By: Siddharth Mehta
Overview
In this section we will cover things you should know about statistics which will help you better understand machine learning.
Use of Statistics in Machine Learning
Machine Learning has very deep roots in mathematics and statistics. Mentioned below are the different phases of a machine learning model development with their order.
- Data Exploration – Structural data analysis like central tendency, probability, variance, etc.
- Data Standardization – Feature extraction, Normalization, Noise filtering, etc.
- Data Transformation (optionally if required) – Dimensionality reduction, Feature selection, etc.
- Model Development and Training
- Model Testing
- Model Improvisation
In a machine learning model development process, the first step is to explore the data. Here exploration does not mean querying the data from a data source using complex queries, functions or joins. The intent of exploration is to assess the balance in data from a statistical standpoint for developing a machine-learning model. If the data is not balanced, it may require standardization and transformation as well. Upon identifying the input attributes, a machine-learning model is developed and trained with a significant portion of the data. The rest of the data tests the model’s prediction accuracy. Improvising a model’s prediction accuracy is an iterative process until it reaches a satisfactory confidence level.
A few terms in the text above may seem unfamiliar to you. The reason for this is that these are purely statistical terms that have great significance in the machine learning model development process. This highlights a very important point. It requires strong fundamental knowledge of statistics to develop machine-learning models. We will try to cover some ground on a few basic concepts in this section, and will look at some useful resources for learning in more detail.
Branches of Statistics
In general, we categorize statistics in two braches at a higher level – Descriptive and Inferential.
Descriptive statistics explains summary and organization of data and describes a sample. The main parts of descriptive statistics are Measures of Central Tendency, Measures of Variability, and Correlation. We will be looking at all of these in the next section. This branch of statistics forms the basis of any quantitative analysis. To get more perspective of descriptive statistics, you can read more here.
Inferential statistics interprets data and determines statistical significance, and draws conclusions about a broader unknown dataset from a sample dataset. The foundation of inferential statistics lies in the theory of Hypothesis Testing and Central Limit Theorem. Learning this is imperative for any machine-learning professional. Based on inferential statistics, a number of algorithms deals with a specific type of predictive analysis problem. Machine learning models use these algorithms, which means that it needs a detailed understanding of the algorithm before applying.
Statistical Terms and Concepts
After learning that Machine Learning has deep roots in statistics, one may want to brush up on basic concepts of statistics. Learning statistics in detail is beyond the scope of this tutorial. However, we will touch upon a few basic concepts of statistics that will help get you started on brushing up your fundamentals.
Let us learn some terms of statistics with an example. Consider an experiment where we intend to find the average age of people who drink beer in the United States. It is almost impossible to capture the age of every person who drinks beer. The entire dataset of people who drink beer is termed as the Population. In order to derive the average age, we can consider conducting surveys in different major cities of the USA (maybe in every state) and gather the age of a fixed number of randomly chosen people of different ages who drink beer. This subset of people is termed as the Sample.
Consider that we want to derive the intelligence to predict the volume of beer one would consume given the age of the person. We can plot the data of average age of a person vs. average volume of beer consumed on a scatterplot to study this relationship. Here age would determine the volume of beer consumed. So age is termed as an Independent or Explanatory variable, and volume of beer is termed as a Dependent or Response variable. Statistical algorithms are applied on different combinations or sets of independent and dependent variables to develop a machine learning model. Most of the machine learning algorithms assume normal distribution of data. Below is an image of a normal distribution curve, also termed as the “Bell Curve”.
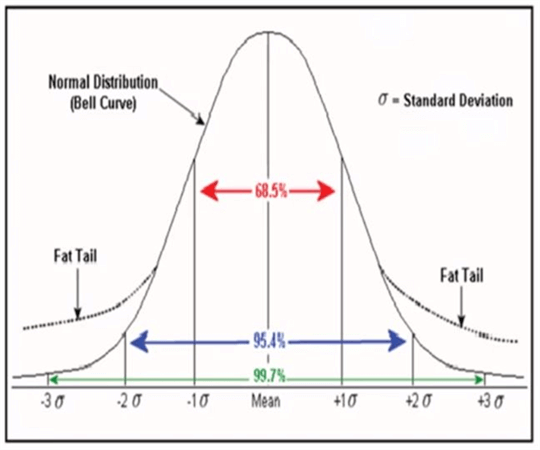
You can consider yourself a novice in Machine Learning once you can thoroughly explain the above diagram. Educating yourself in statistics is necessary to learn machine learning. Consider reading a detailed list of statistical terms from this glossary, and invest time in understanding the significance and usage of these terms. The glossary document consists of concise definitions of frequently used statistical terms in data science or machine learning parlance, which may not have enough material to explain each term in detail. The easiest method of finding detailed explanations of each term is by searching Wikipedia or any statistics portal. There is more than enough material freely available for learning these concepts. After you learn the different concepts, your understanding should evolve to be able to explain the above diagram, its significance and its applications.
How to study just enough statistics for Machine Learning?
Any explanation of Machine Learning algorithms would start with statistics behind it. The statistics is generally at a higher level as explaining it from the ground level would require a separate book itself for each algorithm. This poses a challenge to professionals who want to understand the algorithms, but do not have the right statistical background to learn the concepts. Any book / tutorial / class on Machine Learning would look like a mathematics class without the right foundation of statistics. So, the question is how to learn just enough statistics without reaching the point of breakdown where you lose interest or give-up machine learning due to the struggle of learning more and more about statistics?
Everyone has different approaches to learning new concepts based on their likes or dislikes. One way I recommend is to follow a top-down approach to identify the best starting point. You can start from any topic in statistics. If you do not have the background to understand the topic, keep moving on to the lower-level connected topic until you reach the lowest level topic. For example, let's say you started with a machine learning algorithm, which speaks about different statistical terms, of which one term is Normal Distribution.
- You may not understand the characteristics of a Normal Distribution, if you already do not know Standard Deviation.
- You may not understand Standard Deviation, how it is calculated and the significance if you do not know Variance.
- In order to understand Variance, you need to know Mean and the formula to calculate Variance.
- Mean is independent of any other statistical derivation and is part of elementary mathematics.
So, in this way you can deduce to the point where you have the right background to understand the most basic topic and slowly build-up until you reach the statistical terms used in machine learning algorithms.
Useful Links to Reference Materials
- Basics of Statistics
- Variables
- Sampling
- Descriptive Statistics
- Central Limit Theorem
- Measures of Central Tendency
- Measures of Dispersion
- Measures of Association
- Normal Distribution
Additional Information
- Consider reading the reference material from these links before moving on to the next section. We will be applying the concepts learned from these links in the next section using R and T-SQL.
