By: Armando Prato
Overview
Triggers are a specialized type of stored procedure that can be written to act on a table action such as an INSERT, UPDATE, or DELETE. If overused, they can potentially lead to performance issues such as blocking and, if they're not written correctly, you could be losing data.
Explanation
Triggers are commonly used to perform auditing actions, to maintain table integrity in place of native constraints such as foreign keys and check constraints, and to perform other post DML processing. Triggers operate under the scope of a transaction so if a table were updated, for instance, the update would occur and the trigger would fire. While the trigger is at work, the transaction would not be committed until the trigger completed (or rolled back in the case of failure). If a lot of processing is being done in the trigger, locks will be held until the trigger completes. This is an important point to note: Triggers extend the life of a transaction. Also, due to their stealthiness, they can make troubleshooting data issues difficult and tedious.
The use of triggers to accomplish common integrity checking is probably not a good idea since they do extend transaction life. Moreover, if there is an integrity violation, a ROLLBACK on any modified data will have to occur which can potentially cause a performance bottleneck as the application waits for the rollback to complete. In contrast, native constraints do their checks prior to any modification and, as a result, do not cause a ROLLBACK to occur if a violation occurs.
When triggers fire, there are virtual tables that hold the values of the data before and after the modification. These tables are called inserted and deleted. When accessing these virtual tables within trigger code, you should work on their data as a set. One common mistake I see over and over and over in trigger code: a trigger is written with the assumption it will always work on a single row at a time. This is not the case.
In this code sample, a multi row update is performed but the trigger is written so it expects a single row update.
use tempdb go create table t1 (id int primary key, t1_value varchar(50)) insert into t1 select 1, 'value1' insert into t1 select 2, 'value2' insert into t1 select 3, 'value3' create table t2 (id int primary key, t2_value varchar(50)) insert into t2 select 1, NULL insert into t2 select 2, NULL insert into t2 select 3, NULL go create trigger update_t2 on t1 for update as begin set nocount on declare @id int, @t1_value varchar(50) select @id = id, @t1_value = t1_value from inserted update t2 set t2_value = @t1_value where id = @id end go update t1 set t1_value = cast(id as varchar(50)) go
Examining the data, we see that the trigger does not correctly work on all the updated rows.
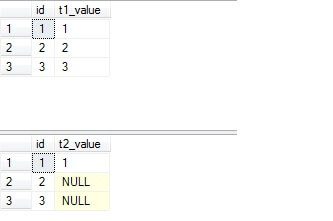
You may thinking to yourself, "That's ok, we only update 1 row at time in our application, anyway". What if data requires manual update via the Management Studio, a patch script, or a conversion script? This lurking flaw may render the data inconsistent.
Write all your triggers with the assumption that more than 1 row will be affected as in the following trigger re-write.
alter trigger update_t2 on t1111111 for update as begin set nocount on update t2 set t2_value = i.t1_value from inserted as i inner join t2 on t2.id = i.id end go update t1 set t1_value = cast(id as varchar(50)) go
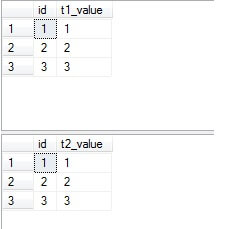
I tend to minimize the use of triggers to very specific tasks since troubleshooting data issues can be extremely painful to perform with too many of them in place.
Additional Information
- Understanding SQL Server inserted and deleted tables for DML triggers
- Foreign Key vs. Trigger Referential Integrity in SQL Server
- Forcing Trigger Firing Order in SQL Server
