Problem
In these series of posts, I am going to explore Azure Data Factory (ADF), compare its features against SQL Server Integration Services (SSIS) and show how to use it towards real-life data integration problems. In previous posts, we have explored ways to create pipelines to transfer data between on-premises machines and Azure and initiated the data transfer manually. In a production scenario, data flow jobs are usually initiated automatically, based on a certain schedule or in response to certain events. In this and the next few posts, we will be exploring the ways to automate pipeline executions.
Solution
Azure Data Factory Pipeline Parameters and Concurrency
Before we move further, I need to explain a couple pipeline concepts:
- Pipeline concurrency – Pipeline concurrency is a setting which determines the number of instances of the same pipeline which are allowed to run in parallel. Obviously, the higher the value of the concurrency setting, the faster the upload could finish. However, this setting needs to be chosen wisely, as it may affect performance of your source, destination servers and could easily overload your network.
- Pipeline parameters – Parameters allow pipelines to receive settings dynamically, using system variables or built-in ADF functions. Typically, parameters are being used to pass time slice settings from triggers to pipelines. In this exercise, we will add string parameters and pass the trigger’s time range settings to this parameter, which will allow us to understand which time slices are being initiated from the trigger.
Here is how to add parameter to the pipeline we created in earlier posts:
- Open the ‘Open & Author’ window for ADF, select ‘SQL_ASQL_PL’ pipeline under ‘Pipelines’ tab, switch to ‘Parameters’ tab, use ‘+New’ button to add a new parameter.
- Assign the name (I’ve named it as ‘StartDt’) to the parameter and select appropriate data type. Parameters can be string, integer, float and other types, please see the below screenshot for the available options:

Azure Data Factory Triggers
ADF v2 has introduced a concept of triggers as a way to automate pipeline executions. Triggers represent a unit of processing that determines when a pipeline execution needs to be initiated. The same pipeline could be kicked-off more than once and each execution of it would have its own run ID. Pipelines and triggers have a many-to-many relationship. Multiple triggers can kick-off a single pipeline, or a single trigger can kick off multiple pipelines. Here is the list of different trigger types available in ADF:
- Tumbling window triggers – Tumbling window trigger is a type of trigger that fires at periodic time intervals from a specified start time. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. It is important to remember that tumbling window triggers can be configured to initiate past and future dated loads. A tumbling window trigger has a one-to-one relationship with a pipeline and can only reference a single pipeline.
- Schedule triggers – A schedule trigger runs pipelines on a wall-clock schedule. This trigger supports periodic and advanced calendar options. A schedule trigger can only trigger future dated loads. Schedule pipelines and triggers have a many-to-many relationship.
- Event-based trigger – An event-based trigger runs pipelines in response to an event, such as the arrival of a file, or the deletion of a file, in Azure Blob Storage.
We will be focusing on tumbling window triggers in this article.
Creating Tumbling Window Trigger in Azure Data Factory
As mentioned in the previous section, a tumbling window trigger allows loading data for past and future periods. As the name suggests, the time slices handled by a tumbling window trigger must be, fixed, non-overlapping, and contiguous, see the below figure as an example for a trigger with hourly windows:

In this exercise, I’ll create a trigger, which will start the pipeline ‘SQL_ASQL_PL’ we created in an earlier post. The trigger will be initiated seven times on an hourly basis, six of them will be in past and one will be in the future. In a typical production scenario, pipeline windows would bring different data slices, using pipeline parameters, however to keep things simple for now, our pipeline windows will transfer the same data.
There are only two frequency units (minutes and hours) available for tumbling window trigger at the time of writing this article and although you can set any required frequency using multiples of these units. I think it would be great if Microsoft adds more units, like days, weeks, etc., to make this trigger type more flexible.
Here are steps to create tumbling window trigger:
- Open the ‘Open & Author’ window for the ADF, select ‘SQL_ASQL_PL’ pipeline under ‘Pipelines’ tab and select ‘New/Edit’ command under ‘Trigger’ menu:
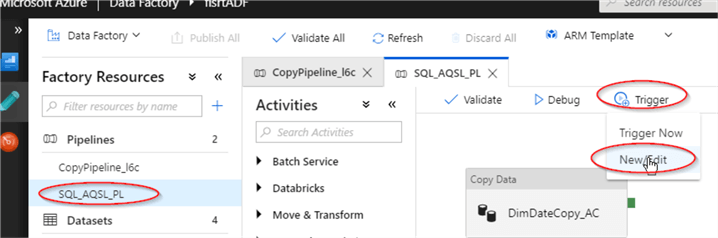
- Click ‘+ New’ button on ‘Add Triggers’ dialog window:

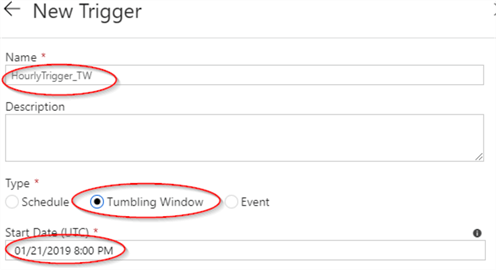
- Assign the name to the trigger, select ‘Tumbling window’ and select date/time, matching to 6 hours prior from the current time (time is displayed in UTC format):
- Next, select hourly frequency with every hour under ‘Recurrence’, set the beginning of next hour as trigger end time. Now, because our pipeline is copying the same data on each iteration, we will set concurrency setting to one, to avoid primary key errors on the destination table. So, let’s put ‘Max Concurrency’ setting to one and confirm settings to switch to the next page:

- The last page of the ‘Add Triggers’ wizard allows passing values to pipeline parameters. As I mentioned in earlier in this article, we can use system variables to set pipeline configuration dynamically and we will discuss available system variables in one of the future articles. For now, let’s assign an expression @trigger().outputs.windowStartTime, indicating the trigger’s start time to pipeline parameter ‘StrtDt’ we created earlier and confirm, to exit the wizard:

- Finally, click ‘Publish all’ to publish changes:

Once all the changes have been published, we will see a new trigger icon appearing in the top right corner:

To examine the list of all created triggers, let’s open the ‘Triggers’ tab, located at the bottom left side of the ‘Factory Resources’ panel:

The triggers list includes essential information, such as the trigger’s name, type, number of pipelines assigned to it:

This screen also allows deactivating, activating, editing, deleting and code review actions:

Examining a trigger’s code could be useful in troubleshooting of certain configuration issues. It contains all of the configuration settings, including names of pipelines, assigned to it. Here is the JSON script created behind the scenes:
{ "name": "HourlyTrigger_TW",
"properties": {
"runtimeState": "Started",
"pipeline": {
"pipelineReference": {
"referenceName": "SQL_AQSL_PL",
"type": "PipelineReference"
},
"parameters": {
"StartDt": "@trigger().outputs.windowStartTime"
}
},
"type": "TumblingWindowTrigger",
"typeProperties": {
"frequency": "Hour",
"interval": 1,
"startTime": "2019-01-21T20:00:00.000Z",
"endTime": "2019-01-22T02:00:00.000Z",
"delay": "00:00:00",
"maxConcurrency": 1,
"retryPolicy": {
"intervalInSeconds": 30
}
}
}
}
}Monitoring Execution Results for the Tumbling Window Trigger in Azure Data Factory
Now that we created the tumbling window trigger, let’s switch to the ADF monitoring page to see execution results. Contrary to what we expected, we have had only five successful executions related to past time slices, see the below screenshot:
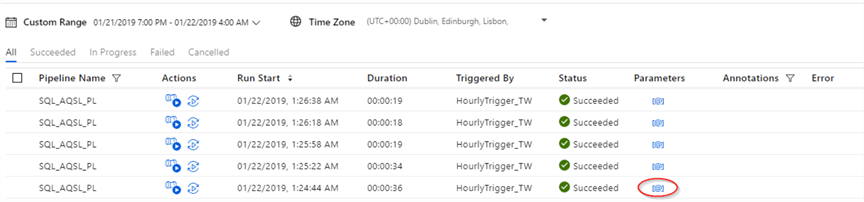
Since we have passed the trigger’s start time to the pipeline as a parameter, we can examine the value, assigned to each execution, using the ‘Parameters’ button:

Although the configuration has been finished at 1:24 am, ADF has initiated the pipeline for all time slices, except last window (1 am window). Let’s wait until the beginning of the next hour and refresh the execution results, using the ‘Refresh’ button:

As you can see from the ‘Parameters’ screen for the last execution, the time slice for 1 AM- 2 AM window has been executed at the end of the window (1:59:59), which is the default behavior for ADF triggers:
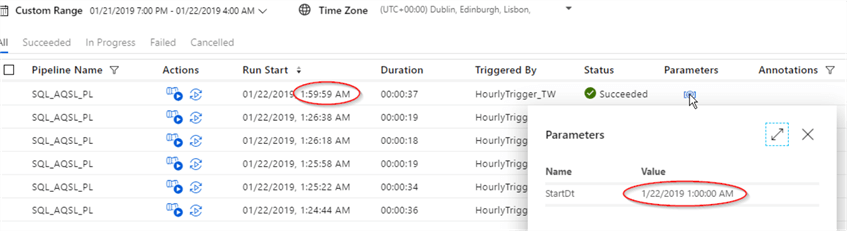
Since our trigger was configured to end at 2 AM, there will be no further executions, so if we want the last execution to be for 2AM-3AM window, we will need to shift the trigger’s end time to 3 AM or later.
The trigger executions screen allows us to re-run any window again, by using the ‘Rerun’ button:

We can also examine details of each execution from this screen, by clicking on the ‘View Activity Runs’ button for each execution:

Inside the ‘Activity Runs’ window, let’s click the ‘Output’ button to examine the size of the data transferred (in KB), number of rows copied, copy duration (in seconds), throughput concurrency and some more details:
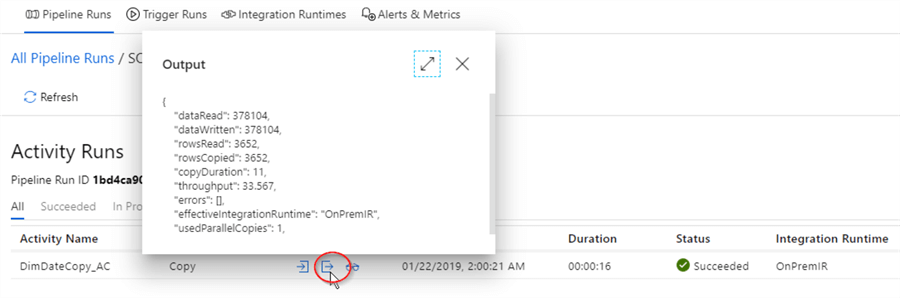
We can get another perspective into execution details by clicking the ‘Details’ button, which will open the below screen with similar information, organized in a slightly different way:


This screen is very useful when monitoring a long running pipeline, as it shows read/write statistics in real time.
Conclusion
Unlike SSIS, ADF has built-in features to schedule data flow jobs, which comes in handy, considering there are no scheduling tools, like SQL Server Agent in the cloud. We will explore another type of time-based trigger in the next post.
Next Steps
- Read these other Azure Data Factory tips
- Read: Pipeline execution and triggers in Azure Data Factory

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021

