Problem
I know how to use pivot tables in Excel and need to know how to use PIVOT and UNPIVOT in Microsoft SQL Server in stored procedures and T-SQL scripts.
Solution
In this tutorial, we will take a look at different aspects of PIVOT and UNPIVOT to help you get a better understanding of how this works.
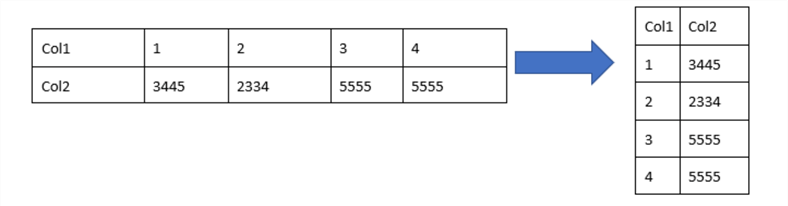
SQL PIVOT diagram
You can use PIVOT to rotate rows in a table by turning row values into multiple columns. The following diagram illustrates what PIVOT can do where we take 4 rows of data and turn this into 1 row with 4 columns. As you can see, the PIVOT process converts rows into columns by pivoting the table.

SQL UNPIVOT diagram
On the other hand, unpivot does the opposite and rotates multiple columns into multiple rows.
What coding problem does PIVOT and UNPIVOT solve in SQL Server?
Both, the PIVOT operator and UNPIVOT operator are usually used for reporting purposes when the user requires the information in a different format. However, sometimes, UNPIVOT is used to normalize the output of a query.
For example, imagine a table with data like this:
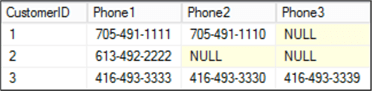
For a certain report, the desired output is actually as follows (apologies for the messy arrows):

For this scenario, you can refer to this article: Use SQL Server’s UNPIVOT operator to help normalize output.
Another scenario is when we want to export data and we need it in a different format and table structure. In those scenarios, we sometimes need to PIVOT or UNPIVOT data.
Why swap rows to columns and vice versa?
Most of the scenarios to swap rows to columns is to deliver a report with a specific format. The data analyst or someone in the company requires the information in a different way than the table structure. If it is a one-time requirement, a query can help. Otherwise, a view could be used.
How can you solve the problem without PIVOT?
In the past, before PIVOTs existence, these problems to PIVOT or UNPIVOT were solved with CURSORS. Cursors in SQL Server are not recommended because it consumes resources and is generally slow. However, if the table is not very big and you use cursors carefully, and not often, it can be an option.
Let’s take a look at an example SELECT statement. Let’s say that we have this SELECT query:
SELECT
[Group],
SUM([SalesYTD]) SalesYTD
FROM [Sales].[SalesTerritory]
GROUP BY [Group]The result set is the following:

And we want the information in this format:

