Overview
In this section, we will cover things you need to know about non-clustered indexes.
Explanation
What is a non-clustered index
A non-clustered index (or regular b-tree index) is an index where the order of the rows does not match the physical order of the actual data. It is instead ordered by the columns that make up the index. In a non-clustered index, the leaf pages of the index do not contain any actual data, but instead contain pointers to the actual data. These pointers would point to the clustered index data page where the actual data exists (or the heap page if no clustered index exists on the table).
Why create non-clustered indexes
The main benefit of having a non-clustered index on a table is that it provides fast access to data. The index allows the database engine to locate data quickly without having to scan through the entire table. As a table gets larger, it is very important that the correct indexes are added to the table, as without any indexes, query performance will drop off dramatically.
When should non-clustered indexes be created
There are two cases where having a non-clustered index on a table is beneficial. First, when there is more than one set of columns that are used in the WHERE clause of queries that access the table. A second index (assuming there is already a clustered index on the primary key column) will speed up execution times and reduce IO for the other queries. Second, if your queries frequently require data to be returned in a certain order, having an index on these columns can reduce the amount of CPU and memory required, as additional sorting will not need to be done since the data in the index is already ordered.
The following example shows how no table scan is required to fetch the data, just an index seek of the non-clustered index and a lookup of the clustered index to get the data. Also, note that no sort is required as the data is already in the correct order.
SELECT * FROM Sales.SalesOrderDetail
WHERE ProductID = 750
ORDER BY ProductID;
How to create a non-clustered index
Creating a non-clustered index is basically the same as creating a clustered index, but instead of specifying the CLUSTERED clause, we specify NONCLUSTERED. We can also omit this clause altogether, as a non-clustered index is the default when creating an index.
The TSQL below shows an example of each statement.
-- Adding non-clustered index
CREATE NONCLUSTERED INDEX IX_Person_LastNameFirstName ON Person.Person(LastName ASC,FirstName ASC);
CREATE INDEX IX_Person_FirstName ON Person.Person (FirstName ASC);What is a covering index
A covering index is an index that is made up of all (or more) of the columns required to satisfy a query as key columns of the index. When a covering index can be used to execute a query, fewer IO operations are required since the optimizer no longer has to perform extra lookups to retrieve the actual table data.
Below is an example of the TSQL you can use to create a covering index on the Product table.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name
ON Production.Product (Name ASC,ProductNumber ASC);The following TSQL query can now be executed by only accessing the new index we just created since all columns in the query are part of the index.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';The following EXPLAIN plan confirms there is no extra lookup required for this query.

What is an index with included columns
An index created with included columns is a non-clustered index that also includes non-key columns in the leaf nodes of the index, similar to a clustered index. There are a couple of benefits to using included columns. First, it gives you the ability to include column types that are not allowed as index keys in your index. Also, when all the columns in your query are either an index key or included column, the query no longer has to do an extra lookup in order to get all the data needed to satisfy the query, which results in fewer disk operations. This is similar to the covering index mentioned earlier.
Using the same example from above the following TSQL will create the same index except with the ProductNumber column referenced as an included column and not an index key column.
CREATE NONCLUSTERED INDEX IX_Production_ProductNumber_Name
ON Production.Product (Name ASC) INCLUDE (ProductNumber);Using the same query as above this should also be able to execute without requiring any extra lookups.
SELECT ProductNumber, Name FROM Production.Product WHERE Name = 'Cable Lock';The following EXPLAIN plan confirms that no extra lookup is required for this query as well.

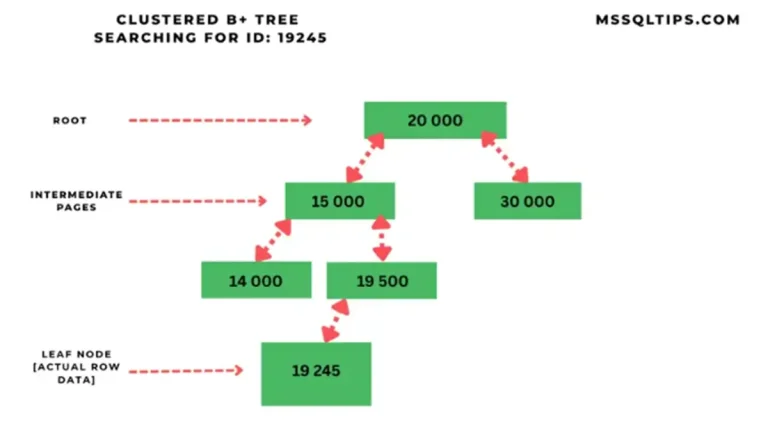
Non-clustered indexes relation to clustered index
As described above, the clustered index stores the actual data of the non-key columns in the leaf nodes of the index. The leaf nodes of each non-clustered index do not contain any data and instead have pointers to the actual data page (or leaf node) of the clustered index. The diagram below illustrates this point.

Filtered Indexes
What is it?
A filtered index is a special index type where only a certain portion of the rows of the table are indexed. Based on the filter criteria that is applied when the index is created, only the remaining rows are indexed, which can save on space, improve query performance, and reduce maintenance overhead as the index is much smaller.
Why use it?
Filtered indexes are useful when you are creating indexes on tables where there are a lot of NULL values in certain columns or certain columns have a very low cardinality, and you are frequently querying a low frequency value.
How to create it?
A filtered index is created simply by adding a WHERE clause to any non-clustered index creation statement. The following TSQL is an example of the syntax to create a filtered index.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_INC_ShipDate ON Sales.SalesOrderHeader
(OrderDate ASC) WHERE ShipDate IS NULL;Confirm Index Usage
The following query should use our newly created index as there are very few records in the table with ShipDate NULL. Here is the TSQL.
SELECT OrderDate FROM Sales.SalesOrderHeader
WHERE ShipDate IS NULL
ORDER BY OrderDate ASC;Looking at the EXPLAIN plan for this query, we can see that we first access our new index before performing a lookup on the clustered index. Something to note below is that the Key Lookup takes 97% of resources for this query. This is why using a non-clustered index with included columns or a covering index could have a big impact on performance.


Ben Snaidero has been a Database Administrator for just over 10 years. Starting out working mainly with Oracle he got into SQL Server in 2005 and has worked primarily with SQL Server for the last 3 years. His main focus with both Oracle and SQL Server is in the area of performance tuning.
- MSSQLTips Awards: Achiever (75+ tips) – 2018 | Author of the Year Contender – 2016-2017


Hello Phillip,
my understanding of the execution plan using index scan is because it has to look at all values with null and that would include many columns with null, null is non unique. i could be wrong here.
Over all this is such a great explanation of indexes , how to use them and why use them.
Thank you