By: Siddharth Mehta
Overview
In this last lesson of this tutorial, we have reached a phase where we are ready to analyze a sample dataset with R. For visual analytics in SQL Server, developers have been primarily used Excel / SSRS / Power BI / PowerPivot / Power View or similar tools to source data from tables / views and create visualizations. Sometimes data analysts / data scientists in particular need statistical visualizations for deeper data analysis. Also, for large datasets it might not always be possible to read the entire dataset from external tools for various reasons.
R provides many external libraries for graphical analysis, as well as it contains built-in functions to generate graphical plots for quick data analysis which can come handy while developing / exploring data science algorithms. In this lesson we would look at one of the ways to analyze data in a graphical manner using R to understand data distribution and outlier analysis.
Generating a graphics device in R
R typically creates images using an R device for graphical output. You can capture the output of this device and store the image in a varbinary data type for rendering in application, or you can save the images to any of the support file formats (.JPG, .PDF, etc.).
R contains a set of functions like JPEG, BMP, PNG and TIFF to create an R graphics device that can collect the output of plotting functions in R and save the output to a file. You can read more about these here. We will be using these shortly in an example to understand it in more detail.
Generating graphs / plots in R
For the purpose of discussion, we will be using the AdventureWorks DW sample database available from Microsoft. This database is a data warehouse that contains dimensions and fact tables. One table of interest is the FactResellerSales table that contains approximately more than 60k records. Let’s say we intend to analyze transactions where the product had to be sold at loss. We can find this with a simple T-SQL query as well, but our intention is to find transactions which are far away from other values in the group. In this case, there may be many products which were sold at a loss compared to all other transactions. So let’s start with the analysis of this dataset.
In order to analyze loss, we need to know basically two parameters – production cost and sales amount. The data in question is transactional in nature. Most of the developers have worked with a transactional database, so the nature of this data is relatable. There can be products which may have been sold many times at the same price in a year. So we need to find each transaction for a product with a unique production cost, sales amount and financial year. You can use the below query and the result set will reduce to 5347 rows from 60k rows.
select distinct F.ProductKey, F.TotalProductCost, F.ExtendedAmount, F.OrderQuantity, F.SalesAmount, Year(F.OrderDate) as OrderYear, P.EnglishProductName, C.EnglishProductCategoryName, S.EnglishProductSubcategoryName from FactResellerSales F join DimProduct P on F.ProductKey = P.ProductKey join DimProductSubcategory S on S.ProductSubcategoryKey = P.ProductSubcategoryKey join DimProductCategory C on C.ProductCategoryKey = S.ProductCategoryKey Order by F.ProductKey, Year(F.OrderDate)
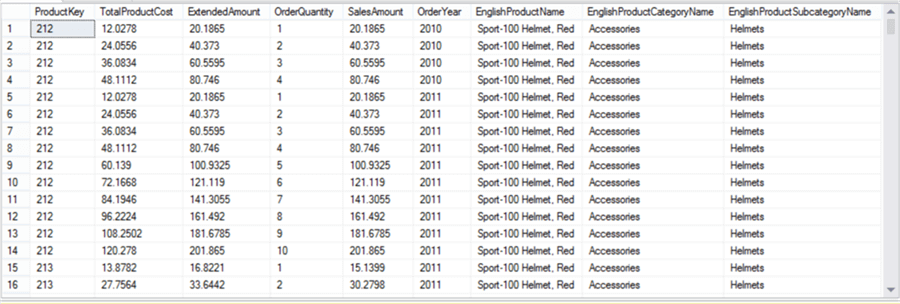
We have included qualitative attributes of the product like Product Category and Product Subcategory by joining relevant tables. We would need to use this dataset multiple times, so it is advisable to create a view using the above query. We have created a view named MyRTestData using the above definition.
Now it’s time to create our first plot. Execute the below code.
