Overview
You’ve defined a primary key and a clustered index for your table. However, we’re not done yet! We should incorporate integrity constraints!
Explanation
A major design mistake, in my opinion, is to do all data checking within the application and client tiers while ignoring the database and its mechanisms for maintaining data integrity natively. Since constraints are native to the database engine, they are a more efficient option for integrity checking. You should define CHECK, UNIQUE, DEFAULT, Primary Key, and Foreign Key constraints to safeguard data against invalid entries. The byproduct of using constraints is that they also can show up in data modeling tools and, thus, can further document the entities and attributes within your data model.
A story I always use to make my argument for incorporating native constraints revolves around a consulting engagement I was assigned to some years ago. A customer’s application was written in Visual BASIC and all data checking was done within this application code. The database itself was unfortunately defined more or less as a storage container. A data import was required from a 3rd party system and a new importer was written using the VB application as a base (since that’s the only place where all the data rules were located). Sure enough, some rules were missed and the resulting import riddled the database with invalid data.
When leveraging integrity constraints, always name them! If SQL Server is allowed to auto generate a constraint name, it may differ from database to database. If a constraint’s definition has to be adjusted, special logic against system views will have to be written to figure out what auto-generated name was assigned. If your constraints are named up front, special coding can be avoided this plus it gives databases, from installation to installation, an air of consistency.
In this example, we create 2 databases and add the same table to each. We don’t name the UNIQUE and DEFAULT constraints (a personal pet peeve of mine):
create database db1
go
use db1
go
create table t1 (value int not null default 1)
create table t2 (value int not null unique)
go
create database db2
go
use db2
go
create table t2 (value int not null unique)
create table t1 (value int not null default 1)
goLet’s examine the constraints within the system views.
use db1
go
select db_name() as dbname, name from sys.default_constraints
select db_name() as dbname, name from sys.key_constraints
go
use db2
go
select db_name() as dbname, name from sys.default_constraints
select db_name() as dbname, name from sys.key_constraints
go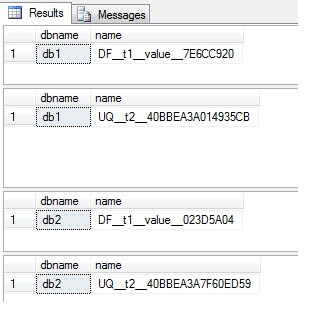
The constraint names differ from database to database which makes any task to re-define them tedious. Name your constraints!
Additional Information
- Working with DEFAULT constraints in SQL Server
- Enforcing business rules using SQL Server CHECK constraints
- The Importance of SQL Server Foreign Keys

For 20+ years, MSSQLTips.com has been delivering comprehensive technical solutions on a daily basis for the Microsoft SQL Server platform. In that time, an innovative team of over 300 authors from around the globe have delivered over 7000 articles and 1000 webcasts ranging from beginner topics to advanced solutions. Our community prides itself on delivering human only generated content.