Using a Cursor to Pivot the Data
To do that, we can create a table with data values of 0 in the table. Here is the syntax:
CREATE TABLE [dbo].[salesterritoryCursor](
[SalesYTD] [varchar](8) NOT NULL,
[Europe] [money] NULL,
[North America] [money] NULL,
[Pacific] [money] NULL
) ON [PRIMARY]
GO
INSERT INTO [dbo].[salesterritoryCursor] values ('SalesYTD',0,0,0)The cursor will go row by row and set the values of the group in the @group variable and the SalesYDT row value in the @salesytd variable. If the @group is Europe, then it will update the data in the Europe column, and if it is America in America and so on.
DECLARE @group as varchar(50)
DECLARE @salesytd as varchar(50)
DECLARE db_cursor CURSOR FOR
SELECT
[Group],
SUM([SalesYTD]) SalesYTD
FROM [Sales].[SalesTerritory]
GROUP BY [Group]
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @group,@salesytd
WHILE @@FETCH_STATUS = 0
BEGIN
--SELECT @group,@salesytd
IF trim(@group)='Europe'
BEGIN
UPDATE [dbo].[salesterritoryCursor]
SET [SalesYTD] = 'SalesYTD', [Europe] = Europe+@salesytd
END
ELSE if trim(@group)='North America'
BEGIN
UPDATE [dbo].[salesterritoryCursor]
SET [SalesYTD] = 'SalesYTD', [North America] = [North America]+@salesytd
END
ELSE
BEGIN
UPDATE [dbo].[salesterritoryCursor]
SET [SalesYTD] = 'SalesYTD', [Pacific] = pacific+@salesytd
END
FETCH NEXT FROM db_cursor INTO @group,@salesytd
END
CLOSE db_cursor
DEALLOCATE db_cursor
SELECT * FROM [dbo].[salesterritoryCursor]Use a CASE Statement to Pivot the Data
Another way would be to use a CASE statement to get aggregated data based on conditions.
The next example will show how a CASE statement can be used.
SELECT 'salesytd' salesytd,
SUM(CASE when [Group]='Europe' then SalesYTD else 0 end) as Europe,
SUM(CASE when [Group]='North America' then SalesYTD else 0 end) as [North America],
SUM(CASE when [Group]='Pacific' then SalesYTD else 0 end) as [Pacific]
FROM [Sales].[SalesTerritory]Use a CASE Statement and CTE to Pivot the Data
The following example uses the CASE statement with a CTE.
-- case statement example
;WITH CTE(Europe,[North America],Pacific)
as
(
SELECT
SUM(CASE when [Group]='Europe' then SalesYTD else 0 end),
SUM(CASE when [Group]='North America' then SalesYTD else 0 end),
SUM(CASE when [Group]='Pacific' then SalesYTD else 0 end)
FROM [Sales].[SalesTerritory]
)
SELECT * from CTEUnpivot the Data
To unpivot, we will create a table and then use this table to unpivot the data.
-- first pivot the data
;WITH CTE(Europe,[North America],Pacific)
as
(
Select
SUM(CASE when [Group]='Europe' then SalesYTD else 0 end),
SUM(CASE when [Group]='North America' then SalesYTD else 0 end),
SUM(CASE when [Group]='Pacific' then SalesYTD else 0 end)
From [Sales].[SalesTerritory]
)
SELECT *
into dbo.salesterritoryPivot2
from CTE
--to unpivot using the case statement use, the following code
SELECT 'Europe' as Region, (SELECT sum(Europe) FROM [dbo].[salesterritoryPivot2]) as salesytd
UNION
SELECT 'North America' as Region, (SELECT sum([North America]) FROM [dbo].[salesterritoryPivot2]) as salesytd
UNION
SELECT 'Pacific' as Region, (SELECT sum([Pacific]) FROM [dbo].[salesterritoryPivot2]) as salesytdWhat performance implications does PIVOT and UNPIVOT have?
The classic PIVOT and UNPIVOT commands are slow and consume a lot of resources. If the tables are not very big, you will not have a problem using them. The sorting process takes a lot of resources. An alternative is to use FOR XML PATH with the STUFF function. The following article, will provide you some tips about this topic: Using FOR XML PATH and STRING_AGG() to denormalize SQL Server data.
Examples of PIVOT
Let’s say that you have the following query.
SELECT
[Group],
SUM([SalesYTD]) SalesYTD
FROM [Sales].[SalesTerritory]
GROUP BY [Group]Using PIVOT we will use the following code. As you will see we have to know ahead of time what columns we want to pivot on. In the example below we specify [Europe], [North America], [Pacific]. There is no simple way to use PIVOT without knowing the values ahead of time.
SELECT 'SalesYTD' AS SalesYTD, [Europe], [North America], [Pacific]
FROM
(
SELECT SalesYTD, [Group]
FROM [Sales].[SalesTerritory]
) AS TableToPivot
PIVOT
(
SUM(SalesYTD)
FOR [Group] IN ([Europe], [North America], [Pacific])
) AS PivotTable; 
Example of UNPIVOT
The following code will unpivot the table.
SELECT territory, sales
FROM
(
SELECT
[Europe]
,[North America]
,[Pacific]
FROM [dbo].[salesterritoryPivot]
) p
UNPIVOT
(
sales for territory IN
([Europe],[North America],[Pacific])
) AS upvt;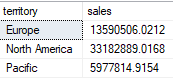
Example of Dynamic PIVOT
Dynamic pivot is also another interesting option. As mentioned above, you need to know what values you are pivoting on ahead of time, but with this example a query determines the values dynamically.
Here is an example of the data we have been working with.
SET @columns = N'';
SELECT @columns += N', p.' + QUOTENAME([Group])
FROM (SELECT p.[Group] FROM [Sales].[SalesTerritory] AS p GROUP BY p.[Group]) AS x;
SET @sql = N'
SELECT ' + STUFF(@columns, 1, 2, '') + '
FROM
(
SELECT [Group], SalesYTD FROM [Sales].[SalesTerritory]
) AS j
PIVOT
(
SUM(SalesYTD) FOR [Group] IN ('
+ STUFF(REPLACE(@columns, ', p.[', ',['), 1, 1, '')
+ ')
) AS p;';
PRINT @sql;
EXEC sp_executesql @sql;Here is another example.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
SET @columns = N'';
SELECT @columns += N', p.' + QUOTENAME(Name)
FROM (SELECT p.Name FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
GROUP BY p.Name) AS x;
SET @sql = N'
SELECT ' + STUFF(@columns, 1, 2, '') + '
FROM
(
SELECT p.Name, o.Quantity
FROM dbo.Products AS p
INNER JOIN dbo.OrderDetails AS o
ON p.ProductID = o.ProductID
) AS j
PIVOT
(
SUM(Quantity) FOR Name IN ('
+ STUFF(REPLACE(@columns, ', p.[', ',['), 1, 1, '')
+ ')
) AS p;';
PRINT @sql;
EXEC sp_executesql @sql;For more about dynamic pivot in the above query refer to the following link: Script to create dynamic PIVOT queries in SQL Server.
Key Takeaways
- The tutorial explains how to use SQL PIVOT and SQL UNPIVOT to transform data in Microsoft SQL Server.
- PIVOT turns rows into columns for reporting, while UNPIVOT does the opposite by converting columns into rows.
- The article discusses performance implications of using PIVOT and UNPIVOT, noting they can be resource-intensive.
- It also outlines alternative methods, such as using CURSORS and CASE statements for data manipulation.
- Examples of static and dynamic PIVOT and UNPIVOT are provided to illustrate their usage.
Next Steps
If you want to learn more please refer to the following links:
- Use SQL Server’s UNPIVOT operator to dynamically normalize output
- How To Use the Unpivot Data Flow Transform in SQL Server Integration Services SSIS
- SQL Server Window Aggregate Functions SUM, MIN, MAX and AVG
- SQL Aggregate Functions in SQL Server, Oracle and PostgreSQL
- SQL Server Data Types Quick Reference Guide

