By: Tibor Nagy
Overview
In this example we will execute a more complex query.
Explanation
We will try to query some data about the products and the product categories. We can use the ProductKey and ProductSubcategoryKey to join the data from different tables.
So our query looks like this:
SELECT DP.ProductKey,
DP.EnglishProductName,
DPC.ProductCategoryKey,
DPC.EnglishProductCategoryName,
DPSC.ProductSubcategoryKey,
DPSC.EnglishProductSubcategoryName
FROM AdventureWorksDW..DimProduct DP
INNER JOIN AdventureWorksDW..DimProductSubcategory DPSC
ON DP.ProductSubcategoryKey=DPSC.ProductSubcategoryKey
INNER JOIN AdventureWorksDW..DimProductCategory DPC
ON DPSC.ProductCategoryKey=DPC.ProductCategoryKey
Open a new query window and press CTRL+M to include the Actual Execution Plan and then execute the above query.
The Actual Query Plan for this query is shown below. Please note the junctions in the execution tree.
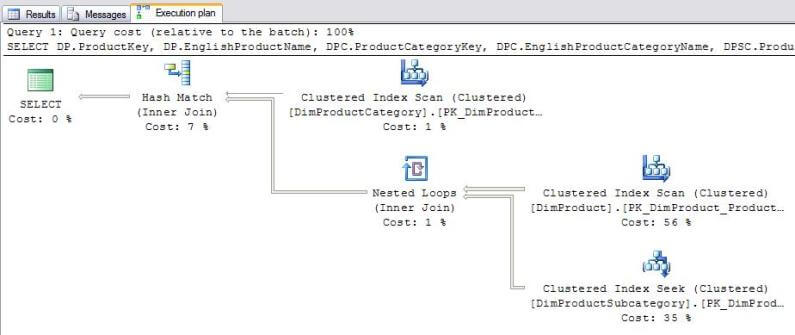
You can see in the picture two Clustered Index Scans, a Clustered Index Seek, a Nested Loops, a Hash Match and a Result operator.
SQL Server processed the query this way:
- Clustered Index Scan on the DimProduct table (cost 56%)
- Clustered Index Seek on the DimProductSubcategory table (cost 35%)
- Nested Loops to join the above inputs (cost 1%)
- Clustered Index Scan on the DimProductCategory table (cost 1%)
- Hash Match to join the above inputs (cost 7%)
- Select to return the result set (cost 0%)
Looking at the cost of the operators you will notice that the Clustered Index Scan on the DimProduct table is very expensive, it uses 56% of all the resources. If you remember, a similar operation was also performed in our previous example. We also have a Clustered Index Seek on the DimProductsSubcategory table which also has a high cost (35%) the ToolTip for this is shown below.
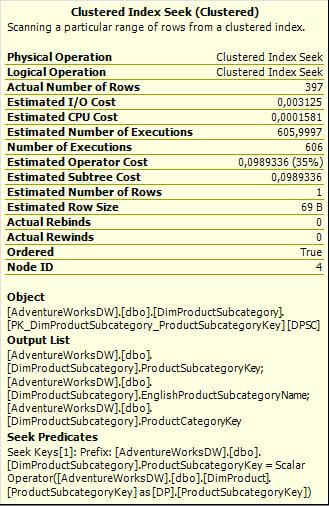
A closer look at the Clustered Index Seek operation reveals that it returned 397 rows and it executed 606 times! This is why this operation consumes such a high percentage of the resources. This can also be noted by the Nested Loops Join; the query first got data from the DimProduct table and then it had to fetch a corresponding row from the DimProductSubcategory one at a time, this is why it was executed 606 times. You are probably wondering why only 397 rows were returned if it executed 606 times. The reason for this is that 606 rows were returned from the DimProduct table in the Clustered Index Scan operation, but only 397 of these rows had a ProductSubcategoryKey which was used in the INNER JOIN on the DimProductSubcategory table.
So how can we improve the performance?
The way the query is written right now there is not much that can be done because all data from the DimProduct table is being returned, but one thing we could do is to filter out the NULL SubcategoryKey records as follows:
SELECT DP.ProductKey, DP.EnglishProductName, DPC.ProductCategoryKey, DPC.EnglishProductCategoryName, DPSC.ProductSubcategoryKey, DPSC.EnglishProductSubcategoryName FROM AdventureWorksDW..DimProduct DP INNER JOIN AdventureWorksDW..DimProductSubcategory DPSC ON DP.ProductSubcategoryKey=DPSC.ProductSubcategoryKey INNER JOIN AdventureWorksDW..DimProductCategory DPC ON DPSC.ProductCategoryKey=DPC.ProductCategoryKey WHERE DP.ProductSubcategoryKey IS NOT NULL
If we execute this and look at the query plan we have a different plan now. You will also note that we have a missing index hint as well.
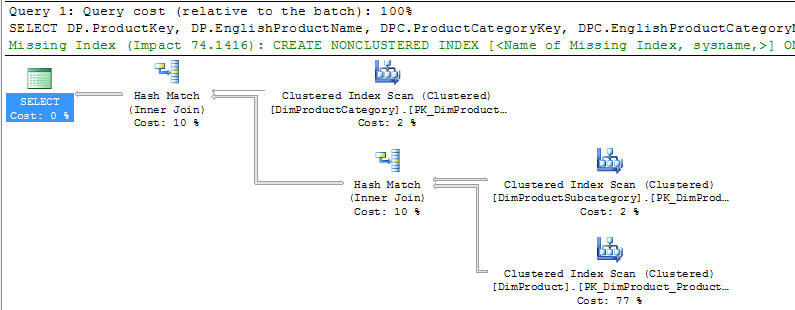
The missing index hint is as follows which I created.
CREATE NONCLUSTERED INDEX [IX_DimProduct_ProductSubcategoryKey] ON [dbo].[DimProduct] ([ProductSubcategoryKey]) INCLUDE ([ProductKey],[EnglishProductName])
Then if I execute the query and again and look at the query plan I can see that this has changed again.
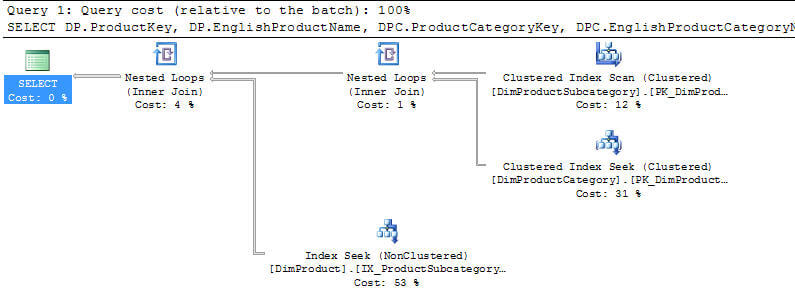
So is this getting better or not?
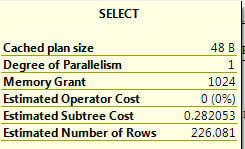
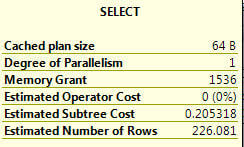
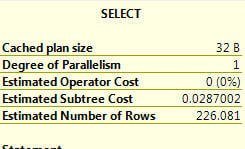
One way to check this out is to look at the overall cost of each query run. If we get the ToolTip for the left most operation (in this case the SELECT) for each query run we can get the overall cost of the query.
Below are the three query runs (original | using IS NOT NULL | using new index and IS NOT NULL) displayed in the order of the three runs. You can see that the Estimated Subtree Cost went from 0.28 -> 0.20 -> 0.02 as we made improvements to this query. So these changes did improve this query.