Problem
The process of moving data from an on-premises SQL Server to Azure Data Lake Storage has become an ever increasing and vital need for many businesses. Customers with numerous on-premises SQL servers along with hundreds of databases within these servers are interested in leveraging Azure’s Data Services to build an E-L-T process to fully load Azure Data Lake Storage with their on-premises SQL Server databases and tables in a structured, partitioned and repeatable process for all servers in their SQL Server ecosystem. How might they be able to solve for this problem and what tools could be used for the solution?
Solution
Azure Data Factory has been a critical E-L-T tool of choice for many data engineers working with Azure’s Data Services. The ability to leverage dynamic SQL and parameters within ADF pipelines allows for seamless data engineering and scalability. In this article, I will demo the process of creating an end-to-end Data Factory pipeline to move all on-premises SQL Server objects including databases and tables to Azure Data Lake Storage gen 2 with a few pipelines that leverage dynamic parameters.
Create Prerequisite Resources
Azure Data Factory V2: This will be used as the ETL orchestration tool. For more detail on setting up an ADFv2, visit: Quickstart: Create a data factory by using the Azure Data Factory UI
Azure Data Lake Store Gen2: The data will be stored in ADLS2. For more information on setting up ADLS2, visit: Create an Azure Data Lake Storage Gen2 storage account
On-Premises SQL Server: My source data will be stored in an on-premises SQL Server and this will be needed for the exercise. For more information on obtaining a Developer, Express or Trial version of SQL Server, visit: Try SQL Server on-premises or in the cloud
Azure SQL Database (Standard): I will use Azure SQL Database to store my pipeline parameter values and tables so as not to make any changes to my source on-premises objects. For more detail on creating an Azure SQL Database, visit: Quickstart: Create a single database in Azure SQL Database using the Azure portal, PowerShell, and Azure CLI
Azure Data Factory Self Hosted IR: The self-hosted IR will allow me to link my on-premises resources to Azure. For more detail on creating a Self-hosted IR, visit: Connect to On-premises Data in Azure Data Factory with the Self-hosted Integration Runtime – Part 1
Prepare and Verify SQL Server Database Objects
I’ll begin the process by navigating to SQL Server Management Studio and connecting to my on-premises SQL Server containing two OLTP SQL Databases.
For more detail related to finding sample SQL Databases, visit: SQL Server Samples on GitHub

I will also verify that there are tables in both databases:


Prepare and Verify Azure SQL Database Objects
I will create a pipeline parameter table in my Azure SQL Database to store the table names, catalog names, and process flags, which will drive the pipeline configurations at runtime.

SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[pipeline_parameter]( [Table_Name] [nvarchar](500) NULL, [TABLE_CATALOG] [nvarchar](500) NULL, [process_type] [nvarchar](500) NULL ) ON [PRIMARY] GO
Prepare Azure Data Lake Store Gen2 Container
I will also create an ADLS2 container and folder for my server.

I will also confirm that there is no existing data in my server level folder:

Create Azure Data Factory Pipeline Resources
I am now ready to begin creating my Azure Data Factory Pipeline by navigating to my Azure Data Factory resource and clicking Author and monitor:

Once the Azure Data Factory canvas loads, I will click ‘Create Pipeline’.

Create Self Hosted IR
I will create and verify that my Self Hosted Integration runtime is created and in ‘Running’ Status.
For more detail on creating a Self-Hosted IR, please see: Create and configure a self-hosted integration runtime.
A self-hosted integration runtime can run copy activities between a cloud data store and a data store in a private network.

Create Linked Services
Once my self-hosted IR is created, I will create all my required Linked services, which include SQL Server, Azure SQL Database, and Azure Data Lake Store Gen 2.

Create Datasets
My pipelines will require the following three datasets.

DS_ADLS2
I will configure my ADLS2 Dataset as a Parquet format and will also add the following parameterized file path connections to allow me to partition my data by YY-MM-DD-HH. I’ll also set the compression type to ‘snappy’ for improved performance.

@concat('lake/raw/on_prem2/',dataset().table_catalog_name)
@{item().Table_Name}/@{formatDateTime(utcnow(),'yyyy')}/@{formatDateTime(utcnow(),'MM')}/@{formatDateTime(utcnow(),'dd')}/@{item().Table_Name}@{formatDateTime(utcnow(),'HH')}
Within this dataset, I will also add the following parameters, which I will use at a later stage.

DS_SQLSERVER
Next, I will add a dataset connection to my on-premise SQL server. Note that I will also leave the table as set to ‘None’ to allow for traversing through all tables in the SQL Server.

DS_ASQLDB_PIPEINE_PARAMETER
My final dataset will be for a connection to my pipeline parameter table in an Azure SQL Database.

