Problem
A junior colleague is joining our data engineering team. I’m tasked with their onboarding. Currently, we use a mixture of Azure Data Factory (ADF) and Fabric Pipelines as we’re in the middle of a migration. What are the most important things about ADF that I should mention?
Solution
Azure Data Factory is a cloud integration tool, a part of the Microsoft Data Platform in Azure. It focuses heavily on ETL orchestration, but with the mapping dataflows feature, you can create ELT flows in a low-code environment, similar to the Integration Services dataflows. The product is still present in Azure, gets regular updates, and has been reincarnated twice: once in Synapse Analytics (branded Synapse Pipelines) and once in Microsoft Fabric (branded as Data Factory or Fabric Pipelines).
In this tip, we’ll present some ADF best practices, or things you should know when you need to work with this tool. The provided information will be valid for the three versions of Data Factory (ADF, Synapse, and Fabric), unless indicated otherwise. Learn more about Azure Data Factory.
Azure Data Factory Must-Knows
In this first part of the tip, we’ll talk about the different versions of ADF and their differences, and how their costs are calculated.
They’re All the Same. But Also, Different.
There are currently three implementations of ADF:
- Azure Data Factory: which is a resource in Azure and development is done in Azure Data Factory Studio.
- Data Factory in Azure Synapse Analytics: Data Factory is part of the Synapse workspace.
- Data Factory in Microsoft Fabric: Here, Data Factory is one of the workloads inside the Fabric service.
All three are very similar; development is always done in the browser. And fundamentally, you’re always doing the same thing: creating pipelines that move data from one location to another or orchestrate activities. However, there are differences between the three implementations.
ADF and Synapse Analytics Overlap
The biggest overlap is between ADF and Synapse Analytics. The differences here are more subtle. For example, Synapse doesn’t support global parameters.
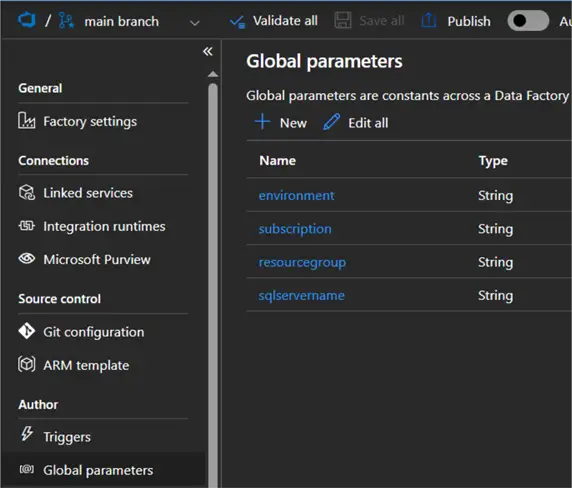
The concept of creating a linked service and a dataset are the same between ADF and Synapse, but in ADF the creation of datasets and pipelines (and data flows) is in the same authoring pane.
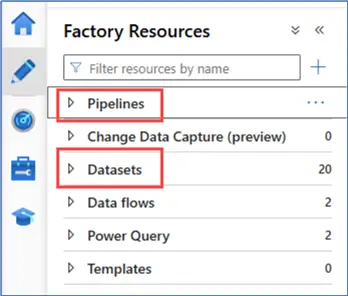
In Synapse, pipelines have their own authoring pane called Integrate.
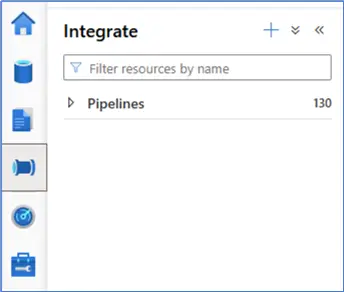
Datasets in Synapse can be found in the Data section, under the Linked tab, grouped by Integration datasets. Dataflows are situated in the Develop section.
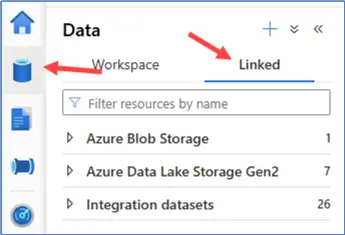
Most activities are the same, but Synapse has an extra SQL pool stored procedure activity, which is very similar to the general stored procedure activity.
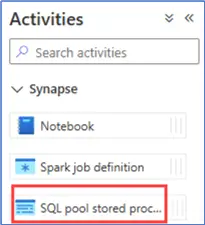
Fabric, Synapse and Azure Data Factory Comparison
There are bigger differences between Fabric and the other two data factories. For example, Fabric has the Office 365 activity, which allows you to send emails directly from a pipeline. This functionality is missing from ADF, but there are workarounds (such as Azure Logic Apps, Microsoft Graph, or Azure Communication Services). There’s also no concept of datasets as separate entities. They are rather defined inline in the activity.
