Overview
You’ll hear the term instance a lot when referring to the SQL Server suite of products. Whether it’s the database engine, Analysis Services, Reporting Services, or Integration Services, when someone refers to an instance of the product. This basically means a copy of the executable that is running as a Windows service. For the database engine, this is sqlservr.exe, for Analysis Services it’s the msmdsrv.exe, for Integration Services it’s the MsDtsSrvr.exe, and for Reporting Services it’s the ReportingServicesService.exe. As far as the architecture goes, that is where the similarities between the different products ends. The below sections will give an overview of the rest of the architecture for each of the main products.
Explanation
Database Engine
The engine of the instance can be broken down into two parts. The Relational Engine and the Storage Engine.
The Relational Engine handles the execution of queries as they are received from client applications. This engine has the following components: Query Parser, Optimizer/Planner, and Executor.
The Storage Engine handles the actual accessing of the data as requested by the query executor. Within this engine there is a transaction manager and buffer manager that interact with the data and log files to select/insert/update/delete data as required.
Databases
Each SQL Server instance contains 4 or more databases, which are, at a high level, simply a logical collection of objects. These objects can include tables, indexes, views, users, etc. The initial databases that exist are the system databases: master, model, msdb, and tempdb.
- The master database contains all the server configuration settings,
- The model database serves as a template that is used when user databases are created,
- The msdb database contains information related to database backups, replication, SSIS packages, and all the configuration information for any SQL Server jobs that exist on the server
- And finally, the tempdb database stores any temporary objects that are required by the system.
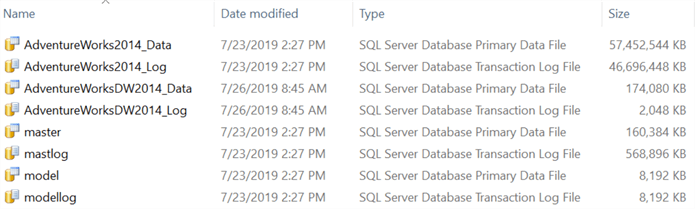
Database Files
Each of these databases is made up of at least 2 files. The first is the primary datafile, which stores the objects that make up the database. The second is the transaction log file, which holds all the information related to any changes made to the database. There can be one or more of each of these types of files, although having multiple transaction logs won’t really help performance as this file is written to sequentially. Data files, on the other hand, can benefit from having multiple files. For example, by separating table and index data into different data files, you can speed up performance as these files can then be accessed in parallel when executing a query. Both of these files are stored on the server’s filesystem and can be placed where required by specifying the file path when the database is created.
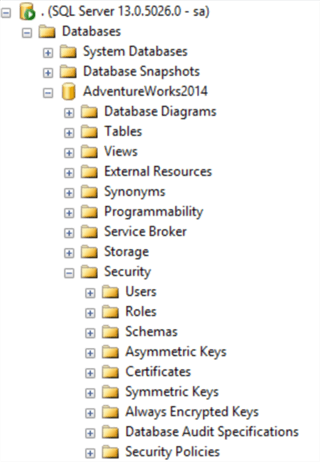
Database Objects
As mentioned above, each database is a collection of different objects. Below is a brief description of the most common objects that you will find in a SQL Server database.
- User/Login – Sometimes used interchangeably in SQL Server, they are in fact two different things. A login is used for authentication to the database instance, whereas a user is used for database/object access. Each login will have an associated database user (most often with the same name).
- Role – An object that contains a set of permissions for objects within the database. Can be granted to users to ease administration by not having to grant individual permissions to each user.
- Schema – Schema can have many different meanings in a database context, but here it can be described as something that holds a collection of objects, kind of like a container or namespace. Other objects like tables, indexes, functions, etc. can be grouped logically and assigned to a schema on creation.
- Table – Object that holds the relational data.
- Constraint – These are rules for the data columns in a table. Types of constraints are primary key, foreign key, default, etc.
- Index – This is a structure that can be used to speed up accessing data in a table. Specified columns make up the index and, when specified in a query, can help to speed up performance as the indexed column will contain a pointer to where the rest of the data is located that makes up that row.
- Statistics – Statistics are a set of data that describes the data distribution and cardinality of the columns in a table. These statistics are used by the planner in order to determine the best/fastest method of accessing the table in order to execute a query.
- View – A view is basically a stored query. Sometimes a query can be so complex that it is created as a view so that other connections can just write “SELECT * FROM view”. Note that the actually result set from the query is not stored/cached (this is done for materialized views), only the query text, so each call to the view results in the entire query being executed.
- Stored Procedure/Function – Both of these objects, as you would assume, are objects that store a collection of SQL statements, and other than this one similarity, they do not have much in common. Some of the key differences are: Functions can only run SELECT and a stored procedure can also run DELETE/INSERT/UPDATE, stored procedures can have both input and output parameters whereas functions can only have input, functions can be used in one or many parts of a SELECT query and stored procedures cannot be used, stored procedures can optionally return a value whereas function must return a value, etc.
Analysis Services
Similar to the database instance, an Analysis Services database is really just a logical collection of objects. Each SQL Server Analysis Services instance can have multiple user databases similar to a database instance, but with Analysis Services, there are no system databases. There is a master.vmp file in the data directory that contains a version map of all the GUIDs for each object in the server. If this file is missing or corrupt, the Analysis Services service will not start. The file structure of an analysis service instance is also much more complex than a database instance. For each database that exists, there is an XML file that displays the properties of the database as well as a folder that contains the data.

