By: Armando Prato
Overview
Once the logical design has been determined, you can start to physically design your database where tables and their columns are created. When the task of defining the columns of a table is begun, it very important to choose data types and their sizes wisely.
Explanation
SQL Server data pages hold row data and are roughly capped at 8060 overall bytes (8k) though there is a row overflow mechanism that can kick in. Generally speaking, you should look to keep your data type sizes as compact as possible. It stands to reason that the more compact your rows, the more rows that can fit on a data page resulting in fewer I/Os required (page reads) to get the data required for a query request. In addition, SQL Server's data cache will have more room to store data. I usually take a minimalist approach to data type size definitions and use the smallest data sizes needed to reasonably define a column.
Data types themselves also require careful consideration. Is your application multi-national or is there a chance it may become multi-national? You may be best served by using unicode types (i.e. nvarchar, nchar) vs. the varchar and char types. Unicode types do take twice the data storage (they're double byte) but they allow for storing international characters such as Japanese Kanji. That said, this does negatively impact the 8k size limit.
One item to consider when defining character based columns, I usually avoid using char/nchar unless the size of the data in the column is in a known, fixed size format (such as a U.S. check routing number). The reason is that once a column is defined as char/nchar, the entire column size is allocated and counts against your 8k page size limit. For instance, if you were to define a column called FirstName as char(50), the full 50 characters will be allocated even if a first name that is entered is less than 50 characters. Of course, this becomes wasted space in your data page and causes fewer rows to fit resulting in more I/Os to satisfy queries.
Consider the following example where a table is created with a column defined as char(2000) and seeded with 1000 rows
use tempdb
go
if object_id('SizeTest') is not null
drop table SizeTest
go
create table SizeTest (id int identity primary key clustered, value char(2000) default 'x')
go
insert into SizeTest default values
go 1000
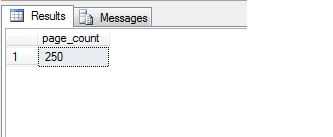
Examining the page count, we see that a total of 250 pages were allocated.
use tempdb
go
select page_count
from sys.dm_db_index_physical_stats(DB_ID('tempdb'),OBJECT_ID('SizeTest'),NULL,NULL,NULL)
go
In contrast, let's rebuild the table and define the value column as varchar(2000)
use tempdb
go
if object_id('SizeTest') is not null
drop table SizeTest
go
create table SizeTest (id int identity primary key clustered, value varchar(2000) default 'x')
go
insert into SizeTest default values
go 1000
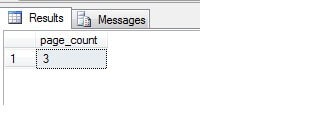
Re-running our query against sys.dm_db_index_physical_stats shows a great reduction in the required row storage
Also look to avoid deprecated data types such as text, ntext, and image as they will eventually become unsupported. Instead, look to convert to and start using varchar(max), nvarchar(max), and varbinary, respectively.
