Problem
Azure Synapse Analytics comes with several exciting data exploration features. In Explore your Data Lake data easily with Azure Synapse Analytics, we investigated Azure Synapse Analytics’ data exploration features, related to storage. In this tip we are going to learn how to explore data in Synapse databases and how to transfer the data between databases and storage, using Azure Synapse Analytics.
Solution
Let’s take a look at some of database related features of Synapse Analytics.
Create a SQL pool
A Synapse’s pool is a multi-node cluster, hosting one or more databases. So, a SQL pool can host SQL (formerly SQL DW), while a Spark pool can host Spark databases. Both SQL and Spark pools could be created from the Azure portal or Synapse Studio.
Here is what is required to create a SQL pool in Synapse Studio:
Navigate to Synapse Studio and open the Manage command from the left-hand tool bar. Select SQL pools and click the New button. Next, provide the name and performance level measured in DW’s and confirm, as follows:

Figure 1
Once the SQL pool is provisioned, we should be able to see it in the list of available pools, as follows:
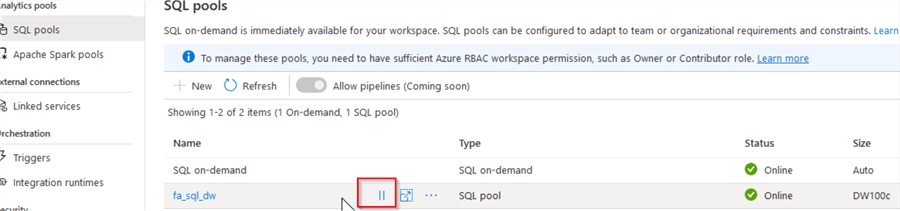
Figure 2
Note that a SQL pool can be paused and resumed any time, using the button highlighted in this screenshot, so make sure to pause it when not needed, to avoid unnecessary charges.
Let’s navigate to the Data tab and see the newly created database among the workspace databases:
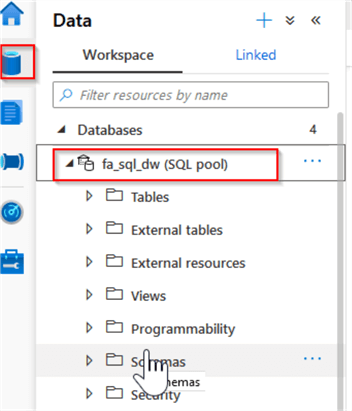
Figure 3
There are few ways to execute SQL queries on this database. You can connect using SQL Server Management Studio (see here for more details), or use Synapse Studio for this purpose. I will use Synapse Studio for the purpose of this exercise.
To create a new query window, open the Develop tab, click the + button at the top of the toolbar and select the SQL script command:
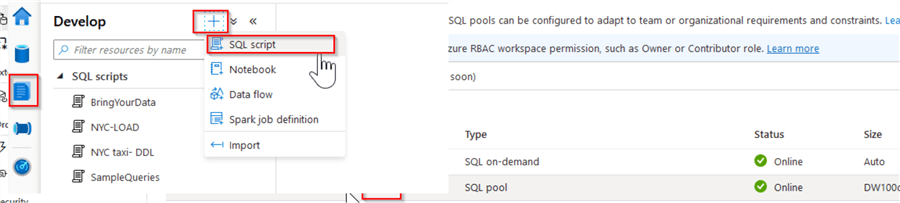
Figure 4
You can also upload SQL scripts from your local machine, using the Import button.
Let’s upload some data into this database, using sample scripts from this Microsoft source. I have included two scripts from that source for your convenience.
Here is the description of these scripts:
- Contoso-DDL.sql – This script will create external tables, pointing to the blob storage locations with Microsoft’s open-source data. The Synapse external tables use a PolyBase functionality to read the files from storage accounts (see this article for more information about the PolyBase technology).
- Contoso-LOAD.sql – This script will create the tables for fictitious Contoso data warehouse and load data into them, using external tables as a source.
Please unpack the included scripts and use the Import button to upload both scripts into your workspace. Once the scripts are uploaded, ensure that an execution context is set to the SQL pool, and execute the Contoso-DDL script, followed by Contoso-LOAD script, as follows:
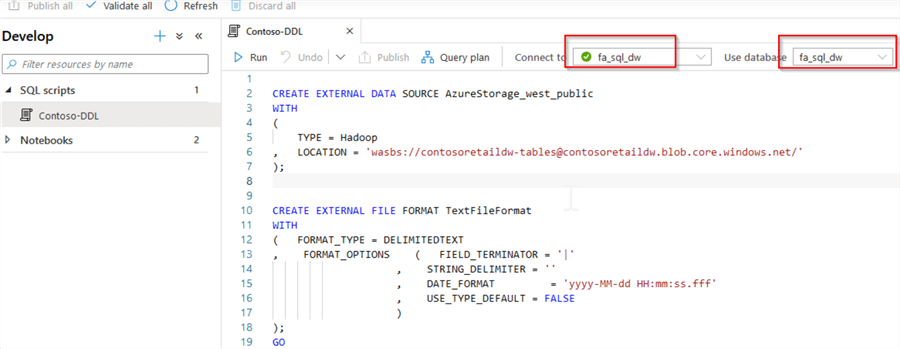
Figure 5
Next, let us explore the tables we just created, by navigating to the Data tab and expanding the table list in the object explorer:
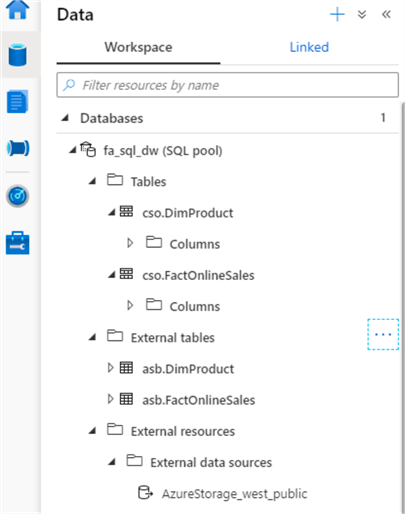
Figure 6
Synapse Studio’s object explorer reminds me of SQL Server Management Studio’s object explorer, although it only displays table and column objects (no indexes or statistics, for example).
When you hover the cursor over the table objects in Synapse Studio, the Actions button appears, allowing you to choose one of the scripting options, listed below:
- New SQL script
- New notebook
- Data flow
- Dataset
Here’s screenshot with the Actions button:
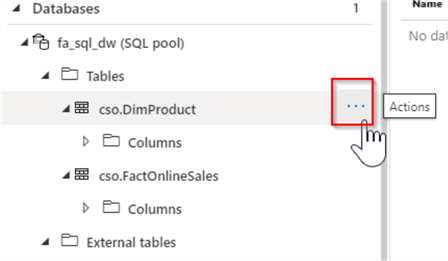
Figure 7
Let’s examine the content of the FactOnlineSales table, by selecting Actions/New SQL script/Select TOP 100 rows commands:
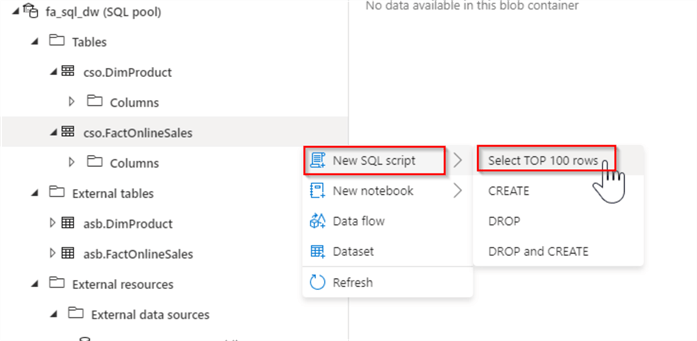
Figure 8
This will add a SQL script with the Select statement.
Execute it using the Run button and once the query runs, you can switch between tabular and visualization modes, using Table/Chart buttons at the top of the results window. You can also export the query results to CSV, JSON or XML file formats, as follows:

