By: Siddharth Mehta
Overview
In the last chapter, the Data Mining structure wizard created different database objects like a new cube, a new dimension, a new DSV and a new data mining structure along with the model. In this chapter we will understand how the new data mining model can be used for analysis using the Data Mining relationship between facts and dimensions.
Explanation
Open the Adventure Works_DM cube created by the wizard in the last chapter.
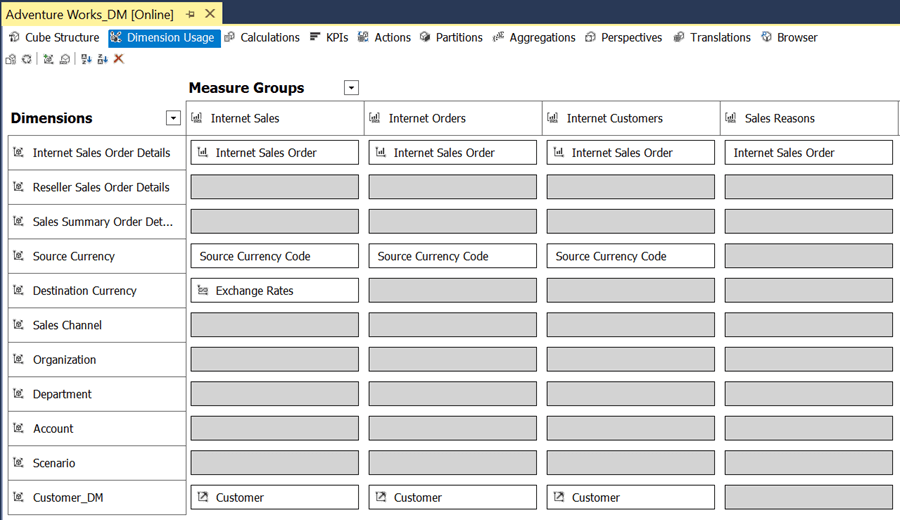
1) Once you open this cube in SSDT, it should look as shown below. If you carefully observe you will be able to make out that the Customer_DM dimension is related to the corresponding fact tables using the Data Mining relationship.
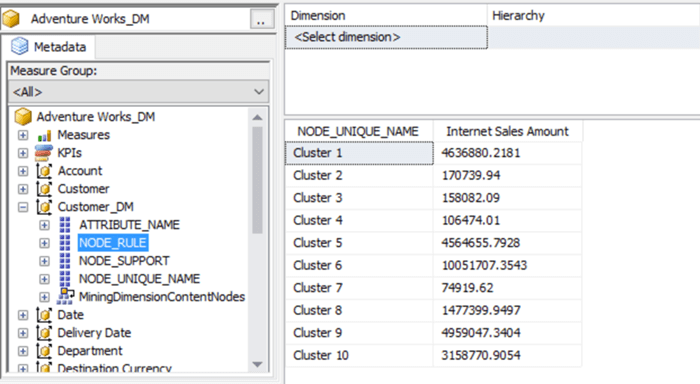
2) Now let's explore the results of this relationship in SSMS. Open SSMS and browse the cube. Select the NODE_UNIQUE_NAME attribute from Customer_DM dimension and Internet Sales Amount fact, as shown below. This shows the predicted value of Internet Sales Amount for each cluster.
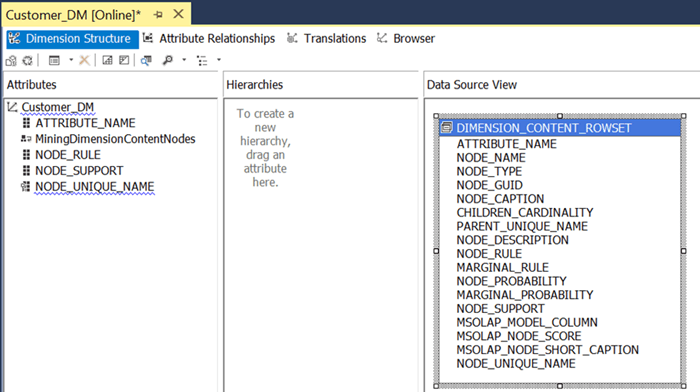
3) In case you are wondering where these attributes came from in the Customer_DM dimension, you can explore this dimension in SSDT and it should look as shown below. You can add more fields from the DSV to have relevant fields of interest available for exploring.
In this way you can explore a cube created using an OLAP source, having a dimension as well as a cube that are optimized for data mining relationships.
Additional Information
- Add more attributes in the Customer_DM dimension from DSV, process and deploy, and explore in SSMS.
