Problem
Aggregates are some of the most commonly used functions in all RDBMS, they are extremely useful for reports, calculations and in general to group and analyze data. Unfortunately, there are some differences between SQL Server, Oracle and PostgreSQL in the implementation of aggregate functions and group by.
Solution
In this SQL tutorial, we will explore the differences between the most used aggregate functions in SQL Server, Oracle and PostgreSQL. We will explore the differences and the various uses of these SQL statements. Since this topic is quite vast, this will be a two part series, this first an introduction and the second more advanced.
As always, we will use the GitHub freely downloadable database sample Chinook, as it is available in multiple RDBMS formats. It is a simulation of a digital media store, with some sample data, all you have to do is download the version you need and you have all the scripts for data structure and all the Inserts for data.
SQL Aggregate Functions
First of all, what is a aggregate function in a SQL database? The definition in official Microsoft documentation (and also PostgreSQL) is: "An aggregate function performs a calculation on a set of values, and returns a single value." I think this is the most concise and effective definition! In fact, if we do not use a GROUP BY clause the functions always return a single value, let’s look at a simple SELECT statement example with the COUNT function to determine how many Invoices we have in the invoice table:
select count(invoiceid) as num_invoices from Invoice

Very simple use in which we count the number of InvoiceId which is the PK of the table Invoice. We could have obtained the same result using COUNT(*), there are countless blog articles on which one of the two methods is best for performances: let’s say that for the scope of this tip they are almost equivalent.
If we add a GROUP BY, which is the common use of aggregate functions:
select cast(month(invoicedate) as varchar) + ' - ' + cast(year(invoicedate)as varchar) as month_year,
count(invoiceid) as num_invoices,
sum(total) as Total_amount
from Invoice
group by cast(month(invoicedate) as varchar) + ' - ' + cast(year(invoicedate)as varchar)

We have added here both a GROUP BY and another very used aggregate function: SUM(). The group by is done on a combination of two date operations on the InvoiceDate column, obtained extracting month and year of the date.
So far quite simple: both aggregations COUNT() and SUM()) are done for every month-year combination so that we have the number of invoices and the total invoice amount for every month year combination.
Now let’s introduce another important option in aggregations: the DISTINCT argument. That’s to say the possibility to aggregate based only on unique values, let’s do another example:
select count(distinct invoiceid) as Number_invoices,
count(invoiceid) as number_lines_invoices ,
count(invoicelineid) as number_invoice_lines
from invoiceline

As you can see using the DISTINCT argument applies the aggregate function only on unique values, pretty much as using DISTINCT in a SELECT clause, so even if we have a total of 2240 InvoiceIds in the InvoiceLine table, only 412 of them are unique.
Another massively used function is AVG() which obviously returns the mathematical average of a group of values, let’s do a quick example calculating the average amount of invoices, divided by year:
select year(invoicedate) as Year_invoice,
count(invoiceid) as num_invoices,
sum(total) as Total_amount, avg(total) as average_amount
from Invoice
group by year(invoicedate)

Last but not least in my personal list of the most useful and used aggregate functions are MIN() and MAX(), let’s see an example adding these two to the previous query:
select year(invoicedate) as Year_invoice,
count(invoiceid) as num_invoices,
sum(total) as Total_amount, -- sum function
avg(total) as average_amount, -- average value
min(total) as minimum_invoice_amount, -- minimum value
max(total) as maximum_invoice_amount -- maximum value
from Invoice
group by year(invoicedate)

Also, these two functions are quite simple as they are returning the minimum and maximum value within a group of values. Obviously these last two functions apply not only to numbers, but also to dates (or even strings), so that we can return the minimum and maximum in a group of date/time data types:
select min(InvoiceDate) as Min_InvoiceDate,
max(invoicedate) as Max_InvoiceDate
from Invoice

So far all quite simple, let’s see these functions in the other RDBMS.
Oracle Aggregate Functions
In Oracle we have the same approach with aggregate functions, even if the definition in official documentation is a little different: "Aggregate functions return a single result row based on groups of rows, rather than on single rows."
Let’s do the same examples as in SQL Server:
select count(invoiceid) as num_invoices from chinook.Invoice;

Exactly the same syntax and behavior, and also in Oracle we can use COUNT(*), pay attention that it is easy to encounter old Oracle syntax still using instead COUNT(1), please avoid doing that and stick to the ANSI syntax! Now we can add the GROUP BY clause:
select extract(month from invoicedate)||' - '||extract(year from invoicedate) as month_year,
count(invoiceid) as num_invoices,
sum(total) as Total_amount
from chinook.Invoice
group by extract(month from invoicedate)||' - '||extract(year from invoicedate);

