Overview
SQL Server 2016 introduced support for executing R scripts inside the boundaries of T-SQL script execution inside the database engine. With the advent of SQL Server 2017, this support has been enhanced by including support for Python and baked into SQL Server in the form of a Machine Learning Server and Machine Learning Services (in-database). Machine Learning Server for Windows provides parallelized big data analysis, transformation, modeling and operationalization capabilities. In-database Machine Learning Services includes extensions that enable integration with Python using standard T-SQL statements.
Explanation
In order to understand the influence of Python on professionals in terms of SQL Server related roles and responsibilities, first we need to understand how Python is integrated into SQL Server, its application and capabilities, and whether it’s replacing T-SQL tasks or it is going to complement T-SQL capabilities. Having understood all this, it would be easier to assess the influence of Python on our day to day activities. So let’s try to understand how Python works with SQL Server 2017.
Python and SQL Server Database Engine Integration Architecture
Before we delve into the integration architecture, let’s conceive a tangible perception of Python for the purpose of discussion. Consider Python as an open-source general-purpose programming language that has all the programming constructs like variables, loops, operators, etc. like any other programming language. Python is an interpreted, interactive, object-oriented programming language. It incorporates modules, exceptions, dynamic typing, very high level dynamic data types, and classes. Python has a fundamental emphasis on code readability, which we will understand once we look at programming examples. One key differentiator of Python is that it consists of powerful libraries for statistical computing, visualizations, natural language processing, machine learning, etc. All these libraries are known as packages in the Python world. Some the very famous packages for data science are Numpy, Matplotlib, Skikit-learn, etc. Python has multiple IDEs like Spyder, IPython, Notebook, Rodeo, Jupyter, etc. We will use Visual Studio as it too has support for developing Python based applications.
Let’s say that we want to compute certain statistics in our regular T-SQL code that requires very complex logic in terms of conceptualization as well as implementation. So we decide to rope in Python for the purpose, as there are some ready-to-use libraries that can compute these values without the need to learn or implement any complex statistical formulas. So here we have a use-case of using Python inside T-SQL code. A stored procedure named sp_execute_external_scripts is the provision inside T-SQL to make a request for executing external scripts.
When you run Python code from T-SQL using Machine Learning Services, all Python scripts are executed outside the SQL Server process, to provide security and greater manageability. SQL Server has introduced new components to enable integration with Python, which are:
- Launchpad – The SQL Server Trusted Launchpad is a service provided by SQL Server 2017 for supporting execution of external scripts, similar to the way that the full-text indexing and query service launches a separate host for processing full-text queries.
- Binary Exchange Language (Bxl) Server – BxlServer is an executable provided by Microsoft that manages communication between SQL Server and the Python runtime.
- SQL Satellite – The SQL Satellite is a new extensibility API in SQL Server that is provided by the database engine to support external code. BxlServer uses SQL Satellite for communicating with SQL Server.
The architecture diagram below from MSDN shows how these components work together to enable seamless integration of Python with the SQL Server Database Engine.
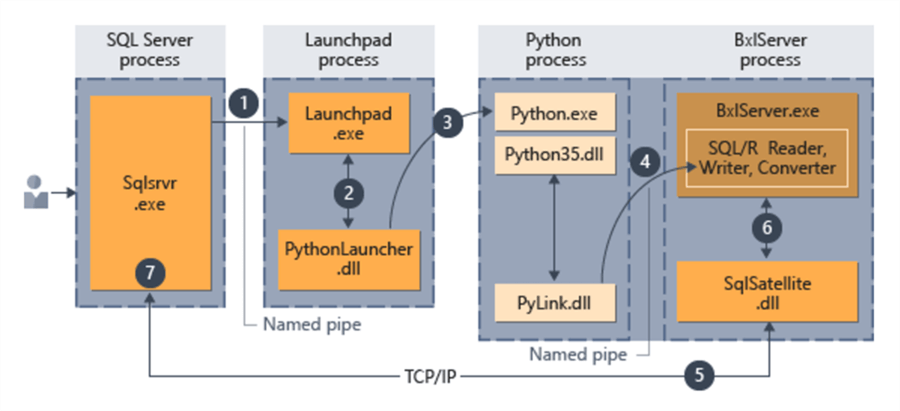
- A request for the Python runtime is indicated by the parameter @language=’Python’ passed to the stored procedure. SQL Server sends this request to the Launchpad service.
- The Launchpad service starts the appropriate launcher; in this case, PythonLauncher.
- PythonLauncher starts the external Python35 process.
- BxlServer coordinates with the Python runtime to manage exchanges of data, and storage of working results.
- SQL Satellite manages communications about related tasks and processes with SQL Server.
- BxlServer uses SQL Satellite to communicate status and results to SQL Server.
