Overview
Up to this point, all of our regular expressions in our query have used capital letters, and this hasn’t impacted the results. The reason the results were not impacted is because our database is not set to be case sensitive, so we’ll be changing our query settings in this section to test case sensitivity. As we’ll see, querying will be similar, and the case will matter in our ranges or specifications of alphabetic characters.
Explanation
Regex Case Sensitivity
If we wanted to look for all the results in our table that only had one alphabetic character of any range (A through Z) and we wanted this to only be a lower-case character, if we run both queries in our first set, notice how our result does not differ. This means that even if we only want to return letters with capitals, we’ll also see lower-case letters, too, and vice versa. This is because the database I set up is not case sensitive.
SELECT *
FROM alphareg
WHERE Alphabetic LIKE '[A-Z]'
SELECT *
FROM alphareg
WHERE Alphabetic LIKE '[a-z]' 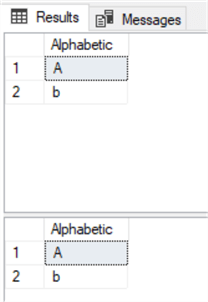
Two results from each query.
Database Collation Setting for Case Sensitivity
One option is that we could create another database with this collation specified, though we may not want this if it affects all values in our database.
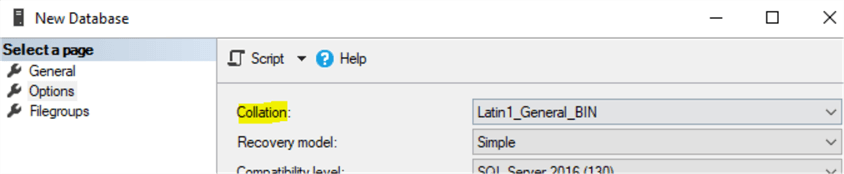
Depending on our need, we may be able to specify the collation at the database level – if this is required for all columns, but be careful, as we may only need specific collation for a few queries. In the image below, we see the collation option for creating a new database.
Using Regex and Column Collation to Test Case Sensitivity
Our query does not specify any case sensitivity, so we’ll use both of the same queries and specify the column collation to be Latin1_General_BIN, which will return results based on case sensitivity.
SELECT *
FROM alphareg
WHERE Alphabetic COLLATE Latin1_General_BIN LIKE '[A-Z]'
SELECT *
FROM alphareg
WHERE Alphabetic COLLATE Latin1_General_BIN LIKE '[a-z]' 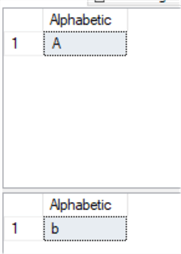
One result from each query.
Now, our results return on the basis of our case sensitivity.
Regex to Find Upper Case or Lower Case Characters
Finally, let’s query our data rows and see if we have any alphabetic characters that are capitalized within the sentence, but start with a lower-case character. In this case, we’ll allow any range of starting characters, as long as they’re lower-case, and search for any combination of upper-case characters.
SELECT *
FROM alphareg
WHERE Alphabetic COLLATE Latin1_General_BIN LIKE '[a-z]%[A-Z]%' 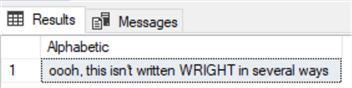
One result from this query.
Regex to Find Upper Case or Lower Case Characters
What about any case for the first character being of a range A through Z with an upper-case somewhere in the sentence or column? We can use case combinations for this [A-Za-z] which means the first character can be any alphabetic character upper or lower case.
SELECT *
FROM alphareg
WHERE Alphabetic COLLATE Latin1_General_BIN LIKE '[A-Za-z]%[A-Z]%' 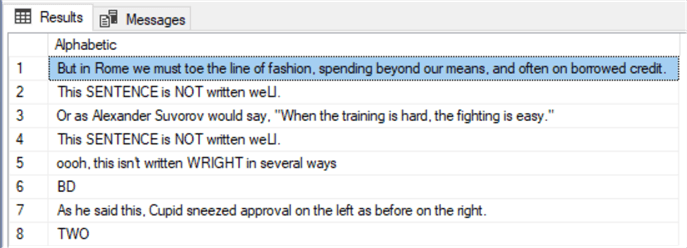
Eight results from this query.
Summary
Up to this point, we’ve covered alphabetic regular expressions by showing:
- How to limit character length
- How to allow a range or specific set of characters
- How to allow for any preceding or following character
- How to handle case sensitivity by either restricting it to a case or allowing both types of case sensitivity in some situations.
Since we often use regular expressions with numbers and alphabetic characters, we’ll look at how to filter on numbers along with how to extract numeric characters with decimals or specify decimal precision with regular expressions.
Additional Information
- Case sensitivity can also impact performance with queries, so when setting up a database where regular expressions might be run against character-based data, such as char, varchar, nvarchar, consider if the case of the expression will matter with queries. If in doubt, it can always be specified at the query level, like we did in this section.

Tim consults for FinTek Development and teaches the course Automating ETL on Udemy. He’s worked with technology since high school, helping his school win its first TCEA award and continues to work in automation, data architecture, back-end development, and smart contract architecture. Tim enjoys testing new technologies early in the diffusion of innovation curve and was an early adopter of NoSQL and smart contract development. He has a blog at http://www.fintekdev.com/ and helps contribute to local technical and financial events in Texas.