EXECUTE sp_execute_external_script @language = N'R', @script = N'
jpeg(filename="C:\\temp\\plots\\Scatterplot1.jpeg", width = 1080, height = 1080, units = "px", pointsize = 15, quality = 100,);
plot(InputDataSet$ExtendedAmount, InputDataSet$TotalProductCost, col=InputDataSet$EnglishProductCategoryName, main="Scatterplot colored by Category", xlab="Sales Amount ", ylab="Total Product Cost", pch=19, )
legend("topright", legend=c("Accessories", "Bikes", "Components", "Clothing"), col = c(1:4), lty="solid")
dev.off();
',
@input_data_1 = N'Select * from MyRTestData'
Here we are creating a graphics device using the jpeg function in the R script. We are specifying the dimensions of the output file as well as the file path in the function. Using the plot function we are creating a scatterplot graph where we are plotting ExtendedAmount on the x-axis, TotalProductCost on the y-axis and coloring the data points by Product Category. Finally we are using the legend function to show legends on the graph. Once the output of the graph is generated we are closing the graphics device which saves the output to a file. The output of the graph should look as shown below.
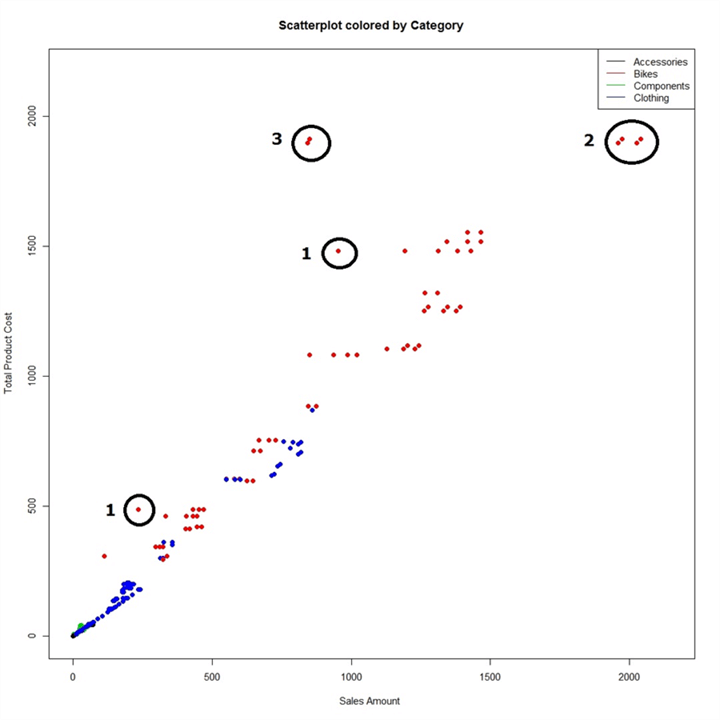
If you study the graph above, you will find that there many products are neck-to-neck on production cost vs sales amount. There are some products whose production cost is higher than sales amount which is undesirable from a business perspective. Some of these points are marked in black circles with a number 1 besides them. But they are still not that far away from the group. If you study the points in circles marked with a 2, these points have the highest manufacturing cost and sales amount. But the points in circles marked 3 have almost the same production cost, but the sales amount is almost half. So, this is the first point of investigation for outlier analysis with this graph we made quickly.
We saw that the dataset we used contained more than 5k points and the above graph does not seem to have that many points. The reason for this is that many products may have the exact same production cost and sales amount, in that case a group of data points overlays each other looking like a single point. The points in circle 3 seem like 2 data points, and the red color signifies their category is Bikes. So now let’s get rid of other categories of data and look at the Bikes data and color them by subcategory to know the subcategory of these Bikes that are selling at a loss.
