Problem
Modeling a document database schema is one of the most challenging and important aspects of the data design process. There is a common misconception that document databases have no schema. Document databases do not require any predefined schema, nevertheless, in order to build a good data store, we always need to plan how we are going to organize the data. Properly designed data models will drastically impact application performance.
Solution
There are many different approaches and things to consider during document database modeling. To choose the best, we need to think which field will serve as document id, how to partition data, what are the queries that we want to run against the dataset, what are the data change patterns or whether the relationship between entities is one-to-one, one-to-many or many-to-many.
Document modeling examples
In the below example, I will take two one-to-many data entities, “devices” (laptop, PC, cellphone) and device “owners”. There can be only 1 owner of each device and “owners” have multiple devices. We can model this data in many ways, let’s take a look at 3 examples.
1 – Embedding child entity into Parent entity
This approach's downside is that it will not scale. The number of devices can grow, and we can potentially hit the database document size limit then we will not be able to add any more devices.
{"ownerId":77,
"name": "Maria",
"lastName": "Zakourdaev",
"devices": [
{"deviceType":"pc",
"deviceId":"9e242a82-6899-447d-b15e-7f8167a79de1
"macAddress": "2da8bfac-beb3-4b98-8812-87d55dc0fc4b",
"os":"windows"}
{"deviceType":"laptop",
"deviceId":"ef202317-f914-4737-81b3-80f089646669
"macAddress": "ebe073c8-a7ba-4df3-98d4-9d76547e3a9f",
"os":"apple" }
}
2 – Embed parent entity inside Child entity
In this design, we store the same owner's information multiple times which heavily expands our dataset.
{"deviceId": "9e242a82-6899-447d-b15e-7f8167a79de1",
"ownerName":"Maria",
"ownerLastName":"Zakourdaev",
"schemaType":"devices",
"deviceType":"laptop",
"macAddress": "2da8bfac-beb3-4b98-8812-87d55dc0fc4b",
"os":"apple"
}3 -“Single table” Design
This is my favorite approach. It's about keeping different types of entities in the same "table" or "container". This gives us an ability, similar to a join operation in relational schema, to get multiple entities in one request.
In the below example we will have 2 different document types, one for “owners” and another one for “devices”.
{"ownerId":77,
"schemaType":"owners",
"name": "Maria",
"lastName": "Zakourdaev"}
{"ownerId":77,
"deviceId":"ef202317-f914-4737-81b3-80f089646669",
"schemaType":"devices",
"deviceType":"pc",
"macAddress": "ebe073c8-a7ba-4df3-98d4-9d76547e3a9f",
"os":"windows"}
{"ownerId":77,
"deviceId":"9e242a82-6899-447d-b15e-7f8167a79de1",
"schemaType":"devices",
"deviceType":"laptop",
"macAddress": "2da8bfac-beb3-4b98-8812-87d55dc0fc4b",
"os":"apple" }
}
The main benefit of single table design is the performance gain since in one query you can fetch all information for multiple entities, information about the owner and his devices. This data design is highly scalable, and data is not duplicated. Other benefits are less impactful, but still can be mentioned. Having multiple containers/tables brings all kinds of the operational overhead, like configuring monitoring, scale-up and down functions. There is a potential to lower cloud spending as you do not need to provision multiple capacity.
Potential Issue
Today, I want to address one issue that I have experienced when working with a dataset that contained several document types in one "table". I had to read the data from Azure CosmosDB using Azure Databricks. If you want to generate the data, here is a data generation script. I have generated 1 million devices and 1 owner document.
After pulling the data from the container, I could read only the fields from the "devices" entity – we can clearly see it from the error message where Spark provides me the list of available fields.
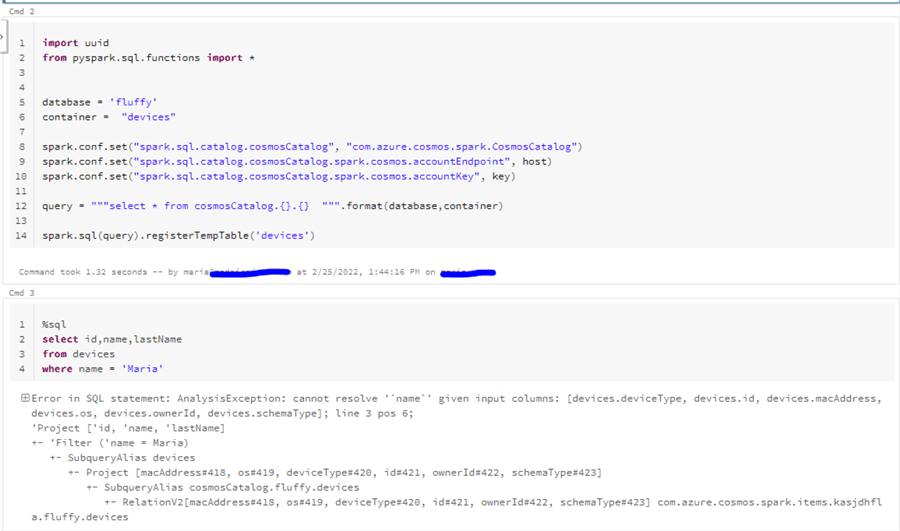
Any Spark dataset, called a DataFrame, has a structure called “Spark schema”. By default, Spark will infer the schema from the randomly sampled documents. If all of them happen to be from the “device” type, you will not get “owner” document type fields at all because Spark hasn't created a datatype mapping for it.
If I try to pull the document by id, I see only fields that exist in the “device” document schema. Spark is not able to read the rest of the fields because they do not exist in the sample documents that were analyzed.

