server will likely generate different plans when comparing the two groups or use parallelism for the one with more data. In many cases, OPTION RECOMPILE may not fix issues with skewed data; something like OPTIMIZE FOR or dynamic SQL might be better.
Downside of OPTION RECOMPILE
The downside I often hear about when overusing OPTION RECOMPILE is increased CPU usage. Since SQL Server doesn’t cache the plan, recompiling is CPU-intensive. It’s important to note that SQL Server does not cache the plan when we use OPTION RECOMPILE. I’ve heard people say SQL Server caches but creates a new plan for each execution. That’s untrue.
If you have multiple statements that use the same plan, the ones without the recompile option can’t reuse a plan that doesn’t exist.
Demo Dataset
Now, let’s build a dataset that captures the additional CPU load of OPTION RECOMPILE. I’ll create a database and a table with three million rows. We’ll also create a stored procedure that returns the count of sales orders.
-- https://www.mssqltips.com
USE [master];
GO
IF DB_ID('RethinkRecompileDemo') IS NOT NULL
BEGIN
ALTER DATABASE RethinkRecompileDemo
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
DROP DATABASE RethinkRecompileDemo;
END;
GO
CREATE DATABASE RethinkRecompileDemo;
ALTER DATABASE RethinkRecompileDemo SET RECOVERY SIMPLE;
GO
USE RethinkRecompileDemo;
GO
CREATE TABLE dbo.SalesOrders
(
SalesOrderId INT IDENTITY(1, 1) NOT NULL,
OrderDate DATETIME NOT NULL,
CustomerId INT NOT NULL,
SalesPersonId INT NOT NULL,
TotalAmount DECIMAL(10, 2) NOT NULL,
OrderStatus VARCHAR(50) NOT NULL,
CreateDate DATETIME NOT NULL
DEFAULT GETDATE(),
CONSTRAINT PK_SalesOrders_Id
PRIMARY KEY CLUSTERED (SalesOrderId)
);
GO
;WITH cteN (Number)
AS (SELECT TOP 3000000
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
INSERT INTO dbo.SalesOrders
(
OrderDate,
CustomerId,
SalesPersonId,
TotalAmount,
OrderStatus
)
SELECT DATEADD(DAY, RAND(CHECKSUM(NEWID())) * (1 + 1095), '2020-01-01') AS OrderDate,
ABS(CHECKSUM(NEWID()) % 5000) + 1 AS CustomerId,
CASE
WHEN RAND(CHECKSUM(NEWID())) < 0.75 THEN
ABS(CHECKSUM(NEWID()) % 50) + 1
ELSE
ABS(CHECKSUM(NEWID()) % 450) + 51
END AS SalesPersonId,
ABS(CHECKSUM(NEWID()) % 500) + 150 AS TotalAmount,
CASE
WHEN RAND(CHECKSUM(NEWID())) < 0.10 THEN
'New'
WHEN RAND(CHECKSUM(NEWID())) < 0.20 THEN
'In process'
ELSE
'Shipped'
END AS OrderStatus
FROM cteN n;
GO
CREATE NONCLUSTERED INDEX [IX_OrderDate+SalesPersonId+TotalAmount]
ON [dbo].[SalesOrders] ([OrderDate])
INCLUDE
(
[SalesPersonId],
[TotalAmount]
);
GO
CHECKPOINT;
GOSmall Scale Test
Now that we have our dataset, let’s look at a stored procedure that runs often in our sandbox environment. All we do with the stored procedure below is return a count of sales orders grouped by the salesperson and order date. Notice that I’m using the SalesDate column as a predicate in the WHERE clause.
-- mssqltips.com
CREATE OR ALTER PROCEDURE dbo.GetSalesCounts
@startDate DATETIME,
@endDate DATETIME
AS
SELECT COUNT(1) AS SalesOrderCount,
SalesPersonId,
OrderDate,
OrderStatus
FROM dbo.SalesOrders
WHERE OrderDate >= @startDate
AND OrderDate <= @endDate
GROUP BY SalesPersonId,
OrderDate,
OrderStatus;
GOUsers often want to see data for a single day or a week, but sometimes they request several years’ worth of data.
-- mssqltips.com
EXECUTE dbo.GetSalesCounts
@startDate = '01-01-2020',
@endDate = '01-01-2020'
GOThe query above is only for one day and returns the data in around 7ms. The execution plan is below.
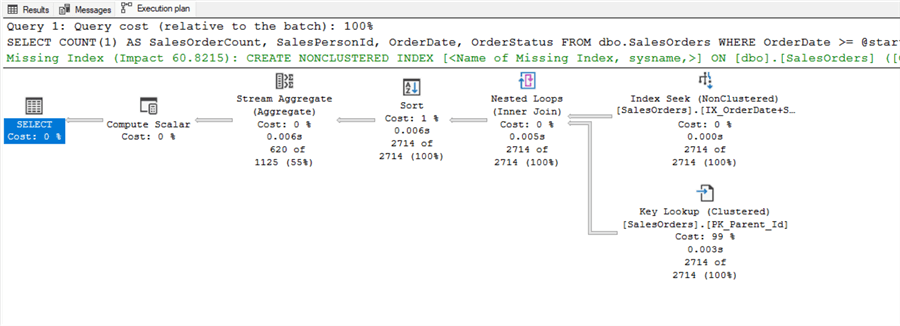
If we run the same stored procedure but request several years of data, our performance will be less than stellar because SQL Server reuses the same execution plan from above.
-- mssqltips.com
EXECUTE dbo.GetSalesCounts
@startDate = '01-01-2020',
@endDate = '01-01-2024';
GO
Ideally, SQL Server would use parallelism and choose different operators. One way to address this is by adding OPTION RECOMPILE inside the stored procedure or as a query hint. Since our stored procedure only has one statement, I’ll add a hint to the procedure, which will help later with testing.
-- mssqltips.com
EXECUTE dbo.GetSalesCounts
@startDate = '01-01-2020',
@endDate = '01-01-2024' WITH RECOMPILE;
GO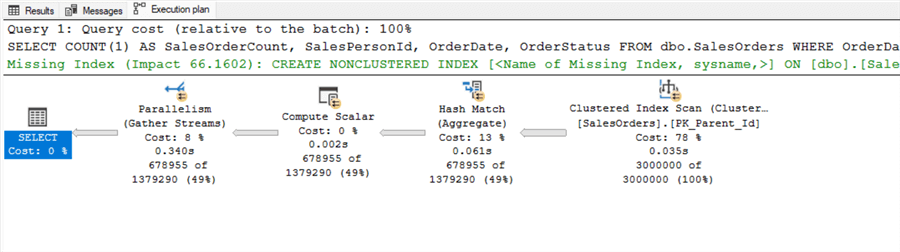
The execution plan now looks better, with the optimizer choosing parallelism and performing a clustered index scan. However, what is the CPU cost of using the WITH RECOMPILE hint?
Let’s measure a single execution of this procedure with and without the recompile hint. Since users typically view a narrow period, let’s focus on that scenario. This plan is already in cache and took about 5ms of CPU time. The parse and compile time didn’t register.
-- mssqltips.com
SET STATISTICS TIME, IO ON;
EXECUTE dbo.GetSalesCounts
@startDate = '01-01-2020',
@endDate = '01-01-2020'
SET STATISTICS TIME, IO OFF;
Now, let’s run the stored procedure again, add the WITH RECOMPILE hint, and see what happens.
-- mssqltips.com
SET STATISTICS TIME, IO ON;
EXECUTE dbo.GetSalesCounts
@startDate = '01-01-2020',
@endDate = '01-01-2020' WITH RECOMPILE
SET STATISTICS TIME, IO OFF;
From the screenshot above, we added a tiny bit to the parse and compile time, which increased the overall execution time. However, I’ll need to run this on a larger scale to see if recompiling causes CPU issues.
Monitor CPU Usage
I’ll use Windows Performance Monitor (Perfmon) to monitor CPU usage, including the [% Processor Time] counter. I’ll also use a data collector to save the results as a CSV file and analyze the data in Excel. To ensure valid results, there was no other activity on my virtual server during the test. I’ve included the Perfmon settings below.

