Problem
Having a background as a SQL Server DBA, I’ve worked with SSIS for on-premises data sources for quite some time. Now with Microsoft’s new cloud integration tool, Azure Data Factory, there has been a bit of learning curve. In these series of posts, I am going to explore Azure Data Factory, compare its features against SSIS and show how it can be used with for real-life data integration problems to help make the transition easier for you.
Solution
What is Azure Data Factory?
Azure Data Factory (ADF) is a cloud integration system, which allows moving data between on-premises and cloud systems as well as scheduling and orchestrating complex data flows. ADF is more of an Extract-and-Load and Transform-and-Load platform rather than a traditional Extract-Transform-and-Load (ETL) platform. To achieve Extract-and-Load goals, you can use the following approaches:
- ADF has built-in features to configure relatively simple data flows to transfer data between file systems and database systems located both on-premises and on the cloud. ADF is capable of connecting to many different database systems, like SQL Server, Azure SQL Database, Oracle, MySQL, DB2, as well as file storage and Big Data systems like the local file system, blob storage, Azure Data Lake, and HDFS.
- Alternatively, you could also use ADF to initiate SSIS packages. This could be handy if you need to implement more sophisticated data movement and transformation tasks.
As for transformation tasks, ADF can provision different Azure services on the fly and trigger scripts hosted by different databases and other data processing systems, like Azure Data Lake Analytics, Pig, Hive, Hadoop, and Azure Machine Learning API services.
Why Azure Data Factory?
While you can use SSIS to achieve most of the data integration goals for on-premises data, moving data to/from the cloud presents a few challenges:
- Job scheduling and orchestration. SQL Server Agent services, which is the most popular to trigger data integration tasks is not available on the cloud. Although, there are a few other alternatives, like SQL Agent services on SQL VM, Azure scheduler, and Azure Automation, for data movement tasks, job scheduling features included in ADF seems to be best. Furthermore, ADF allows build event based data flows and dependencies. For example, data flows can be configured to start when files are deposited into a certain folder.
- Security. ADF automatically encrypts data in-transit between on-premises and cloud sources.
- Scalability. ADF is designed to handle big data volumes, thanks to its built-in parallelism and time-slicing features and can help you move many gigabytes of data into the cloud in a matter of a few hours.
- Continuous integration and delivery. ADF integration with GitHub allows you to develop, build and automatically deploy into Azure. Furthermore, the entire ADF configuration could be downloaded as an Azure ARM template and used to deploy ADF in other environments (Test, QA and Production). For those who are skilled with PowerShell, ADF allows you to create and deploy all of its components, using PowerShell.
- Minimal coding required. ADF configuration is based on JSON files and a new interface coming with ADF v2 allows creating components from the Azure Portal interactively, without much coding (which is one reason why I love Microsoft technologies!).
Azure Data Factory – Main Concepts
To understand how ADF works, we need to get familiar with the following ADF components:
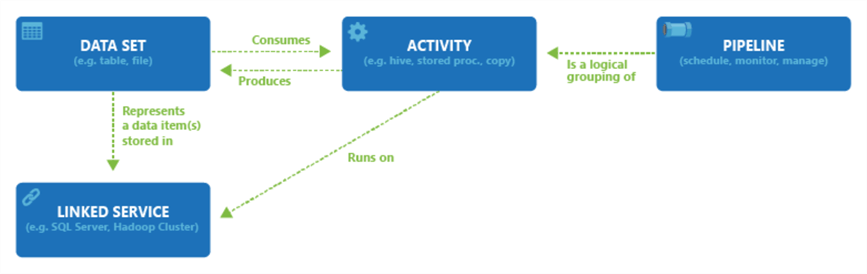
- Connectors or Linked Services. Linked services contain configuration settings to certain data sources. This may include server/database name, file folder, credentials, etc. Depending on the nature of the job, each data flow may have one or more linked services.
- Datasets. Datasets also contain data source configuration settings, but on a more granular level. Datasets can contain a table name or file name, structure, etc. Each dataset refers to a certain linked service and that linked service determines the list of possible dataset properties. Linked services and datasets are similar to SSIS’s data source/destination components, like OLE DB Source, OLE DB Destination, except SSIS source/destination components contain all the connection specific information in a single entity.
- Activities. Activities represent actions, these could be data movement, transformations or control flow actions. Activity configurations contain settings like database query, stored procedure name, parameters, script location, etc. An activity can take zero or more input datasets and produce one or more output datasets. Although, ADF activities could be compared to SSIS Data Flow Task components (like Aggregate, Script component, etc.), SSIS has many components for which ADF has no match yet.
- Pipelines. Pipelines are logical groupings of activities. A data factory can have one or more pipelines and each pipeline would contain one or more activities. Using pipelines makes it much easier to schedule and monitor multiple logically related activities.
- Triggers. Triggers represent scheduling configuration for pipelines and they contain configuration settings, like start/end date, execution frequency, etc. Triggers are not mandatory parts of ADF implementation, they are required only if you need pipelines to be executed automatically, on a pre-defined schedule.
- Integration runtime. The Integration Runtime (IR) is the compute infrastructure used by ADF to provide data movement, compute capabilities across different network environments. The main runtime types are:
- Azure IR. Azure integration runtime provides a fully managed, serverless compute in Azure and this is the service behind data movement activities in cloud.
- Self-hosted IR. This service manages copy activities between a cloud data stores and a data store in a private network, as well as transformation activities, like HDInsght Pig, Hive, and Spark.
- Azure-SSIS IR. SSIS IR is required to natively execute SSIS packages.
Here is a diagram, representing relationships between the different ADF entities, borrowed from the Microsoft site:
So, where to start?
ADF is an Azure service and requires an Azure subscription. If you do not have an Azure subscription, you can get one free for a limited time from here. You can create ADF and do all of the required configurations directly on the Azure Portal. Alternatively, you can install Microsoft Azure DataFactory Tools for Visual Studio 2015, create an ADF project and deploy it to Azure. ADF currently has two versions, v1 and v2 and I will mostly be focusing on v2 as it has much more advanced functionality than v1. As with many other technologies, it is easier to learn ADF by trying it and I will provide step-by-step guidance in future posts to get your hands dirty.
Next Steps
- Stay tuned for additional tips related to this subject.
- Check out these other Azure tips.
- Read Azure Data Factory Documentation

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021