Create Azure Data Factory Pipelines
P_Insert_Base_Table_Info
This pipeline will query the on-premise information_Schema.tables as its source to get the Table Name and Database name and will then output the results to a basic parameters table in Azure SQL Database. The purpose of this pipeline and process will be to use this pipeline parameter table to drive the rest of our pipelines.
To create this pipeline, I will add a copy activity to the pipeline canvas and set my source as my on-premises server dataset. I will also add the following query as the source. This query will query the specified Database and list the tables that can be used in the rest of the process. For now, I will manually change the database name for every database that I would need and run the pipeline.
USE AdventureWorksLT SELECT QUOTENAME(table_Schema) + '.' + QUOTENAME(TABLE_NAME) AS Table_Name, TABLE_CATALOG FROM information_Schema.tables WHERE TABLE_TYPE = 'BASE TABLE'

Next, I will set my Sink:

Lastly, I will ensure that my source to sink mappings are accurate:

The resulting pipeline.parameter Azure SQL DB table would look like this:

P_SQL_to_ADLS
In this section, the pipeline to create the SQL Server to ADLS data orchestration will be created. I will add a Lookup and Foreach activity to the pipeline canvas.

The lookup activity simply looks up the pipeline parameter table that we populated in the prior pipeline.

Next, within settings of the For Each activity, ensure that Items is set to:
@activity('Get-Tables').output.valueAlso, sequential remains unchecked so that the tables will execute in parallel. Currently, the Foreach activity supports Batch counts of up to 50.

I have also added a copy activity within the ForEach Activity. Click Edit Activities to view the details.

My source dataset is the on-premises SQL Server.
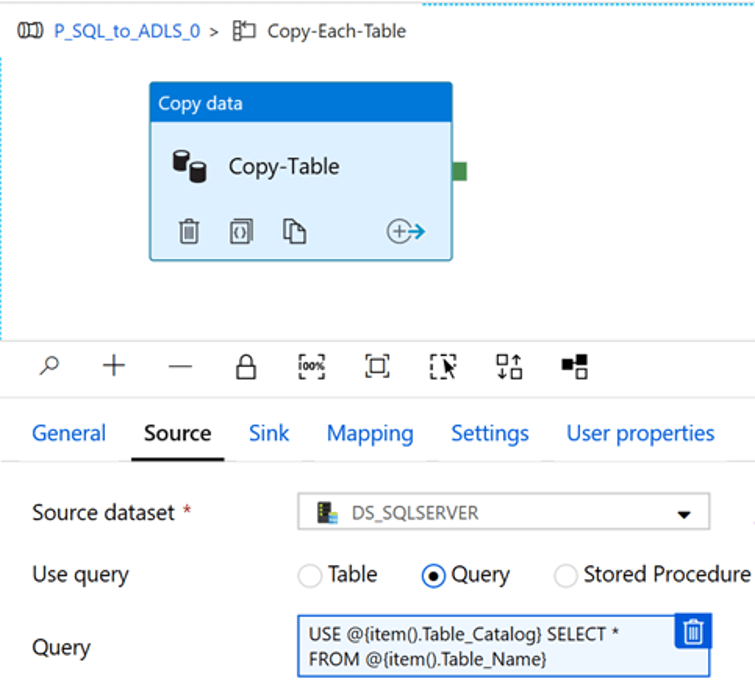
Additionally, I will use the following dynamic source query which will look up the Table Catalog and Table Name:
USE @{item().Table_Catalog} SELECT * FROM @{item().Table_Name}My sink dataset will be my specified ADLS2 account container and folder structure. I will also add table_name and Item_name to the dataset properties that we configured while creating DS_ADLS2 dataset.

It’s fair to say that this pipeline is now complete and ready to be run.
Run the Data Factory Pipeline & Verify Azure Data Lake Store Gen 2 Objects
I will now run pipeline P_SQL_to_ADLS.
After running the pipeline, I can see that there are two database-level folders for my two databases.

I can also see the appropriate table-level folders:

Additionally, when I drill into the folders, I can see that they are appropriately time-partitioned and that the table file has been created.

Next Steps
- Read more about Expressions and functions in Azure Data Factory, to understand the various methods of building pipeline parameters.
- This article covers a full load method. For ideas around incremental loads, see: Incrementally load data from multiple tables in SQL Server to an Azure SQL database and Azure Data Factory V2 – Incremental loading with configuration stored in a table – Complete solution, step by step.
- See supported data types in the article Schema mapping in copy activity for a list of data types supported by ADFv2. Note that certain columns containing datatypes that are not in the list may fail the pipeline run. Considerations to create alternative methods for these datatypes would be recommended.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019


This is a good example for automatization from on-prem to cloud migration but there is no further information how to generate table structure and it’s constraints.
Will this table migration also take care Table level constraints?
If no then how can we migrate tables as it is with all its constraints applied ?
Hi Izumi, Have you tried just @activity(‘Get-Tables’).output.value. Your syntax looks like its adding ‘length()’ which may be causing the error?
This is good article, Thank you.
I am facing error message that I cannot find any workaround.
The expression ‘length(activity(‘Get-Tables’).output.value)’ cannot be evaluated because property ‘value’ doesn’t exist, available properties are ‘firstRow, effectiveIntegrationRuntime, billingReference, durationInQueue’.
Even if I change .value to firstRow, it will keep showing another error…