By: Dattatrey Sindol | Comments | Related: More > Big Data
Problem
I have read the previous tips in the Big Data Basics series including the storage (HDFS) and computation (MapReduce) aspects. After reading through those tips, I understand that HDFS and MapReduce are the core components of Hadoop. Now, I want to know about other components that are part of the Hadoop Ecosystem.
Solution
In this tip we will take a look at some of the other popular Apache Projects that are part of the Hadoop Ecosystem.
Hadoop Ecosystem
As we learned in the previous tips, HDFS and MapReduce are the two core components of the Hadoop Ecosystem and are at the heart of the Hadoop framework. Now it's time to take a look at some of the other Apache Projects which are built around the Hadoop Framework which are part of the Hadoop Ecosystem. The following diagram shows some of the most popular Apache Projects/Frameworks that are part of the Hadoop Ecosystem.
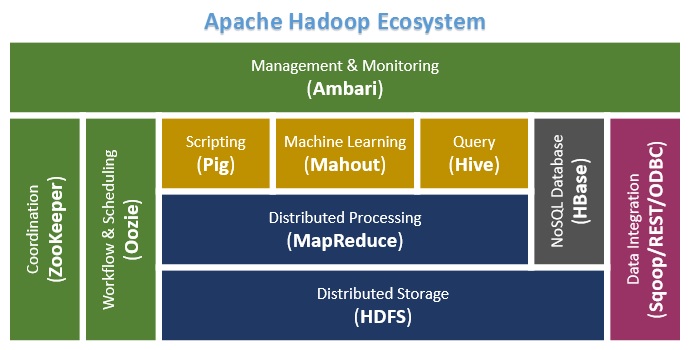
Next let us get an overview of each of the projects represented in the above diagram.
Apache Pig
Apache Pig is a software framework which offers a run-time environment for execution of MapReduce jobs on a Hadoop Cluster via a high-level scripting language called Pig Latin. The following are a few highlights of this project:
- Pig is an abstraction (high level programming language) on top of a Hadoop cluster.
- Pig Latin queries/commands are compiled into one or more MapReduce jobs and then executed on a Hadoop cluster.
- Just like a real pig can eat almost anything, Apache Pig can operate on almost any kind of data.
- Hadoop offers a shell called Grunt Shell for executing Pig commands.
- DUMP and STORE are two of the most common commands in Pig. DUMP displays the results to screen and STORE stores the results to HDFS.
- Pig offers various built-in operators, functions and other constructs for performing many common operations.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache Hive
Apache Hive Data Warehouse framework facilitates the querying and management of large datasets residing in a distributed store/file system like Hadoop Distributed File System (HDFS). The following are a few highlights of this project:
- Hive offers a technique to map a tabular structure on to data stored in distributed storage.
- Hive supports most of the data types available in many popular relational database platforms.
- Hive has various built-in functions, types, etc. for handling many commonly performed operations.
- Hive allows querying of the data from distributed storage through the mapped tabular structure.
- Hive offers various features, which are similar to relational databases, like partitioning, indexing, external tables, etc.
- Hive manages its internal data (system catalog) like metadata about Hive Tables, Partitioning information, etc. in a separate database known as Hive Metastore.
- Hive queries are written in a SQL-like language known as HiveQL.
- Hive also allows plugging in custom mappers, custom reducers, custom user-defined functions, etc. to perform more sophisticated operations.
- HiveQL queries are executed via MapReduce. Meaning, when a HiveQL query is issued, it triggers a Map and/or Reduce job(s) to perform the operation defined in the query.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache Mahout
Apache Mahout is a scalable machine learning and data mining library. The following are a few highlights of this project:
- Mahout implements the machine learning and data mining algorithms using MapReduce.
- Mahout has 4 major categories of algorithms: Collaborative Filtering, Classification, Clustering, and Dimensionality Reduction.
- Mahout library contains two types of algorithms: Ones that can run in local mode and the others which can run in a distributed fashion.
