Problem
Spark and SQL on demand (a.k.a. SQL Serverless) within the Azure Synapse Analytics Workspace ecosystem have numerous capabilities for gaining insights into your data quickly at low cost since there is no infrastructure or clusters to set up and maintain. Data Scientists and Engineers can easily create External (unmanaged) Spark tables for Data Analysts and Business Users to Query parquet files in Azure Data Lake Storage Gen2. What are some of the capabilities of Spark External Tables within Azure Synapse Analytics?
Solution
In my previous article, Getting Started with Azure Synapse Analytics Workspace Samples, I briefly covered how to get started with Azure Synapse Analytics Workspace samples such as exploring data stored in ADLS2 with Spark and SQL On-demand along with creating basic external tables on ADLS2 parquet files. In this article, we will explore some of the additional capabilities of Synapse Spark and SQL Serverless External Tables.
Pre-requisites
Prior to exploring the capabilities of External Spark Tables, the following pre-requisites will need to be in place:
- Create a Synapse Analytics Workspace: The Synapse Workspace is where we will be exploring the capabilities of External tables, therefore a Synapse Workspace along with Synapse Studio will be needed. For more detail, see: Quickstart: Create a Synapse workspace.
- Create and Azure Data Lake Storage Gen2 Account: The ADLS2 Account will house the parquet files that will be accessed by the Synapse Analytics Workspace.
- Add AdventureworksLT2019 Database Parquet files to ADLS2: The AdventureWorksLT2019 parquet files will be used by the Synapse Workspace to create External Spark Tables. For more information on how to create parquet files from a SQL Database using Azure Data Factory V2, please read my previous article: Azure Data Factory Pipeline to fully Load all SQL Server Objects to ADLS Gen2.
- Create a Synapse Spark Pool: The Synapse Spark pool will be used as the compute engine to execute the create external Spark table statements. For more detail on creating a Synapse Spark pool, please read: Quickstart: Create a new Apache Spark pool using the Azure portal.
- Create a Synapse Spark Database: The Synapse Spark Database will house the External (Un-managed) Synapse Spark Tables that are created. The simplest way to create the Database would be to run the following command in the Synapse Analytics Notebook using the %%sql command. For additional detail, read: Analyze with Apache Spark.
%%sql CREATE DATABASE AdventureWorksLT2019
Types of Apache Spark Tables
There are a few different types of Apache Spark tables that can be created. Let’s take a brief look at these tables.
1) Global Managed Tables: A Spark SQL data and meta-data managed table that is available across all clusters. Both data and meta-data is dropped when the table is dropped.
//Using DataFrameWriter API
dataframe.write.saveAsTable("t")
//Using Spark SQL API
spark.sql(CREATE TABLE t (i int) USING PARQUET);
2) Global Unmanaged/External Tables: A Spark SQL meta-data managed table that is available across all clusters. The data location is controlled when the location is specified in the path. Only the meta-data is dropped when the table is dropped, and the data files remain in-tact. Note that the EXTERNAL Keyword does not need to be specified in the spark.sql CREATE TABLE statement as long as the location is specified in the statement.
//Using DataFrameWriter API
dataframe.write.option('path', "<storage-location>").saveAsTable("t")
//Using Spark SQL API
spark.sql(CREATE TABLE t6 (i int) USING PARQUET OPTIONS('path'='/tmp/tables/t');
3) Global Temporary Views: The View can be shared across different spark sessions or Databricks notebooks.
dataframe.createOrReplaceGlobalTempView("global_view")
4) Permanent Temporary Views: The data frame will be persisted as a permanent view. The view can be created on a Global Managed or Un-Managed (External) table and not on Temp Views or Data frames.
//Only available with Spark SQL API and not DataframeWriterAPI
spark.sql("CREATE VIEW permanent_view AS SELECT * FROM t")
5) Local/Temp Tables (Temp Views): Local Tables / Temp Views are not registered in the meta-store and only Spark session scoped, therefore they will not be accessible from other clusters or other Databricks notebooks.
dataframe.createOrReplaceTempView()
Dynamically Create Spark External Tables with Synapse Pipelines
Since we are exploring the capabilities of External Spark Tables within Azure Synapse Analytics, let’s explore the Synapse pipeline orchestration process to determine if we can create a Synapse Pipeline that will iterate through a pre-defined list of tables and create EXTERNAL tables in Synapse Spark using Synapse Notebooks within a ForEach Loop that accepts the table names as parameters.
To get started, let’s create a new notebook in Synapse Analytics Workspace.