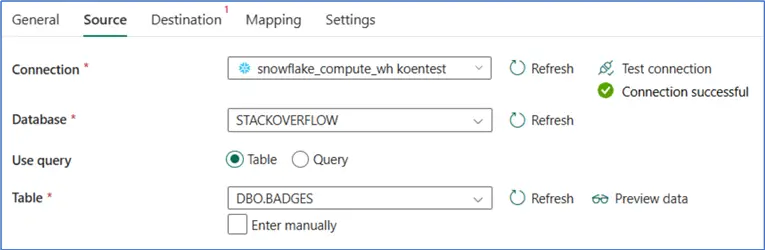
The concept of linked services does exist, but they are rather “reincarnated” as connections, like they’ve always been used in the Power BI service. You can create them inline at an activity, but you can also manage them from the settings menu:
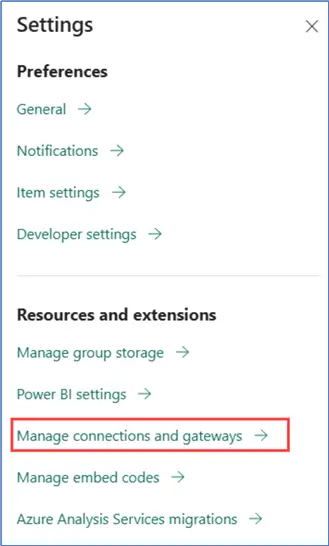
There you can find all the connections, not only from Data Factory, but also from Power BI dataflows Gen1 or semantic model connections.
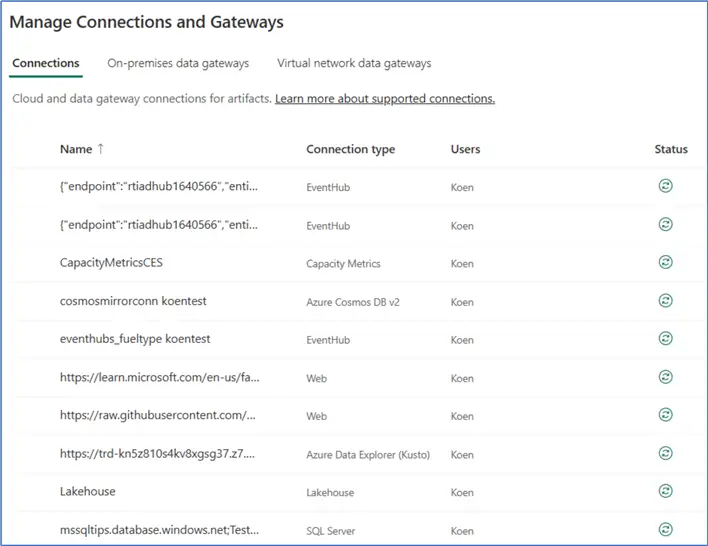
Connection Management
There are several problems with the current state of connection management:
- Only very recently, support for Azure Key Vault was announced and it is now in private preview.
- Connections have an owner. If someone creates a connection in a pipeline but doesn’t share it with you, you cannot see the connection when you try to edit the pipeline.
- Internal connections can now be parameterized using variable libraries (at the time of writing this feature was just released in public preview), but external connections still don’t support parameterization. This complicates CI/CD of the data pipelines in Fabric.
Synapse and Azure Data Factory are both billed the same, while the Fabric Data Factory compute is billed through the Fabric capacity, like (almost) any other workload in Fabric. More details about how the billing works for ADF are discussed in the next section.
To conclude, the three implementations of Data Factory have much overlap in functionality, and the important differences are mainly between Fabric and the other two. At the moment, Fabric Data Factory is the least mature, but this gap will close when new additions are made in Fabric.
How is the Pricing Calculated?
Several components inside Azure/Synapse Data Factory incur costs. It would take us too long to discuss everything in detail (more information: Data Pipeline pricing). However, three main categories contribute the most to the cost:
- Pipelines
- Dataflows
- SSIS Integration Runtime
Dataflows
Dataflows run a Spark environment, and this is managed through an Azure Integration Runtime. In short, you pay for the time this IR is running, and the cost per minute is determined by the size of the cluster.
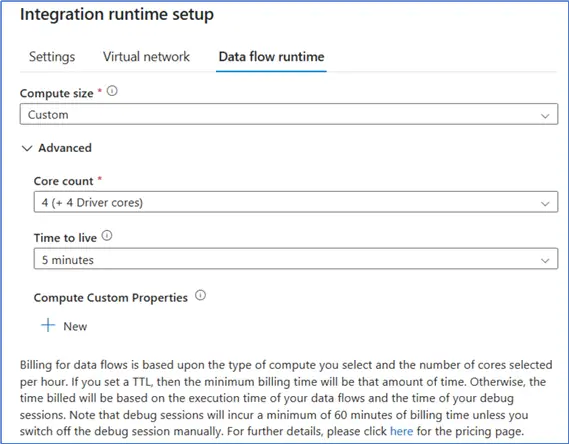
The SSIS Integration Runtime operates on the same principle: you pay for the amount of time and the size of the cluster.