Dimension Objects
Within the database folder, there are again XML files which describe the cube and dimension objects properties as well as folders for each of these object types.


Inside each dimension object folder, there are the data files for the dimension.

Cube Objects
In the cube object folder, we again have an XML file and a folder for each measure defined in the cube.

Analysis Services Objects
The objects contained within an Analysis Services database are very different from what we see in a relational database, and below is a short description of the most common objects that would be present in an Analysis Services database.
- Cube – This is a multi-dimensional database that is designed specifically to handle data warehouse and online analytical processing workloads.
- Dimension – Dimensions are structures that categorize or describe facts and measures and are usually organized into a hierarchy. Examples of dimensions are time, places, products, etc. Using time as an example, the hierarchy could be days -> weeks -> months -> quarters -> years.
- Measure – A measure is the actual data element. Since measures are numeric, they can be summed, averaged, etc. across some, all, or none of the defined dimensions.
- Mining structures – A mining structure defines the data upon which any mining models are built. One mining structure can support multiple mining models.
- Role – Similar to the database instance roles in Analysis Services, define the objects that a user can access.

Reporting Services
With regards to the architecture of Reporting Services, for this tutorial, we won’t go into any detail in the creation of a report other than to say the .rdl files that are used to define a report can be created using Report Builder or the SSDT application. Once created this .rdl file can then be deployed to a SQL Server Reporting Services instance. The instance itself is a Windows service that is backed by two databases. By default, these databases are named ReportServer and ReportServerTempDB as shown below.

The ReportServer database stores metadata (basically data defined in .rdl) for each reports configuration. This includes the report data sources as well as the definition of the report itself. It also stores metadata related to the scheduling of each report, if one has been defined after the report has been deployed. From a data perspective, snapshot and historical report data it also stored here until their retention time is reached.
The ReportServerTempDB is only used during runtime and stores temporary data, session information, and cached report data.
Integration Services
Similar to Reporting Services, SQL Server Integration Services packages are created by using SSDT. Once created, the .dtsx file containing the package definition can then be deployed to any SQL Server Integration Services instance. The Integration Services instance is also just a Windows, service except in this case, there is no special database associated with the service. In the case of SQL Server Integration Services, packages can either be deployed and stored on the filesystem or in the instance. If deployed to the instance, they are stored within the msdb database in the tables shown below.

There is also no functionality for scheduling package execution built into SQL Server Integration Services. If you require that a package be executed on a schedule, you can either use the SQL Server Agent or the Windows Task scheduler to handle this requirement.
Additional Information

Ben Snaidero has been a Database Administrator for just over 10 years. Starting out working mainly with Oracle he got into SQL Server in 2005 and has worked primarily with SQL Server for the last 3 years. His main focus with both Oracle and SQL Server is in the area of performance tuning.
- MSSQLTips Awards: Achiever (75+ tips) – 2018 | Author of the Year Contender – 2016-2017


