By: Ben Snaidero
Overview
There are many different scenarios when an index can help the performance of a query and ensuring that the columns that make up your JOIN predicate is an important one.
Explanation
In order to illustrate this point let's take a look at a simple query that joins the Parent and Child tables. We'll keep this result set small by including a ParentID filter in the WHERE clause. Here is the statement.
SELECT *
FROM [dbo].[Parent] P INNER JOIN
[dbo].[Child] C ON P.ParentID=C.ParentID
WHERE P.ParentID=32433Looking at the explain plan for this query we can see that the SQL Optimizer has to perform an index scan on the Child table even though we are only looking for a specific ParentID from the Parent table.
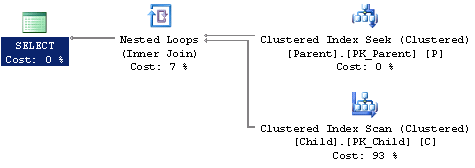
Let's add an index on the join column, Child.ParentID, and see how this effects the explain plan. Here is the SQL statement.
CREATE NONCLUSTERED INDEX idxChild_ParentID ON [dbo].[Child] ([ParentID]) -- cleanup statements DROP INDEX Child.idxChild_ParentID
Using the same query above if we regenerate the explain plan after adding the index we see below that the SQL Optimizer is now able to access the Child table using an index seek which will more than likely run much faster and use less resources.
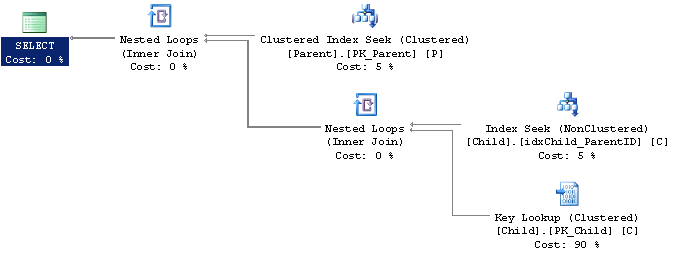
Let's confirm our assumption by taking a look at the SQL Profiler output of both queries. We see below that we were correct in our assumption. With the index added the query ran much faster, used much less CPU and performed way fewer reads.
| CPU | Reads | Writes | Duration | |
|---|---|---|---|---|
| No Index | 110 | 14217 | 0 | 110 |
| Index | 0 | 63 | 0 | 0 |
There is one other thing I'd like to mention when it comes to adding indexes on join columns. As a general guideline I usually start out by indexing all of my foreign key columns and only remove them if I find that they have a negative impact. I recommend this practice because more often than not these are the columns that the tables are joined on and you tend to see a pretty good performance benefit from having these columns indexed.