Please notice the different use of date functions and the implicit conversion of numbers to varchar, refer to my tip on date functions: SQL Server, Oracle and PostgreSQL Date Functions.
Also, the result set is not ordered by the GROUP BY clause (in fact it should not!), so we need to explicitly order it:
select extract(month from invoicedate)||' - '||extract(year from invoicedate) as month_year,
count(invoiceid) as num_invoices,
sum(total) as Total_amount
from chinook.Invoice
group by extract(month from invoicedate)||' - '||extract(year from invoicedate)
order by month_year;

Remember also that, as in SQL Server, the ORDER BY is the last instruction in the query that is evaluated by the optimizer, thus it is possible to refer to an alias used in the query, such as month_year in our case.
So far the SELECT SUM() and COUNT() aggregations are working in the same way as in SQL Server, now we introduce the following example using the DISTINCT argument:
select count(distinct invoiceid) as Number_invoices,
count(invoiceid) as number_lines_invoices ,
count(invoicelineid) as number_invoice_lines
from chinook.invoiceline;

Again we have the same behavior as in SQL Server, let’s see now try with SELECT AVG():
select extract(year from invoicedate) as Year_invoice,
count(invoiceid) as num_invoices,
sum(total) as Total_amount,
avg(total) as average_amount
from chinook.Invoice
group by extract(year from invoicedate);

Here we have a small difference in the result as the returned data type in SQL Server for a decimal is limited to maximum 6 decimals numbers, while in Oracle we have a lot more decimals, but if we read in the documentation we found out that: "The function returns the same data type as the numeric data type of the argument."
In fact the returned data type is still NUMBER as the data type of Total column, but it has no precision so it is not a NUMBER(10,2) like the starting column but a NUMBER, so with all maximum values available in Oracle. This "problem" is not present on all other functions as the combination always retain the same data type with the same decimal numbers.
Now we take a look to MIN() and MAX() functions:
select extract(year from invoicedate) as Year_invoice,
count(invoiceid) as num_invoices,
sum(total) as Total_amount,
round(avg(total), 2) as average_amount,
min(total) as minimum_invoice_amount,
max(total) as maximum_invoice_amount
from chinook.Invoice
group by extract(year from invoicedate);

Please notice that I added a ROUND() with two decimal numbers to the average, in order to have the same format for all the columns.
Now the last example using a date data type:
select min(InvoiceDate) as Min_InvoiceDate,
max(invoicedate) as Max_InvoiceDate
from chinook.Invoice;

Please note that since we have not explicitly defined a date format in the query, the dates are returned with the system default NLS that reflects at session level, if not differently set. We can quickly check these parameters with the following query on a Dynamic Performance View:
SELECT * FROM V$NLS_PARAMETERS;

In which we see the default NLS_DATE_FORMAT, DD-MON-RR.
PostgreSQL Aggregate Functions
Let’s see now the same examples in PostgreSQL, starting with COUNT():
SELECT COUNT(*) FROM "Invoice";

Here we immediately notice a difference with SQL Server: COUNT() function always returns a BIGINT data type, instead SQL Server always returns an INT data type and if a return value exceeds the INT limit then it returns an error and COUNT_BIG() aggregation function should be used instead. Oracle always returns a NUMBER data type with no limits so in some way similar to PostgreSQL. By the way in this case we have used COUNT(*) in order to demonstrate that we have the same result.
Now we’ll take a look at the GROUP BY and SUM():
select extract(month from "InvoiceDate")||' - '||extract(year from "InvoiceDate") as month_year,
count("InvoiceDate") as num_invoices,
sum("Total") as total_amount
from "Invoice"
group by extract(month from "InvoiceDate")||' - '||extract(year from "InvoiceDate");

As in Oracle we ended up with a non-ordered result set, which is what we can expect since without a specific ORDER BY we cannot say that a result set is in any order!
select extract(month from "InvoiceDate")||' - '||extract(year from "InvoiceDate") as month_year,
count("InvoiceDate") as num_invoices,
sum("Total") as total_amount
from "Invoice"
group by extract(month from "InvoiceDate")||' - '||extract(year from "InvoiceDate")
order by month_year;

