Problem
Azure Synapse Analytics unifies data analysis, data integration and orchestration, visualization, and predictive analytics user experiences in a single platform (see this earlier tip for more details). Synapse has inherited most of its data integration and orchestration capabilities from Azure Data Factory (ADF) and we will cover some of the similarities and differences.
Solution
We are first going to look at the similarities and differences between Synapse Analytics and Azure Data Factory then we will build a sample Synapse pipeline to see how this works.
Similarities between Azure Synapse Analytics and Azure Data Factory
Azure Synapse Analytics, like ADF, offers codeless data integration capabilities. You can easily build a data integration pipeline, using a graphical user interface, without writing a single line of code! Additionally, Synapse allows building pipelines involving scripts and complex expressions to address advanced ETL scenarios.
Synapse integration pipelines are based on the same concepts as ADF linked services, datasets, activities, and triggers. Most of the activities from ADF can be found in Synapse as well.
Differences between Azure Synapse Analytics and Azure Data Factory
Despite many common features, Synapse and ADF have multiple differences. I would categorize these differences as:
- Brand new features appearing in Synapse
- ADF features no longer supported in Synapse
- Features in both ADF and Synapse, but behave slightly different
Synapse has Spark notebooks, Spark job definitions and SQL pool stored procedure activities which are not available in ADF. In a previous tip (see Azure Synapse Analytics Data Integration and Orchestration), I illustrated the usage of the Spark notebook and SQL pool stored procedure activities. One thing to note about these activities is that they do not require the creation of linked services. For example, the screenshot below shows the SQL pool stored procedure activity which only requires a SQL pool setting:

As far as the no longer supported features, Synapse does not have the SSIS package execution activity. Also, the CI/CD capabilities with GitHub integration are not part of the Azure Synapse user interface. Another feature missing from Synapse is pipeline creation from the template. ADF has several templates which allow you to create pipelines based on some standard ETL scenarios. Synapse does not have this. Synapse also does not support Snowflake's source/destinations.
Finally, a few observations regarding the features behaving differently. Like ADF, Synapse allows creating linked services that serve as connection strings for different activities. However, there is a different category of link objects in Synapse that can serve only as bridges for ad-hoc data exploration. The Azure Cosmos DB, SQL pool, or storage links created from the Synapse Studio’s Data tab, can be examples of this (see this post, to learn more).
In the next few sections, I have illustrated a pipeline creation process in the Synapse Studio and explained how to create different pipeline components.
Synapse Pipeline Example
I will build a simple Synapse pipeline to copy the data from the Azure SQL DB table into the blob storage and explain how to create its dependencies such as linked services and datasets.
Let’s start by creating Azure SQL DB based on the sample AdventureWorksLT database (see this article to learn more).
Next, open the Synapse Studio, navigate to your default storage account and container, and create a folder named SalesOrderHeader within the container. We will use this folder to export the results:

Our pipeline will have a single copy activity to extract the data from the source tables SalesOrderHeader table.
The Synapse data integration and orchestration concepts are the same as those of (ADF). If you’re not familiar with ADF, I encourage you to read this tip.
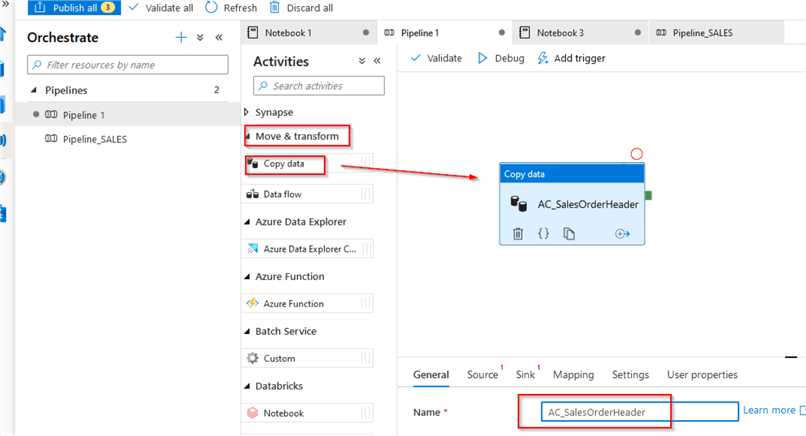
Let us open the Synapse Studio, navigate to the Orchestrate tab, and create a pipeline:

