Problem
In my last article, Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2, I discussed how to create a pipeline parameter table in Azure SQL DB and drive the creation of snappy parquet files consisting of On-Premises SQL Server tables into Azure Data Lake Store Gen2. Now that I have a process for generating files in the lake, I would also like to implement a process to track the log activity for my pipelines that run and persist the data. What options do I have for creating and storing this log data?
Solution
Azure Data Factory is a robust cloud-based E-L-T tool that is capable of accommodating multiple scenarios for logging pipeline audit data.
In this article, I will discuss three of these possible options, which include:
- Updating Pipeline Status and Datetime columns in a static pipeline parameter table using an ADF Stored Procedure activity
- Generating a metadata CSV file for every parquet file that is created and storing the logs in hierarchical folders in ADLS2
- Creating a pipeline log table in Azure SQL Database and storing the pipeline activity as records in the table

Prerequisites
Ensure that you have read and implemented Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2, as this demo will be building a pipeline logging process on the pipeline copy activity that was created in the article.
Option 1: Create a Stored Procedure Activity
The Stored Procedure Activity is one of the transformation activities that Data Factory supports. We will use the Stored Procedure Activity to invoke a stored procedure in Azure SQL Database. For more information on ADF Stored Procedure Activity, see Transform data by using the SQL Server Stored Procedure activity in Azure Data Factory.
For this scenario, I would like to maintain my Pipeline Execution Status and Pipeline Date detail as columns in my Pipeline Parameter table rather than having a separate log table. The downside to this method is that it will not retain historical log data, but will simply update the values based on a lookup of the incoming files to records in the pipeline parameter table. This gives a quick, yet not necessarily robust, method of viewing the status and load date across all items in the pipeline parameter table.
I’ll begin by adding a stored procedure activity to my Copy-Table Activity so that as the process iterates on a table level basis for my stored procedure.
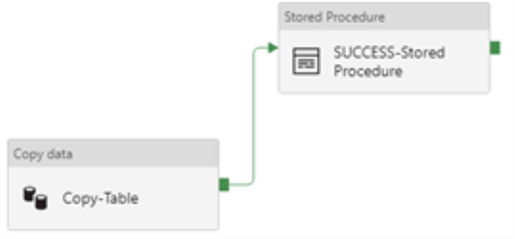
Next, I will add the following stored procedure to my Azure SQL Database where my pipeline parameter table resides. This procedure simply looks up the destination table name in the pipeline parameter table and updates the status and datetime for each table once the Copy-Table activity is successful.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE PROCEDURE [dbo].[sql2adls_data_files_loaded] @dst_name NVARCHAR(500) AS SET NOCOUNT ON -- turns off messages sent back to client after DML is run, keep this here DECLARE @Currentday DATETIME = GETDATE BEGIN TRY BEGIN TRANSACTION -- BEGIN TRAN statement will increment transaction count from 0 to 1 UPDATE [dbo].[pipeline_parameter] set pipeline_status = 'success', pipeline_datetime = @Currentday where dst_name = @dst_name COMMIT TRANSACTION -- COMMIT will decrement transaction count from 1 to 0 if dml worked END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK -- Return error information. DECLARE @ErrorMessage nvarchar(4000), @ErrorSeverity int SELECT @ErrorMessage = ERROR_MESSAGE(),@ErrorSeverity = ERROR_SEVERITY RAISERROR(@ErrorMessage, @ErrorSeverity, 1 END CATCH GO
