Problem
Azure Synapse Analytics unifies data exploration, visualization, and integration experiences for the users. In previous tips, I have demonstrated Synapse’s data exploration features that simplify integration between different components of modern data warehouse.
In this tip, we are going to build a sample data pipeline and explore Synapse’s data integration and orchestration features.
Solution
Overview of the data integration features in Azure Synapse Analytics
Azure Synapse Analytics has inherited most of the Azure Data Factory’s (ADF) data integration components. Additionally, Synapse comes with new integration components like:
- Spark notebooks – This component allows the use of notebooks with Python, Scala, and .NET code as part of the data integration pipelines. This component resembles the Databrick Notebook activity, previously included in Azure Data Factory.
- Spark job definitions – This is like the previous component, except it requires script files located in the storage account. This component resembles the Databrick Python activity, previously included in ADF.
With the addition of these two components, Microsoft replaces the need of using Databricks for engineering tasks, although the legacy Databricks components from ADF are still available in Synapse.
If you are not familiar with ADF, I would recommend reading my tips dedicated to ADF. Because Synapse and ADF have a lot in common, ADF familiarity will allow you to better understand the material provided here. In addition, you will benefit from reading previous Synapse tips which explain the common Synapse Studio screens and commands.
Data integration use-case scenario
In this demo, I will build a data pipeline to read a few JSON files from Blob Storage, do some basic transformations, and write into the SQL pool. Here are more specifics:
- I’ve used the data from the Adventureworks database (a sample database from Microsoft). I took the sales order related fact tables and product dimension table, converted them into JSON format and included them there. Please download, unzip this file, create a folder named RAW within your Synapse workspace’s default storage container, and upload the files there. Then, create another folder named DWH within the same container to store the output results from this notebook.
- The pipeline will initiate a PySpark notebook to read the JSON files, convert them to the data frames, join the dimensions with the fact tables to build a denormalized fact table, and write the results into the temporary location within the blob storage. Note that the notebook will have a few parameters to allow reading the source data incrementally.
- The pipeline will read the files produced by the notebook and merge this data with the destination fact table in the SQL pool.
If you do not have SQL and Spark pools attached to your Synapse workspace, please provision and start them (see my previous Synapse tips on the details), as we will need to run a number of SQL and Spark scripts.
Create a data transformation notebook
Let’s open Synapse Studio, navigate to the Develop tab and create a notebook as seen in the image below:

Name the notebook as DWH_ETL and select PySpark as the language.
Add the following commands to initialize the notebook parameters:
pOrderStartDate='2011-06-01' pOrderEndDate='2011-07-01'
To convert this to a parameter cell, open the cell menu using button at the right of the cell and select the Toggle parameter cell option:

Note that the cell’s type has changed to indicate this is a Parameters type cell:

Next, add a cell with the following code to import the required library:
from pyspark.sql.functions import *
Add another cell with the following commands to read JSON files as the data frames:
rootPath='abfss://myfs@mysynapsestg.dfs.core.windows.net/RAW/'
salesOrderDetailDf = spark.read.format('json').option('multiline',True) .load(rootPath+'SalesOrderDetail.json')
salesOrderHeaderDf = spark.read.format('json').option('multiline',True) .load(rootPath+'SalesOrderHeader.json', format='json')
productDf = spark.read.format('json').option('multiline',True) .load(rootPath+'Product.json')
Note that the root folder is in the 'abfss://YourContainer@YourAccount.dfs.core.windows.net/RAW/' format. This is where you will need to replace your default storage account and container names.
Next, add the cell with the following code to join the fact data frames to the dimension data frame and display the sample result:
dfSales=(salesOrderDetailDf
.join(salesOrderHeaderDf,'SalesOrderID')
.join(productDf,'ProductID').selectExpr('SalesOrderID','SalesOrderDetailID','SalesOrderNumber'
,'CAST(OrderDate as DATE) AS OrderDate'
,'CAST(ShipDate as DATE) AS ShipDate','TotalDue','ProductID'
,'Name as ProductName','UnitPrice'
,'UnitPriceDiscount','OrderQty','LineTotal')
.filter("OrderDate between '{0}' and '{1}'".format(pOrderStartDate,pOrderEndDate)))
display(dfSales)
Note that the code filters the source data based on the notebook date parameters we created earlier:
Here is the sample output:

Next, add the cell with the following code to write the data frame output in parquet format to the DWH folder:
dfSales.write.format('parquet').mode('overwrite').save('/DWH/FactSales')
Finally, publish the notebook to preserve the changes.
Creating DWH structures
Now that we have processed data in the storage account, we can create the SQL database schema objects.
We will use the PolyBase technology to read the data from the blob storage. PolyBase, requires creating of external table-related schema objects.
First, let us run the below script to create the format and data source objects. Make sure to replace the Location parameter with the correct value from your environment:
CREATE EXTERNAL FILE FORMAT parquetFormat WITH (FORMAT_TYPE = PARQUET); CREATE EXTERNAL DATA SOURCE sales_DS WITH ( LOCATION = 'abfss://myfs@mysynapsestg.dfs.core.windows.net', TYPE=HADOOP );
Next, create an external table pointing to the DWH folder in the storage account, using the following code:
CREATE EXTERNAL TABLE [dbo].[Sales_EXT]
(
SalesOrderID BIGINT,
SalesOrderDetailID BIGINT,
SalesOrderNumber VARCHAR(100),
OrderDate DATE,
ShipDate DATE,
TotalDue FLOAT,
ProductID BIGINT,
ProductName VARCHAR(200),
UnitPrice FLOAT,
UnitPriceDiscount FLOAT,
OrderQty BIGINT ,
LineTotal FLOAT
)
WITH
(
LOCATION = '/DWH/FactSales',
DATA_SOURCE = sales_DS,
FILE_FORMAT = ParquetFormat
);
Now, let us create a destination table using the following code:
CREATE TABLE [dbo].[FactSales] ( SalesOrderID BIGINT, SalesOrderDetailID BIGINT, SalesOrderNumber VARCHAR(100), OrderDate DATE, ShipDate DATE, TotalDue FLOAT, ProductID BIGINT, ProductName VARCHAR(200), UnitPrice FLOAT, UnitPriceDiscount FLOAT, OrderQty BIGINT, LineTotal FLOAT );
Finally, create the following stored procedure. This will help us read the data from an external table and merge it into the destination table:
CREATE PROC USP_MERGE_SALES
AS
BEGIN
UPDATE FactSales
SET
OrderDate = E.OrderDate ,
ShipDate = E.ShipDate ,
TotalDue = E.TotalDue ,
ProductID = E.ProductID,
ProductName = E.ProductName,
UnitPrice = E.UnitPrice ,
UnitPriceDiscount = E.UnitPriceDiscount,
OrderQty = E.OrderQty ,
LineTotal = E.LineTotal
FROM [dbo].[Sales_EXT] E
WHERE FactSales.SalesOrderID=E.SalesOrderID
AND FactSales.SalesOrderDetailID=E.SalesOrderDetailID
AND FactSales.ProductID=E.ProductID
INSERT INTO FactSales (OrderDate
,ShipDate,TotalDue,ProductID,ProductName
,UnitPrice,UnitPriceDiscount,OrderQty,LineTotal)
SELECT E.OrderDate,E.ShipDate,E.TotalDue,E.ProductID
,E.ProductName,E.UnitPrice,E.UnitPriceDiscount
,E.OrderQty,E.LineTotal
FROM [dbo].[Sales_EXT] E
LEFT JOIN FactSales S ON S.SalesOrderID=E.SalesOrderID
AND S.SalesOrderDetailID=E.SalesOrderDetailID
AND S.ProductID=E.ProductID
END
Note that I have used a combination of Insert and Update commands to achieve the merge logic. This is because the merge command is not publicly available in Synapse as of now.
Creating a data integration pipeline
A pipeline building interface resembles that of ADF.
Let us move to the Orchestrate tab and add a pipeline as shown below:
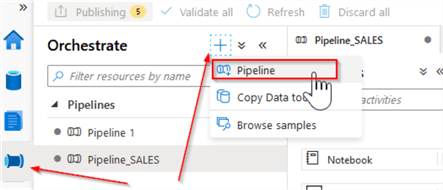
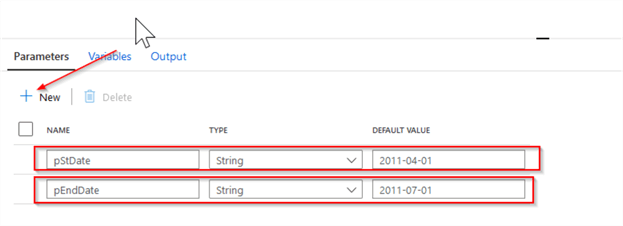
Add the pipeline parameters pStDate and pEndDate. Optionally, you can assign default values to these parameters as shown below:
Next, drag and drop a Notebook component to the design surface, name it (DWH_ETLin this example), open the Settings tab and select the DWH_ETL notebook from the drop-down list as seen in the image below:

Expand the Basic parameters section and add the parameter pOrderStartDate of the string type. Click the Dynamic content link under the Value section and enter the following expression: @pipeline().parameters.pStDate. This expression assigns the value of the pStDate parameter to the pOrderStartDate. Alternatively, you can select pStDate parameter at the bottom of the screen which will construct the required expression:

Add the parameter pOrderEndDate using the same method and assign it an expression @pipeline().parameters.pEndDate.
Next, add a SQL pool stored procedure activity to your pipeline. Open the Settings tab, select the SQL pool and the stored procedure we created earlier (dbo.USP_MERGE_SALES):

The last step in building this pipeline is adding success dependency between these two activities as shown below:

Now that our pipeline is ready, we will run it in a debug mode using the Debug button, as seen below:

This will open the parameters window, where you can enter start/end dates:

Once the execution starts, we can monitor its status in the Output tab:
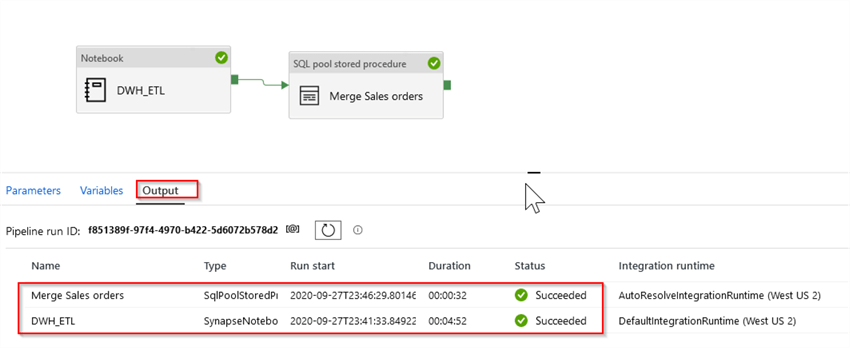
Now you can use the following SQL script to examine the results:
select top 100 * from FactSales
Finally, publish the pipeline to preserve the changes.
Conclusion
In this tip I have illustrated a simple way to create a data pipeline that involves SQL, storage, and Spark services. As you may have noticed, we did not need to create service endpoints because the services used in this example were attached to the workspace. Synapse pipelines also allow integration of services external to the Synapse workspace, such as Azure SQL Db, MS SQL Server, Azure Data Explorer. However, these pipelines require explicit creation of extra objects similar to linked services and data sets. I will demonstrate building such pipelines in upcoming tips.
Next Steps
- Read: Azure Synapse Analytics Overview
- Read: Create, develop, and maintain Synapse Studio (preview) notebooks in Azure Synapse Analytics
- Read: Pipelines and activities in Azure Data Factory
- Read: Orchestrate with pipelines

Fikrat Azizov (MCSE Data Platform and MCSE Azure Solutions Architect) has been working with SQL Server since 2002. Fikrat’s main passions are SQL Server performance optimization, cloud data technologies and machine learning. Fikrat is currently working as a Solutions Architect at Slalom Canada.
- MSSQLTips Awards: Author of the Year Contender – 2019-2022 | Rising Star (50+ tips ) – 2021