Figure 9
Exploring the data integration between the SQL databases and the storage
There are few methods to read data from the storage files into Synapse databases. Here is the description of them:
- PolyBase Technology – Azure Synapse Analytics inherited PolyBase from SQL DW. PolyBase requires creation of several metadata objects in the database, like external resources, file format specifications and external tables. What is great about Synapse implementation of PolyBase is that it frees users from creation and maintaining of credentials to access the storage accounts.
- Copy Statement – The Copy statement has been introduced with Azure Synapse Analytics and is still considered a preview feature (see COPY (Transact-SQL) for more info). Like PolyBase, this command allows reading storage data without any credentials. However, unlike PolyBase it does not require creation of extra database objects (like file formats, external tables, etc.). The Copy statement is also more flexible than PolyBase, when it comes to different file formats, error handling, etc. You can easily generate the Copy statement for the storage files, by following the below step:
- Select the files in your file object explorer, right click and select New SQL script/Bulk load:
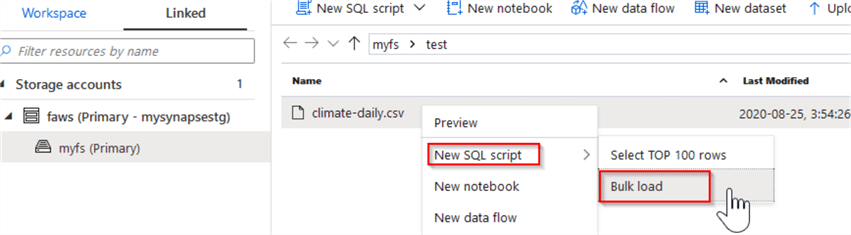
Figure 10
- BCP and SqlBulkCopy are older data importing methods, available with the Synapse Analytics, although Microsoft recommends using the Copy statement or PolyBase for uploading a high-throughput data.
Azure Synapse Analytics’ data integration with Azure SQL databases
In this tip, I demonstrated how we can create SQL pools, which represent multi-node SQL DW databases. As to the Azure SQL databases, they cannot be added to the workspace the same way as SQL DW databases at this point, although we can create data integration pipelines pointing to them. Since, Microsoft is making Azure Synapse Analytics a centralized data exploration and transformation platform, I think Azure SQL databases will be added to the Synapse Analytics workspace in the near future.
Next Steps
- Read: Quickstart: Create a Synapse SQL pool (preview) using the Azure portal
- Read: Quickstart: Create a Synapse SQL pool using Synapse Studio
- Read: Bulk loading with Synapse SQL

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021