EXECUTE sp_execute_external_script @language = N'R', @script = N'
jpeg(filename="C:\\temp\\plots\\Scatterplot2.jpeg", width = 1080, height = 1080, units = "px", pointsize = 15, quality = 100,);
plot(InputDataSet$ExtendedAmount, InputDataSet$TotalProductCost, col=InputDataSet$EnglishProductSubcategoryName, main="Scatterplot colored by SubCategory", xlab="Sales Amount ", ylab="Total Product Cost", pch=19, )
legend("topright", legend=c("Mountain Bikes", "Road Bikes", "Touring Bikes"), col = c(1:3), lty="solid")
dev.off();
',
@input_data_1 = N'Select * from MyRTestData where EnglishProductCategoryName = ''Bikes'''
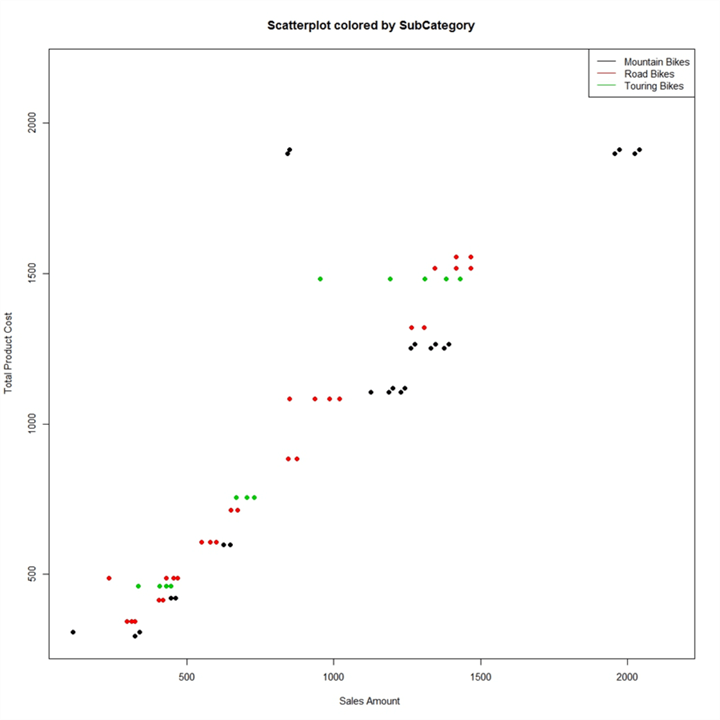
The above code results in the above graph in the form of a jpeg file. From this graph the blue color of the points in question shows that these points are in the Mountain Bikes subcategory. These points have a production cost of more than 1500 / close to 2000, and a sales amount of less than 1000. So, let’s add this filter to our dataset in the input query, and create a dotplot to see the actual values of these two points visible on the above graph.
Execute the below query to create the graph.
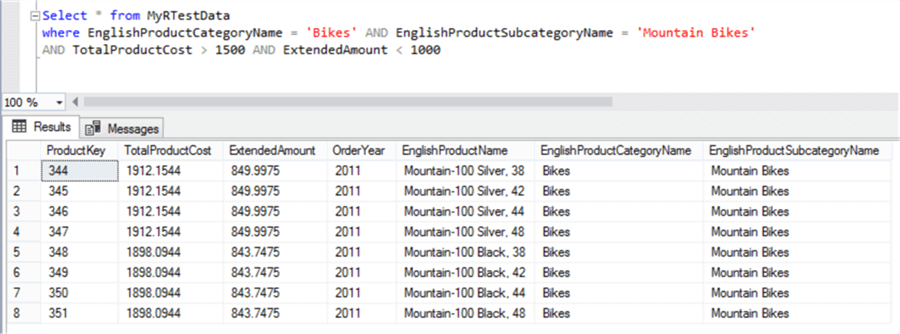
EXECUTE sp_execute_external_script @language = N'R', @script = N' jpeg(filename="C:\\temp\\plots\\Dotplot1.jpeg", width = 1080, height = 1080, units = "px", pointsize = 10, quality = 100,); dotchart(InputDataSet$ExtendedAmount,labels=InputDataSet$EnglishProductName,cex=2,main="Product Sales Amount", xlab="Sales Amount") dev.off(); ', @input_data_1 = N' Select * from MyRTestData where EnglishProductCategoryName = ''Bikes'' AND EnglishProductSubcategoryName = ''Mountain Bikes'' AND TotalProductCost > 1500 AND ExtendedAmount < 1000 '
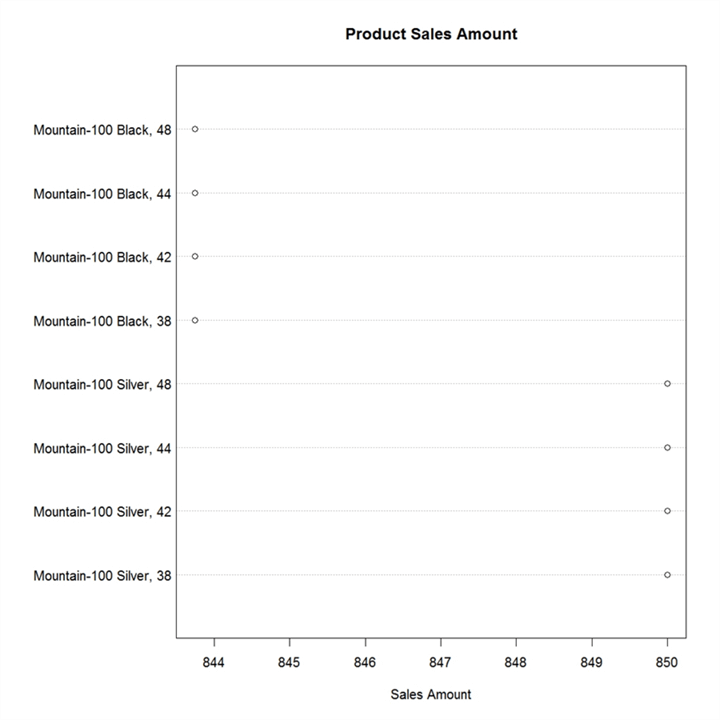
The dotplot chart shows 8 data points instead of 2. As I mentioned earlier, there may be multiple points overlaying each other. That is exactly the case for the two points in question which there are actually 8 points – 4 products with the exact same value and another 4 with the exact same value. If you execute the query on the dataset, you will be able to confirm this as shown below.