- SQL Server gets results and closes related tasks and processes.
Applications of Python in SQL Server
Python in SQL Server is very new and yet to witness a large scale community adoption. Considering the existing unique and differentiating applications of Python in the industry, the following applications of Python (in no particular order) in SQL Server seems probable.
- Machine Learning
- Financial Data Modeling
- Bio-informatics data analysis
- Spatial and geo-statistical modeling
- Web Scraping and data ingestion
Python with T-SQL compared to Python versus T-SQL
Python as well as T-SQL both are programming languages that can work with data. Both contains some common as well as unique programming constructs and capabilities. So the natural question that comes to mind is whether Python can be used to replace some of the T-SQL data manipulation tasks? Will Python replace some of the T-SQL features or Python will be complementing T-SQL to extend its capabilities beyond data manipulation like machine learning, statistical modeling, etc.
Python has libraries to deal with data in the way T-SQL manipulates data. The Python architecture was not natively built for multi-threaded, multi-processor or parallel processing. There are several parallel processing libraries for Python available that allow you to explicitly run calculations in Python simultaneously. Microsoft SQL Server includes Anaconda distribution of the Python libraries, which are optimized for processing larger volumes of data for statistical and data science purposes.
Among the most important additions are the RevoScalePy libraries. These are Python packages that have been written largely in C or C++ for better performance. RevoScalePy includes a variety of APIs for data manipulation and analysis. The APIs have been optimized to analyze data sets that are too big to fit in memory and to perform computations distributed over several cores or processors. Python solutions based on the RevoScalePy functions can work with very large data sets and are not bound by local memory.
So architecturally speaking it makes sense to use T-SQL for dealing with large volumes of data calculations, and use Python in the area of its strength i.e. statistical modeling, machine learning, predictive analytics, etc.
What Python in SQL Server means for Database developers, DBAs, Data analysts and Data scientists?
- Database developers should learn Python, so that they can extend their competency beyond basic tabular data manipulation as business requirements of predictive analytics would mandate the use of Python in T-SQL. Python is also supported on Azure Machine Learning. Considering the penetration of analytics and the cloud in the industry, it becomes very important for database developers to have the knowledge of data science languages that runs the analytics show in the cloud.
- DBAs do not need to learn Python in particular, but would need to learn how to monitor and govern Python resource usage. Database administrators can control who has the ability to run Python jobs, and who has the ability to install or share R packages. The administrator can also monitor the use of Python scripts by either remote or local users, and monitor and manage the resources consumed.
- Data analysts should inevitably learn Python as it has all the means to bring predictive analytics, machine learning, and related analytics on raw data. Without these capabilities, the capabilities of T-SQL would be limited to data profiling and exploration from an analytics perspective.
- Data scientists of major successful and large-scale organizations generally use R and/or Python as the primary data science language. So if you are an aspiring data scientist, there is no option but to learn R / Python and apply it for different data science algorithms and techniques.
Python Tools in SQL Server Ecosystem
Installing Machine learning services installs the Anaconda distribution of Python, with its set of command line tools. Microsoft Visual Studio 2017 also contains a set of tools to create a Python solution with almost the same native Python environment integrated into the Visual Studio IDE.
Installing In-Database Machine Learning Services installs extensions which enables executing Python scripts from T-SQL. Usually SQL Server Management Studio (SSMS) is used to develop and execute T-SQL scripts, so that it can be used to execute Python scripts from T-SQL.
Now that we understand how Python fits in the SQL Server Ecosystem, let’s understand how to install and configure Machine Learning Server and Services with Python in the next lesson.
Additional Information
- In case if you are interested in exploring Python independently before starting to use if from SQL Server, you can download Python from here.

Siddharth has more than 14 years of experience in the IT Industry, with more than a decade of experience in Business Intelligence and Analytics, for clients banking, logistics, government, Media Entertainment, products, life sciences and other domains. He has been a lead architect for a portfolio of 40+ apps, containing apps in web, mobile, BI, Analytics, data warehousing, reporting, collaboration, CMS, NoSQL and other technologies. He has several certifications and is a published author for online and print-media publications, as well as the MSDN Library.
In his present role, he remains responsible for architecture design, technology stack selection, infrastructure design, 3rd party products evaluation and procurement, and performance engineering. These applications use technologies like Elasticsearch / Lucene, MongoDB, SharePoint 2013 and 2010, jQuery-based framework like Highcharts and GoJS, SQL Server and the Microsoft Business Intelligence stack (SSIS, SSAS, SSRS, MDX, PowerPivot, PowerView), jQueryMobile, Bootstrap, iOS xCode framework, and many others.
- MSSQLTips Awards: Champion (100+ tips) – 2018 | Author of the Year – 2017 | Author Contender – 2016, 2018-2019