Noticed something different? In PostgreSQL the order is not the same as Oracle, and absolutely not what I would expect, as I’d thought that ‘1 -2009’ would be the first value, followed by the other ‘1 – ‘ as in Oracle and SQL Server (even if not explicitly ordered in this case).
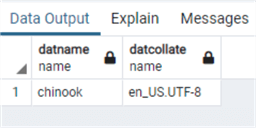
In fact, this is a matter of a different collation set at database level and how this reflects on the ORDER BY of string data types. We can dig a little bit in this topic, first of all let’s check the default collation of CHINOOK database:
select datname,
datcollate
from pg_database
where datname='chinook';
Now we apply to the ORDER BY clause another collation, using the COLLATE argument. Unfortunately, in order to do so we must explicitly cast to varchar the extracted date part, otherwise the optimizer is trying to apply the collation to a double precision data type, resulting in an error:
select cast(extract(month from "InvoiceDate") as text)||' - '||cast(extract(year from "InvoiceDate") as text) collate "C" as month_year,
count("InvoiceDate") as num_invoices,
sum("Total") as total_amount
from "Invoice"
group by cast(extract(month from "InvoiceDate") as text)||' - '||cast(extract(year from "InvoiceDate") as text) collate "C"
order by month_year;

Now we have the same behavior as in SQL Server and Oracle, I’ve used the C default collation: for more info regarding collations in PostgreSQL please refer to the official documentation.
At this point we can see the DISTINCT clause:
select count(distinct "InvoiceId") as Number_invoices,
count("InvoiceId") as number_lines_invoices ,
count("InvoiceLineId") as number_invoice_lines
from "InvoiceLine";

In this case nothing different from the other two RDBMS. Now we can finally look at the AVG() function:
select extract(year from "InvoiceDate") as Year_invoice,
count("InvoiceId") as num_invoices,
sum("Total") as Total_amount,
avg("Total") as average_amount
from "Invoice"
group by extract(year from "InvoiceDate");
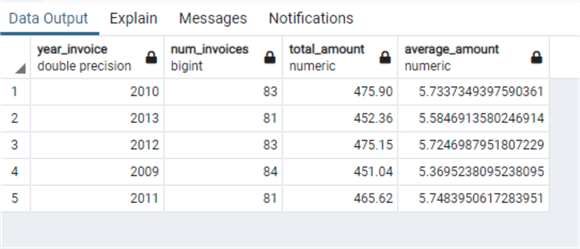
Here we have a similar behavior as the one of Oracle with no limits (or greater limits) to decimal numbers.
Let’s take a look at MIN() and MAX():
select extract(year from "InvoiceDate") as Year_invoice,
count("InvoiceId") as num_invoices,
sum("Total") as Total_amount,
round(avg("Total"), 2) as average_amount,
min("Total") as minimum_invoice_amount,
max("Total") as maximum_invoice_amount
from "Invoice"
group by extract(year from "InvoiceDate");

As in Oracle I’ve added a ROUND to 2 decimal numbers on the AVG() function in order to have the same number format on all columns.
Finally we can check how the MIN() and MAX() work with dates in PostgreSQL:
select min("InvoiceDate") as Min_InvoiceDate,
max("InvoiceDate") as Max_InvoiceDate
from "Invoice";
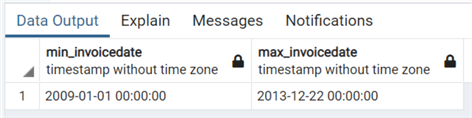
As we can see also with date data type, we have the same expected result as in the other two RDBMS.
Conclusion
In this first part of the tip dedicated to aggregate functions, we have seen some of the most used and useful functions, as well as GROUP BY and DISTINCT. We have also learned some differences on results data types and ORDER BY.
Next Steps
- In next tip we will dig a little bit more on the topic, introducing the HAVING clause, the use of aggregates with OVER clause and the analytic functions topic, the different classifications of functions in Oracle etc. … so stay tuned!
- As always links to official documentation:
- SQL Server: SQL Server Aggregate Functions
- Oracle: Oracle Aggregate Functions
- PostgreSQL: PostgreSQL Aggregate Functions
- Links to other tips:

Andrea Gnemmi is a Database and Data Warehouse professional with almost 20 years of experience, having started his career in Database Administration with SQL Server 2000.
His expertise ranges from SQL Server to Oracle and Postgres for database administration and from SAP BO to SSIS, SSRS and Power BI regarding BI and ETL.
He has worked both in SQL Server and Oracle mostly in multinational environments with very high transaction volumes and large datasets. Performance tuning, indexing techniques and in general Database administration are his hot topics. Ensuring a 24/7 uptime of the various databases in shop is his main responsibility, as well as the best possible performances of all queries run on the databases. He has started working with PostgreSQL two years ago loving many of the features of this RDBMS.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2024 | Rookie of the Year – 2021