So, with the use of R, with just few lines of code we were able to visually compare how production cost is affecting sales cost in a near linear fashion. We were able to proportionally compare all the products production cost versus sales amount performance, and find the high potential outliers almost instantly and visually. And finally, we zeroed down on the exact outlier products which had poor performance.
This example has been kept as simple as possible and actual real-life applications are immensely more complex, computation intensive and voluminous, but you can see how quickly we were able to find the issues visually.
R Scripts as Stored Procedure
R Scripts will probably involve complex calculations developed by data analysts / data scientists / database developers after deep analysis. So, after the exploration / analysis phase is over as we did above, it is advisable to wrap R scripts inside a stored procedure for centralizing logic and easy administration for future use.
Useful Resources
Below are some useful links to R resources:
Summary
We started this tutorial assuming you were totally new to R. Architecturally and conceptually anyone new to R would have questions on what is R, why to use it and how will it make a difference in day-to-day jobs for professionals working with SQL Server.
We covered the answers to all these questions, analyzed R integration architecture with SQL Server 2017 in the first lesson followed by details installation, configuration and basic acceptance testing of R using tools like Visual Studio 2017 and SSMS. In the third lesson, we learned the basic programming constructs of R like variables, operators, and loops and understood how to execute basic R scripts with T-SQL.
After learning the basics, we saw an interesting use-case of R where we used R to calculate a bunch of statistics for a number of fields with a single line of code. In this last lesson, we learned to create graphical visualizations with R from T-SQL and data stored in SQL Server to complete the analytics cycle.
I hope this tutorial provides a launch-pad for enthusiasts who are keen to apply the power of R to SQL Server datasets.