Next, expand the Move & Transform section and drag the Copy data activity into the design surface and name it (I named it as AC_SalesOrderHeader):
Our next step will be to create a source linked service and dataset objects. Navigate to the Source tab and select the New button to create a dataset:

Open the Azure tab and scroll-down to select the Azure SQL Database option and confirm to continue:

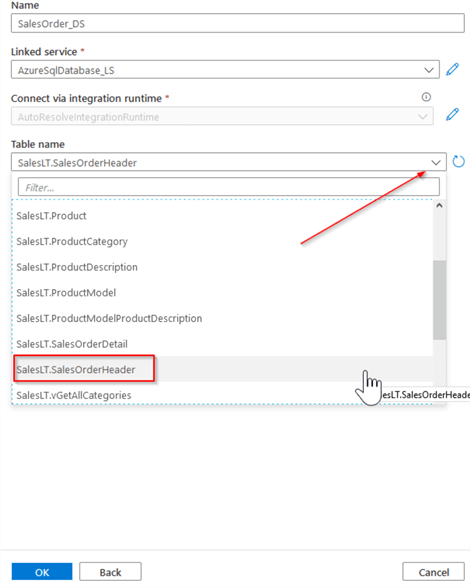
Name the dataset as SalesOrder_DS, and click the New command from the Linked service drop-down list:

Name the linked service as AzureSQLDatabase_LS, select the subscription name, SQL server and database name, and specify the SQL server as an authentication method. Enter the credentials for the Azure SQL DB and click the Test connection button to ensure that the connection works as follows:

Confirm your selections to move to the table selection screen and select the SalesOrderHeader table:
Now that we have the completed data source settings for the activity, we will configure its destination (sink) dataset. Navigate to the Sink tab, click the New button, and select the Azure Blob Storage service:

Confirm your selection, move to the Select format screen, and select the Parquet option:

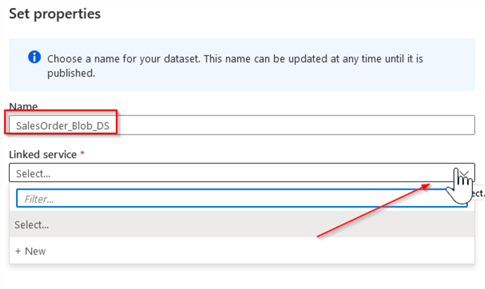
Next, name your dataset as SalesOrder_Blob_DS, and click the New command to create the linked service:
Next, name the linked service as AzureBlobStorage_LS, select the required subscription and storage account and confirm:

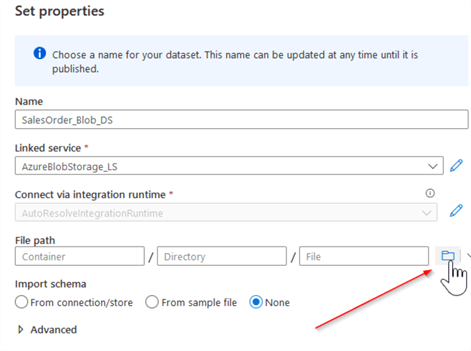
In the storage properties page, ensure that a newly created linked service for the storage is selected and click the path selection button to select the required storage folder:
Navigate to the SalesOrderHeader folder that we created earlier:
Select the None radio button under the Import schema section and confirm to complete the sink dataset settings:

Now that the pipeline is ready, we can test it using the Debug button and watch the results in the Output window, as follows:

Finally, publish the pipeline to preserve the changes.
Exploring the Synapse pipeline objects
In the previous section, we created all the required objects directly from the pipeline design page. You can also create these objects independently and use them while building the pipeline as explained below.
You can find the list of all linked services we have created so far by navigating to the Manage tab and opening the Linked services pane:

You can also create a linked service from this page using the New button.
This page also contains a list of the Integration runtimes and triggers:

Contrary to what you might expect, the datasets are on a different page. You can find a list of datasets under the Integration datasets section within the Data pane.

Next Steps
- Read: Azure Synapse Analytics Overview
- Read: Data integration in Azure Synapse Analytics versus Azure Data Factory
- Read: Pipelines and activities in Azure Data Factory
- Read: Orchestrate with pipelines

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021