- More information on Algorithms: Mahout Algorithms.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache HBase
Apache HBase is a distributed, versioned, column-oriented, scalable and a big data store on top of Hadoop/HDFS. The following are a few highlights of this project:
- HBase is based on Google's BigTable concept.
- Runs on top of Hadoop and HDFS in a distributed fashion.
- Supports Billions of Rows and Millions of Columns.
- Runs on a cluster of commodity hardware and scales linearly.
- Offers consistent reads and writes.
- Offers easy to use Java APIs for client access.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache Sqoop
Apache Sqoop is a tool designed for efficiently transferring the data between Hadoop and Relational Databases (RDBMS). The following are a few highlights of this project:
- Sqoop can efficiently transfer bulk data between HDFS and Relational Databases.
- Sqoop allows importing the data into HDFS in an incremental fashion.
- Sqoop can import and export data to and from HDFS, Hive, Relational Databases and Data Warehouses.
- Sqoop uses MapReduce to import and export of data thereby effectively utilizing the parallelism and fault tolerance features of Hadoop.
- Sqoop offers a command line commonly referred to as Sqoop command line.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache Oozie
Apache Oozie is a job workflow scheduling and coordination manager for managing the jobs executed on Hadoop. The following are a few highlights of this project:
- Oozie can include both MapReduce as well as Non-MapReduce jobs.
- Oozie is integrated with Hadoop and is an integral part of the Hadoop Ecosystem.
- Oozie supports various jobs out of the box including MapReduce, Pig, Hive, Sqoop, etc.
- Oozie jobs are scheduled/recurring jobs and are executed based on scheduled frequency and availability of data.
- Oozie jobs are organized/arranged in a Directed Acyclic Graph (DAG) fashion.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache ZooKeeper
Apache ZooKeeper is an open source coordination service for distributed applications. The following are a few highlights of this project:
- ZooKeeper is designed to be a centralized service.
- ZooKeeper is responsible for maintaining configuration information, offering coordination in a distributed fashion, and a host of other capabilities.
- ZooKeeper offers necessary tools for writing distributed applications which can coordinate effectively.
- ZooKeeper simplifies the development of distributed applications.
- ZooKeeper is being used by some of the Apache projects like HBase to offer high availability and high degree of coordination in a distributed environment.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Apache Ambari
Apache Ambari is an open source software framework for provisioning, managing, and monitoring Hadoop clusters. The following are few highlights of this project:
- Ambari is useful for installing Hadoop services across different nodes of the cluster and handling the configuration of Hadoop Services on the cluster.
- Ambari offers centralized management of the cluster including configuration and re-configuration of services, starting and stopping of cluster and a lot more.
- Ambari offers a dashboard for monitoring the overall health of the cluster.
- Ambari offers alerting and email mechanism to get the required attention when required.
- Ambari offers REST APIs to developers for application integration.
Additional Information: Home Page | Wiki | Documentation/User Guide/Reference Manual | Mailing Lists
Conclusion
These are some of the popular Apache Projects. Apart from those, there are various other Apache Projects that are built around the Hadoop framework and have become part of the Hadoop Ecosystem. Some of these projects include
- Apache Avro - An open source framework for Remote procedure calls (RPC) and data serialization and data exchange
- Apache Spark - A fast and general engine for large-scale data processing
- Apache Cassandra - A Distributed Non-SQL Big Data Database
References
- Respective Apache Project sites listed above.
- For latest and up to date information, visit http://hadoop.apache.org.
Next Steps
- Explore more about Big Data and Hadoop.
- Explore more about various Apache Projects.
- Check out my previous tips






About the author
 Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.
Dattatrey Sindol has 8+ years of experience working with SQL Server BI, Power BI, Microsoft Azure, Azure HDInsight and more.This author pledges the content of this article is based on professional experience and not AI generated.
View all my tips