Testing with SQLQueryStress
SQLQueryStress is one of my favorite tools for testing queries in SQL Server. It’s a lightweight and powerful tool for simulating concurrent query execution. The screenshot below shows the settings I used when running SQLQueryStress:
- Number of iterations: 100
- Number of threads: 10
- Delay between queries: 500ms
The settings simulate a workload with 10 concurrent users, each executing the query 100 times and a half-second delay between executions. Additionally, I used parameter substitution for the start and end dates to generate a wide variety of date ranges.

After gathering the initial performance metrics, I reran the experiment using WITH RECOMPILE in SQLQueryStress. Now that I’ve collected the data, let’s see how the numbers look.
The Verdict
Going into this experiment, I expected a significantly greater average CPU usage with the recompile option, even with a simple query. However, the results from the table and chart below show little difference between executions. I ran this test more than a dozen times and got roughly the same results.

| Options | Average CPU | Maximum CPU |
|---|---|---|
| No – Recompile | 31% | 39% |
| Recompile | 30% | 39% |
Limitations
There are certainly limitations to my experiment. For one, this test used a single query with a relatively small plan that doesn’t require much time for the optimizer to generate. A more complex plan would likely take longer to build, leading to higher CPU usage on the recompile. Additionally, most SQL Servers don’t have a single query running in isolation. Given these limitations, I can only draw limited conclusions from this test. Perhaps in a future article, I’ll look at more complex plans.
Clean Up
Don’t forget to drop the demo database once you’re done. Also, don’t be like me and leave Perfmon running.
-- mssqltips.com
USE [master];
GO
SET NOCOUNT ON;
IF EXISTS (SELECT 1 FROM sys.databases WHERE name = 'RethinkRecompileDemo')
BEGIN
ALTER DATABASE RethinkRecompileDemo SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RethinkRecompileDemo;
END;
GOKey Points
- When you suffer from parameter sniffing issues, using OPTION RECOMPILE at the statement or stored procedure level is a valid remedy, especially for simple queries.
- For simple execution plans, there doesn’t appear to be much overhead associated with recompiling the plan. However, the size and time required will increase if several tables are involved.
- Recompiling might be the easiest solution if you notice stored procedures taking longer to execute based on the supplied parameters. As always, test your code before deploying it to production.
Next Steps
- Interested in learning more about testing queries and stored procedures with SQLQueryStress? I wrote the article “Getting Started with SqlQueryStress for SQL Server Load Testing” to help you get started.
- Erik Darling’s article, “Is RECOMPILE Really That Bad For SQL Server Query Performance?” is a great read. If you’re interested in learning more about RECOMPILE, check it out.
- Trying to determine if your plans take too long to compile? Grant Fritchey outlines all the places you can check in his article “Query Compile Time.“
