Problem
In a previous tip on SQL Server 2016 Features in CTP2, one of the new features introduced was PolyBase. Our organization is thinking of deploying Big Data solutions running on the Apache Hadoop platform and I wanted to know how I can use PolyBase to perform data analysis.
Solution
As a side effect of decreasing storage cost, data is no longer deleted, but rather archived for analytical purposes. So, whether we like it or not, we SQL Server professionals need to embrace the reality that Big Data and Hadoop solutions are here to stay and that we will eventually be required to work with them as part of our day-to-day responsibilities.
One of the features introduced in SQL Server 2016 is PolyBase. Historically, PolyBase is really not a new feature. It was first introduced in Microsoft’s massive parallel processing (MPP) appliance called SQL Server Parallel Data Warehouse (PDW.) PDW was originally from Microsoft’s acquisition of DATAllegro – a company that specialized in data warehousing appliances that rival that of Netezza.
When PDW was first introduced, it ran an MPP version of SQL Server 2008 R2. The goal of PolyBase is to make interacting with unstructured, semi-structured and non-relational data stored in Hadoop as easy as writing Transact-SQL statements.
The Challenge with Hadoop: How PolyBase Bridges the Gap for the SQL Server Professional
Apache Hadoop was originally designed with the Linux environment in mind. That means working with Hadoop data required knowing how to work with Linux and writing MapReduce jobs using the Java programming language. Being a SQL Server professional, the only world I’m familiar with is one that runs the Windows operating system with Transact-SQL being the programming language of choice.
While SQL-like languages for Hadoop like Hive’s HiveQL, Pivotal’s HAWQ , and Teradata’s SQL-H were developed for this purpose, the fact still remains that you need to learn a bit of Linux to interact with the Hadoop data thru HiveQL.
PolyBase in PDW (which was eventually renamed Analytics Platform System) enabled a SQL Server professional to work with Hadoop data using the familiar tools like SQL Server Management Studio, SQL Server Data Tools, Microsoft Office and Power BI with the Transact-SQL language and the included extensions. Having worked with Apache Hadoop running on the Linux operating system to perform data analysis, I know how challenging it is to try and perform tasks that seemed easy in Windows, but seemed daunting in Linux.
From the Cadillac to the Buick
Because PolyBase was formerly available only thru the Analytics Platform System (APS,) not every SQL Server professional can get their hands on them. Only those who can afford the price tag of an expensive MPP alliance will have the luxury of playing around with PolyBase.
SQL Server 2016’s inclusion of PolyBase meant that everyone who has access to the installation media can start interacting with Hadoop data using their existing skillset without the need to learn how to manage Hadoop clusters. Since SQL Server 2016 is still under community technology preview, we’re still not sure which editions will support the feature. We just have to wait until it is released to manufacturing (RTM). Rest assured that the licensing cost of an Enterprise Edition is way cheaper than that of a full blown MPP appliance.
PolyBase Architecture
Because PolyBase is designed to interact with Hadoop data, it is important to understand the underlying architecture that makes it work. We will reference the Hadoop architecture referenced in this previous tip to draw some parallels between Hadoop and PolyBase. Built with the clustering technology in mind, we will be referencing multiple servers in the cluster to explain the architecture.
- Control Node. Similar to Hadoop’s NameNode/Job Tracker, PolyBase will have one Control Node. The Control Node is a SQL Server instance that you configure that runs the PolyBase Engine Service. Think of the Control Node as the point of contact for the client applications across the cluster. Its tasks will include:
- Parsing of the executed T-SQL queries
- Optimizing and building query plans
- Controlling execution of parallel queries
- Returning results to client applications
- Compute Node. Similar to Hadoop’s DataNode/Task Tracker, PolyBase will have one or more Compute Nodes. The Compute Nodes will perform the data movement to bring the data from Hadoop temporarily into SQL Server and shuffle that data as well, depending on what the query does. Because of its function, it will run the PolyBase Data Movement Service. If the query requires parallel execution, the Compute Nodes will share the load of the parallel query execution as dictated and coordinated by the Control Node.
Note that you can deploy PolyBase in a single-server architecture where the Control Node also functions as the Compute Node. This series of tips will start with a single-server deployment and will work towards building a multi-server cluster for scalability. And because it will require massive compute and storage resources, only one SQL Server instance per machine can run PolyBase. You might be tempted to run multiple instances of SQL Server on your test environment – make the default instance a Control Node and the other named instances as Compute Nodes. This won’t work. You have been warned.
Installing PolyBase
Since PolyBase is now part of SQL Server, we can use the SQL Server 2016 installation media to do the installation. And because it was designed to interact with Hadoop, we will need to install the Oracle Java SE Runtime Environment (JRE) 7.51 (x64) or higher prior to running the SQL Server 2016 installation media.