Solving this problem
There are two possible solutions for this issue:
- We can manually declare Spark schema instead of using default sampling.
- We can also read the schema from sample data.
Solution 1
In this solution we will define the schema manually (Here you can read about schema definition). I need to add to the mapping all fields from all document types that I want to read.
cfg = {
"spark.cosmos.accountEndpoint" : host,
"spark.cosmos.accountKey" : key,
"spark.cosmos.database" : database,
"spark.cosmos.container" : container,
}
df_Schema = StructType([
StructField('id',StringType(),True),
StructField('ownerId',StringType(),True),
StructField('schemaType',StringType(),True),
StructField('deviceType',StringType(),True),
StructField('macAddress',StringType(),True),
StructField('os',StringType(),True),
StructField('name',StringType(),True),
StructField('lastname',StringType(),True)
])
spark.read.schema(df_Schema) .format("cosmos.oltp") .options(**cfg) .load() .createOrReplaceTempView("devices")

Now we have all needed fields.
Solution 2
If the document schema is long and complicated and we do not want to figure out the exact syntax for all nested structures that we might have in the document, I suggest to create a sample document that will contain all possible fields from all documents in our “single table”. We will build a dataframe on top of that document and will use StructType.fromJson to convert the dataframe into a schema mapping document.
example_doc = {
"id": "8e242a82-6899-447d-b15e-7f8167a79de1",
"ownerId": 77,
"schemaType": "devices",
"deviceType": "laptop",
"macAddress": "0da8bfac-beb3-4b98-8812-87d55dc0fc4b",
"os": "windows",
"name": "Maria",
"lastName": "Zakourdaev"
}
df = spark.createDataFrame([example_doc])
schemaFromJson = StructType.fromJson(json.loads(df.schema.json()))
spark.read.schema(schemaFromJson).format("cosmos.oltp").options(**cfg).load().createOrReplaceTempView("devices")

Again, we have all needed fields.
Next Steps
- What is Azure Databricks
- Introduction to Azure CosmosDB
- The What, why and when of Single-Table Design

Maria Zakourdaev is a Data Platform Microsoft MVP and a technology expert with more than 20 years of experience, a community leader with a profound knowledge of Microsoft products and services, while also being able to bring together diverse platforms, products, and solutions to solve real-world problems.
Maria has a hands-on experience managing various data management technologies in Azure, AWS and Google public cloud platforms, including SQL Server, Azure CosmosDB, AWS DynamoDB, MemSQL, MySQL, Postgresql, Snowflake, Redis, Amazon Redshift, Couchbase and Elasticsearch, Spark, Databricks, Big Query.
Maria is an organiser of the annual conference “Data TLV” ( ex “SQL Saturday Israel”), a free training event for any data professionals: http://datatlv.com.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2022 | Author Contender – 2022 | Rookie Contender – 2018