After creating my stored procedure, I can confirm that it has been created in my Azure SQL Database.
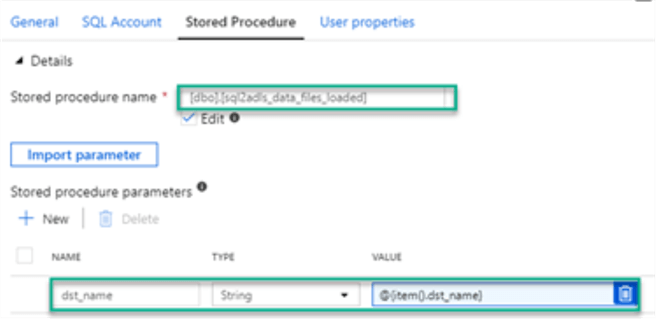
I will then return to my data factory pipeline and configure the stored procedure activity. In the Stored Procedure tab, I will select the stored procedure that I just created. I will also add a new stored procedure parameter that references my destination name, which I had configured in the copy activity.
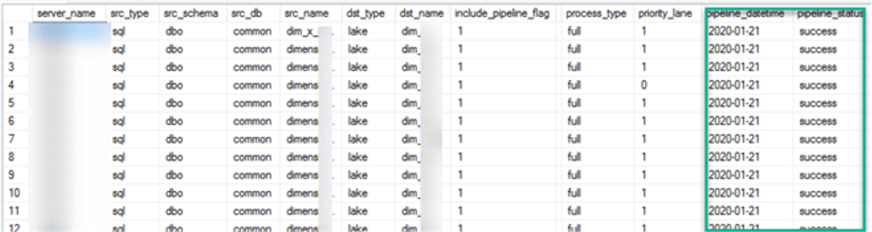
After saving, publishing and running the pipeline, I can see that my pipeline_datetime and pipeline_status columns have been updated as a result of the ADF Stored Procedure Activity.
Option 2: Create a CSV Log file in Azure Data Lake Store2
Since my Copy-Table activity is generating snappy parquet files into hierarchical ADLS2 folders, I also want to create a metadata .csv file which contains the pipeline activity. For this scenario, I have set up an Azure Data Factory Event Grid to listen for metadata files and then kick of a process to transform my table and load it into a curated zone.
I will start by adding a Copy activity for creating my log files and connecting it the Copy-Table activity. Similar to the previous process, this process will generate a .csv metadata file in a metadata folder per table.
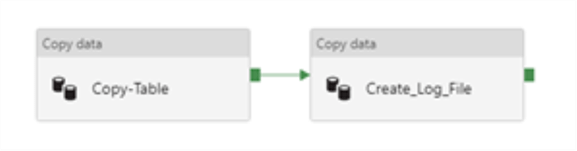
To configure the source dataset, I will select my source on-premise SQL Server.
Next, I will add the following query as my source query. As we can see, this query will contain a combination of pipeline activities, copy table activities, and user-defined parameters.
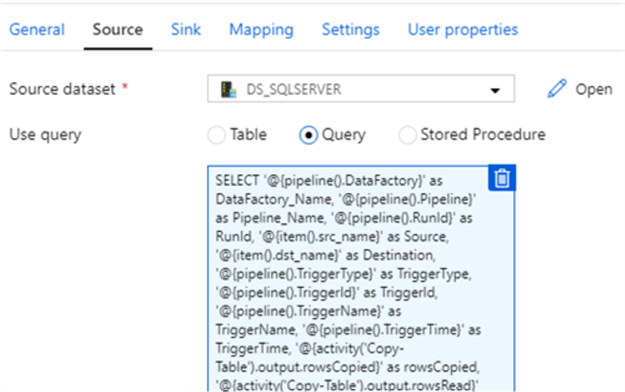
SELECT '@{pipeline().DataFactory}' as DataFactory_Name,
'@{pipeline().Pipeline}' as Pipeline_Name,
'@{pipeline().RunId}' as RunId,
'@{item().src_name}' as Source,
'@{item().dst_name}' as Destination,
'@{pipeline().TriggerType}' as TriggerType,
'@{pipeline().TriggerId}' as TriggerId,
'@{pipeline().TriggerName}' as TriggerName,
'@{pipeline().TriggerTime}' as TriggerTime,
'@{activity('Copy-Table').output.rowsCopied}' as rowsCopied,
'@{activity('Copy-Table').output.rowsRead}' as RowsRead,
'@{activity('Copy-Table').output.usedParallelCopies}' as No_ParallelCopies,
'@{activity('Copy-Table').output.copyDuration}' as copyDuration_in_secs,
'@{activity('Copy-Table').output.effectiveIntegrationRuntime}' as effectiveIntegrationRuntime,
'@{activity('Copy-Table').output.executionDetails[0].source.type}' as Source_Type,
'@{activity('Copy-Table').output.executionDetails[0].sink.type}' as Sink_Type,
'@{activity('Copy-Table').output.executionDetails[0].status}' as Execution_Status,
'@{activity('Copy-Table').output.executionDetails[0].start}' as CopyActivity_Start_Time,
'@{utcnow()}' as CopyActivity_End_Time,
'@{activity('Copy-Table').output.executionDetails[0].detailedDurations.queuingDuration}' as CopyActivity_queuingDuration_in_secs,
'@{activity('Copy-Table').output.executionDetails[0].detailedDurations.timeToFirstByte}' as CopyActivity_timeToFirstByte_in_secs,
'@{activity('Copy-Table').output.executionDetails[0].detailedDurations.transferDuration}' as CopyActivity_transferDuration_in_secs
My sink will be a csv dataset with a .csv extension.
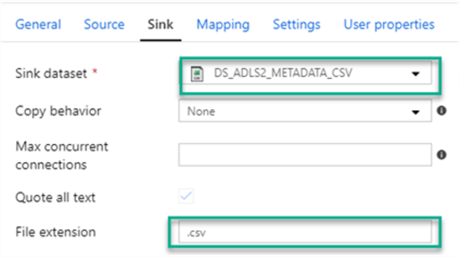
Below is the connection configuration that I will use for my csv dataset.