If you don’t have the JRE installed, the installation will fail.

You can download the JRE from here.
Installing and Configuring the Java Runtime Environment
After downloading the JRE, double-click on the file to install it.


Installation is the easy part. What’s more tricky is the configuration of the environment variables. After the JRE installation, verify the installation path. We will need this information to configure the environment variables.
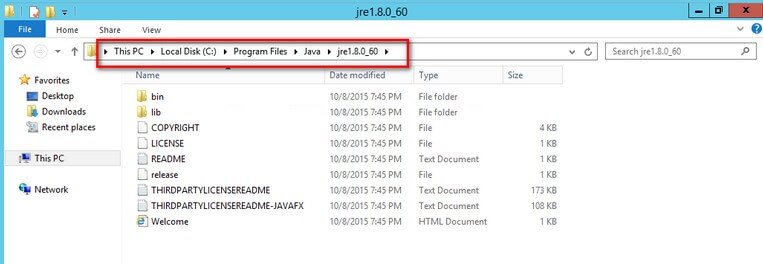
In my environment, the installation path is on C:\Program Files\Java\jre1.8.0_60
Next, we need to create an environment variable named JAVA_HOME that points to the installation path. You can do this by opening up the Computer Properties dialog box and selecting Advanced system settings. In the System Properties dialog box, in the Advanced tab, click the Environment Variables button. This will bring up the Environment Variables dialog box. Click the New button under the System variables section.

In the New System Variable dialog box, type JAVA_HOME in the Variable name:text box and the JRE installation path in the Variable value:text box
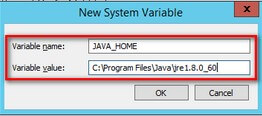
Click OK three times – once to exit the New System Variable dialog box, once to exit the Environment Variables dialog box and last to exit the System Properties dialog box
When completed, we need to test Java and the JAVA_HOME environment variable. Open the command prompt and type the following command to go to the JAVA_HOME installation path:
C:\>cd %JAVA_HOME%

C:\>java -version


When you get to the Server Configuration dialog box, you will notice the two services I’ve mentioned above – the PolyBase Engine Service and the PolyBase Data Movement Service. Note that a Control Node also acts as a Compute Node regardless of whether you have a single-server deployment or a multi-server cluster. Make sure that you provide the appropriate service accounts for these two services.

Once the installation of PolyBase is done, we can go ahead and configure it for interaction with a Hadoop cluster, Azure Blob Storage or even YARN (also known as MapReduce v2).
In the next tip in this series, we will configure PolyBase to connect to a Cloudera Hadoop cluster, an Azure HDInsight cluster and an Azure Blob Storage account.
Next Steps
- Download SQL Server 2016 Community Technology Preview to test out PolyBase.
- Review some of the Big Data tips to get familiarized with how Hadoop works so we can properly integrate it with PolyBase

Edwin M. Sarmiento is the Managing Director of 15C, a consulting and training company that specializes on designing, implementing and supporting SQL Server infrastructures. He is a Microsoft SQL Server MVP and Microsoft Certified Master from Ottawa, Canada specializing in high availability, disaster recovery and system infrastructures running on the Microsoft server technology stack ranging from Active Directory to SharePoint and anything in between. He is very passionate about technology but has interests in music, professional and organizational development, and leadership and management matters when not working with databases. Edwin lives up to his primary mission statement: “To help people and organizations grow and develop their full potential.”
- MSSQLTips Awards: Champion Award (100+ tips) – 2017 | Author of the Year Contender – 2020, 2017