The notebook can contain a parameter cell that we will use in the pipeline.

To specify that this is a parameter cell, we can ‘Toggle parameter cell’. Note that I have noticed that not toggling the parameter cell also works if the parameter name matches the defined parameter in the Synapse Pipeline and that it is parameterized in the Synapse Notebook code.

The notebook will contain the following Code:
from pyspark.sql.functions import *
for tables in {src_name}:
loc = f"/raw/AdventureWorksLT2019/SalesLT/{tables}"
spark.sql(f"CREATETABLEIFNOTEXISTSAdventureWorksLT2019.{tables}USINGPARQUETLOCATION'{loc}'")
New Synapse Pipeline
Next, let’s create a new Synapse Pipeline within the Synapse Analytics Workspace.

Within the pipeline, I’ve added a look up to get a list of tables from a pipeline_parameter which contain a list of my AdventureWorksLT2019 Tables.

Next, I will pass the table names to a ForEach Loop. I’ve left sequential unchecked to test parallel processing.
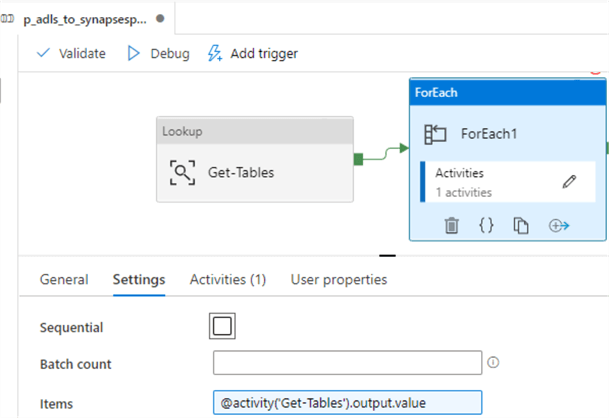
Within the ForEach Loop, I’ve added a Synapse Notebook. Note that this Synapse option is currently not available in Azure Data Factory V2 and exclusively available in Synapse Pipelines.

We will also need to configure the base parameters of the notebook as follows:

Troubleshooting the Synapse Pipeline
After configuring, publishing, and running the Synapse Pipeline, I did get errors related to vcores, limits and lack of synchronization between the available vcores defined in the workspace and those requested by the Spark job. I considered the fact that we are running the jobs in parallel through the ForEach loop and reduced to a sequential processing mode, however continued to see the issues. This is probably related to the fact that Azure Synapse Analytics Workspace is still in preview and far from being fully baked. It would be nice to see these features working as expected in the GA release.
Despite the failed job, we can see that the 10 AdventureWorksLT2019 tables did run through the for each loop. I look forward to the bugs being resolved in this feature as this has the potential of being great capability to be able to dynamically create hundreds of EXTERNAL Spark tables in parallel.

Create Synapse Spark External Tables with Synapse Notebook
Despite the failed attempt from above section, I was determined to continue exploring the capabilities of Synapse Spark External Tables and decided to re-create the ForEach Loop scenario with an array in the Synapse Notebook instead.
The array will represent my list of parameterized tables, which contains the 10 AdventureWorksLT2019 tables:

Like the previous section, let’s run the code again. This time, I removed the parameters for src_name:
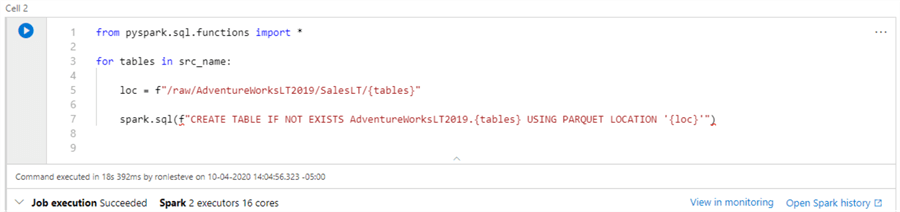
Here is the Synapse Notebook Code:
from pyspark.sql.functions import *
for tables in src_name:
loc = f"/raw/AdventureWorksLT2019/SalesLT/{tables}"
spark.sql(f"CREATETABLEIFNOTEXISTSAdventureWorksLT2019.{tables}USINGPARQUETLOCATION'{loc}'")
As expected, the code looped through the list of tables and created the external tables within the Synapse Spark database.

Query Spark External Tables with SSMS and Power BI
Now that we have our Synapse Spark database along with External Synapse Spark tables created, let’s try to query the tables from more familiar querying tools such as SSMS and Power BI.
Synapse SQL on demand (SQL Serverless) can automatically synchronize metadata from Apache Spark for Azure Synapse pools. A SQL on-demand database will be created for each database existing in Spark pools. For more information on this, read: Synchronize Apache Spark for Azure Synapse external table definitions in SQL on-demand (preview).
Let’s head over to Azure portal and grab the SQL on-demand endpoint connection.

Connect with SSMS
Next, let’s enter this connection into SSMS along with the Login and Password credentials.

Once connected, we can see that the SQL on-demand has synced the Spark Database and External Tables and they are now visible for querying in SSMS.

Additionally, when we expand the columns, we can see that the meta data (column names and datatypes) are also visible is SSMS.

Power BI Connection
Let’s try one final connection within Power BI to ensure we can also connect the External Spark tables to Power BI.

Sure enough, the same External Synapse Spark Tables are also visible within Power BI. Note that the availability of these tables in SSMS and Power BI does not mean that they are production ready and would replace a relational data warehouse. This connectivity of Synapse Spark External tables indicates the capabilities of getting quicker insights into staged data, very similar to a Hive meta-store in a relational database.

Next Steps
- For more on learning how to create Spark Tables, read: Create Table.
- For more detail on reading and writing Parquet files using Spark, see: Read & write parquet files using Apache Spark in Azure Synapse Analytics.
- Read more about Azure Synapse Analytics shared metadata tables.
- Read more about Using external tables with Synapse SQL.
- Read more about Accessing external storage in Synapse SQL (on-demand).
- Read more about Controlling storage account access for SQL on-demand (preview).
- Read more about Creating and use external tables in SQL on-demand (preview) using Azure Synapse Analytics.
- Read more about SQL on-demand in Azure Synapse Analytics.

Ron C. L’Esteve is a Data and AI Leader and professional Author residing in Chicago, IL, USA. He is well-known for his impactful books and article publications on Azure Data & AI Architecture, Engineering, and Leadership. Ron holds a Master of Business Administration (M.B.A.) and Master of Science in Corporate Finance (M.S.F.) from Loyola University Chicago. Ron possesses deep technical skills and experience in designing, implementing, leading, and delivering modern Azure Data & AI projects for numerous clients around the world. He is a Motorola Certified Six Sigma Green Belt, a Microsoft Global Challenger, and also holds numerous additional Microsoft, Snowflake, and Databricks professional certifications in Big Data Engineering, Artificial Intelligence, Apache Spark and Data Platform Architecture.
- MSSQLTips Awards: Champion (100+ tips) – 2023 | Author of the Year – 2020-2021 | Rookie of the Year – 2019
Dear Ron, In a manner similar to constructing one from parquet, I constructed an external table from a Delta file. When I try to query it from SSMS, it shows me the DB but not the table, do you have any idea why this is happening? I can see the table inside Synapse Studio and I can also query it.
Could you use the same method to create external sql tables?