Daniel Calbimonte is a Microsoft Most Valuable Professional, Microsoft Certified Trainer and Microsoft Certified IT Professional for SQL Server. He is an accomplished SSIS author, teacher at IT Academies and has over 10 years of experience as a QE and developer for SQL Server related software. He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs.
- MSSQLTips Awards: Author of the Year Contender – 2015-2018, 2022, 2023 | Champion (100+ tips) – 2018



I really enjoyed this post about the PIVOT function! For anyone eager to learn more about dynamic pivoting and effective data reporting, I recommend checking out FinalException’s article at https://finalexception.com/how-to-pivot-data-in-sql-server-for-efficient-data-reporting/. It offers valuable techniques that complement what you’ve shared here!
Appreciate your time
thank you
Aubrey,
Thank you so much for this clear, simple example. This is exactly what I needed.
Pablo
Pablo,
Yes, you can create a pivot on a table without using an aggregate in SQL Server, and yes, you will need to use CASE.
Here’s an example:
CREATE TABLE sourceTable (sku nvarchar(5), brandid nvarchar(5), barcode nvarchar(50) )
INSERT INTO sourceTable VALUES
(1,1,150),
(1,1,140),
(1,1,111),
(1,2,1234);
GO
SELECT *
FROM sourceTable;
GO
SELECT
t.Sku,
t.BrandId,
Barcode1 = MAX(CASE WHEN t.rn = 1 THEN t.Barcode END),
Barcode2 = MAX(CASE WHEN t.rn = 2 THEN t.Barcode END),
Barcode3 = MAX(CASE WHEN t.rn = 3 THEN t.Barcode END),
Barcode4 = MAX(CASE WHEN t.rn = 4 THEN t.Barcode END)
FROM
(
SELECT *,
rn = ROW_NUMBER() OVER (PARTITION BY t.Sku, t.BrandId ORDER BY t.Barcode)
FROM sourceTable t
) t
GROUP BY
t.Sku,
t.BrandId;
GO
At the beginning of the article, you have an example of pivoting data, not aggregate data (like SUM, COUNT, etc.). Then at the end of the article when you use the PIVOT function, you use SUM.
I need to pivot data, not aggregate data. Does PIVOT work that way or is it only for aggregate functions?
Should I use the CASE strategy?
Thanks!!