The following parameterized path will ensure that the file is generate in the correct folder structure.
@{item().server_name}/@{item().src_db}/@{item().src_schema}/@{item().dst_name}/metadata/@{formatDateTime(utcnow(),'yyyy-MM-dd')}/@{item().dst_name}.csv
After I save, publish, and run my pipeline, I can see that a metadata folder has been created in my Server>database>schema>Destination_table location.

When I open the metadata folder, I can see that there will be csv file per day that the pipeline runs.
Finally, I can see that a metadata .csv file with the name of my table has been created.
When I download and open the file, I can see that all of the query results have been populated in my .csv file.

Option 3: Create a log table in Azure SQL Database
My last scenario involves creating a log table in Azure SQL Database, where my parameter table resides and then writing the data to records in the ASQL table.
Again, for this option, I will start by adding a copy data activity connected to my Copy-Table activity.
Next, I will create the following table in my Azure SQL Database. This table will store and capture the pipeline and copy activity details.
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_log]( [DataFactory_Name] [nvarchar](500) NULL, [Pipeline_Name] [nvarchar](500) NULL, [RunId] [nvarchar](500) NULL, [Source] [nvarchar](500) NULL, [Destination] [nvarchar](500) NULL, [TriggerType] [nvarchar](500) NULL, [TriggerId] [nvarchar](500) NULL, [TriggerName] [nvarchar](500) NULL, [TriggerTime] [nvarchar](500) NULL, [rowsCopied] [nvarchar](500) NULL, [RowsRead] [int] NULL, [No_ParallelCopies] [int] NULL, [copyDuration_in_secs] [nvarchar](500) NULL, [effectiveIntegrationRuntime] [nvarchar](500) NULL, [Source_Type] [nvarchar](500) NULL, [Sink_Type] [nvarchar](500) NULL, [Execution_Status] [nvarchar](500) NULL, [CopyActivity_Start_Time] [datetime] NULL, [CopyActivity_End_Time] [datetime] NULL, [CopyActivity_queuingDuration_in_secs] [nvarchar](500) NULL, [CopyActivity_timeToFirstByte_in_secs] [nvarchar](500) NULL, [CopyActivity_transferDuration_in_secs] [nvarchar](500) NULL ) ON [PRIMARY] GO
Similar to my last pipeline option, I will configure my on-premise SQL server as my source and use the query provided in Option 2 as my source.

My sink will be a connection to the Azure SQL Db pipeline log table the I created earlier.

Below are the connection details for the Azure SQL DB pipeline log table.

When I save, publish and run my pipeline, I can see that the pipeline copy activity records have been captured in my dbo.pipeline_log table.

Next Steps
- For another practical example on ADF Stored Procedure Activity, read Azure Data Factory Stored Procedure Activity Transformation Activities

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


Hello!
Great article!
How would this be done for ‘Copy Files’ not Copy Table?
We copy files from an on premise file server via ADF, but I am not sure how to log the properties like was done for an SQL db table.
Suggestions on a start?
Thanks,
i have a ADF solution which is metadata driven, so it passes conenctgion string and source and sink as paramaters.. my conern is that i also have SQL Logging steps within pipelines and child pipelines and now for a simple Azure DB table copy into ADSL Parquet it is bottlenecked by the logging steps and child pieplines… i noticed that each step (mainly logging steps) take around 3-6 seconds? is there any way of reducing the time to execute logging steps??? i have tried upgrading the Config Database from basic to S1, i have tried changing the ADF’s integration runtime to 32 core count, i have changed the TTL to 20 Mins, and i have also checked the quick cache.. nothing seems to reduce the time to run these audit steps…
the audit step is a StoedProc which you pass in a load of paramaters. this proc run in split seconds in SSMS so the proc isnt the issue
In case sometime if copy activity do not have time to first byte parameter in that case it fails saying that parameter do not found. I am facing the same case.
Hello Ron,
Great post, thanks for sharing! Can we also retrieve into our .csv file how many bytes of data were processed by copy activity?
Hello Alex,
Yes of course, please see my related article on logging error details from ADF: https://www.mssqltips.com/sqlservertip/6712/azure-data-factory-pipeline-logging-error-details/
Sincerely,
Ron L’Esteve
Hi, thank you for a great article! Is it possible to pass an error message the same way in case of copy activity fail?