Pipeline Pricing
The cost of running a pipeline is a bit more complicated. It is based on these factors:
- Type of runtime used
- Run the pipeline in the cloud: The AutoResolveIntegrationRuntime (which is a special type of the normal Azure runtime) is used by default.
- Use a self-hosted IR: The cost is drastically lower because you’re essentially running the compute yourself.
- Use a managed VNET: The cost can be drastically higher (up to 10,000 times!).
- Type of activity. There are three types of activities in a pipeline:
- Pipeline activities (lookup, get metadata, delete, etc.) Pipeline activities are quite cheap as well.
- External activities (stored procedure, script component, run notebook, etc.). External activities are the cheapest because the compute is run somewhere else.
- Data movement (copy data activity). But a copy data activity can be quite expensive. It has a cost per DIU-hour (DIU = data integration unit, which is a setting of the copy data activity). This means that you pay for the amount of time the copy data activity is running and the size of the compute ADF is using behind the scenes to do the copy (which is again similar to how the other Integration Runtimes are billed).
- Amount of run time. This billing is prorated by the minute and rounded up. For example, if you have a stored procedure activity running for 20 seconds, you pay for a full minute. If it runs for 61 seconds, you pay for two minutes. Very important: Each activity has its own timer! If you have 5 activities in a pipeline, you will be billed for at least 5 minutes, even though the entire pipeline might’ve executed in 40 seconds. This also means that if you have a ForEach loop iteration 100 times (i.e., executing a copy data activity to copy 100 files to a database), you will be billed for at least 100 minutes.
Example Pricing Scenario
Let’s illustrate this last point with an example. I have a pipeline with a couple of activities and a ForEach loop with a Copy Data activity inside it. When the pipeline is executed, it finishes in less than 3 minutes. The ForEach has executed 100 times.
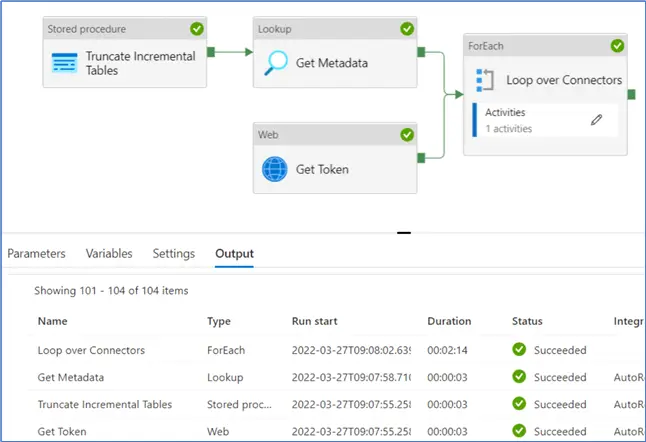
However, if we check the debug run consumption, we can say that we are billed for over 100 minutes.
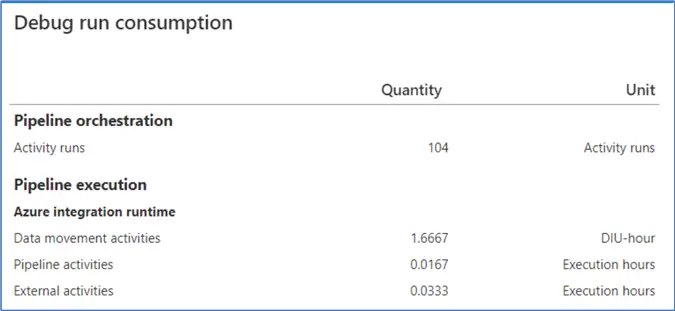
1.6667 hours equals 100 minutes. If we look up the prices, executing this entire pipeline would cost roughly $0.84. This doesn’t seem like much, but if you execute this pipeline every 5 minutes, the total monthly cost would be around $7200. Data Factory is meant for batch processing, not for real-time data processing. The pro-rated cost per minute will drive the costs too high to handle streaming data.
If you want more details on how costs are exactly calculated in Azure Data Factory, I can recommend this video by Cathrine Wilhelmsen.
Pricing in Fabric is more straightforward: pipelines consume an amount of capacity units (CU), and a Fabric capacity has a certain number of CUs available per second. If you need more, you need a bigger capacity, which makes your costs go up. You pay for the amount of time your Fabric capacity is running.
Next Steps
- Stay tuned for Part 2 of this tip, where we’ll discuss more Data Factory best practices.
- If you want to learn more about ADF, check out the tutorial, or this overview of all ADF tips.
- You can find Microsoft Fabric-related tips in this overview.
