Problem
This tip is a collection of examples for invoking the rand() and newid() functions in SQL Server. The examples illustrate syntax issues and use case demonstrations for the functions. Special attention is devoted to simulating outcomes for SQL random numbers. Additionally, you will also discover the difference between random sampling without replacement and random sampling with replacement.
Solution
The rand() and newid() functions are two of my favorite SQL Server functions for generating SQL random numbers for simulations. In order to properly use the rand() function, you will likely benefit from a grasp of how to create random numbers with and without seeds. When you specify a seed value for the rand() function, its return value is the same for each execution of the function. If your random numbers are sampling from another source, such as a list of invoices or payments, you should also learn the difference between sampling without replacement and with replacement. Sometimes, when working with a data source that is assumed to be random, you want to test for two properties of randomness, as demonstrated towards the end of this tip: Evaluating the Randomness of SQL Random Numbers Functions.
Introductory Rand() Function Examples
The following script demonstrates unseeded and seeded rand() function examples:
- Example 1: Generates a random floating-point number, labeled [float 1], ranging from 0 up to but not including 1. Each time the query is executed, it may produce a different value.
- Example 2: With a pair of queries, can return two different random values, but each random value is named [float 1]. Repeatedly invoking the pair of queries will return a different pair of values for successive calls.
- Example 3: Demonstrates the use of seed values with the rand() function. The seed values are 123 and 456, respectively, for the first and second queries. Each query returns a different random value based on its seed value. Repeatedly invoking the pair of queries returns exactly the same pair of return values for successive calls.
- Example 4: Has three queries. The first and second queries have seed values of 5 and 55, respectively. The third query reuses the first seed value of 5. The first and second queries return random values based on their seed values. The third query returns the same value as the first query because it uses the same seed value. Repeatedly invoking the queries in the fourth example returns exactly the same set of three return values for successive calls.
use DataScience
-- first example: return a float number from a range of >= 0 and < 1
select rand() [float 1];
-- second example: sequentially return 2 float numbers from a range of >= 0 and < 1
select rand() [float 1];
select rand() [float 1];
-- third example: demo return values from rand with two different seed values
select rand(123) [float 1 with seed of 123];
select rand(456) [float 1 with seed of 456];
-- fourth example: demo return values from rand with two different seed values
-- followed by a third return value based on the first seed
select rand(5) [float 1 with seed of 5];
select rand(55) [float 1 with seed of 55];
select rand(5) [float 1 with seed of 5];Results for Query
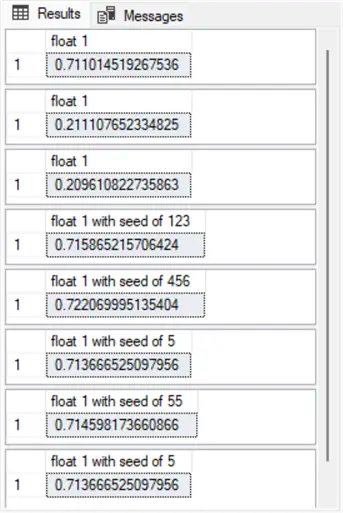
The following screenshot shows the Results tab contents from running the four examples once.
- First pane = first example.
- Second and third panes = second example.
- Fourth and fifth panes = third example.
- Sixth, seventh, and eighth panes = fourth example.
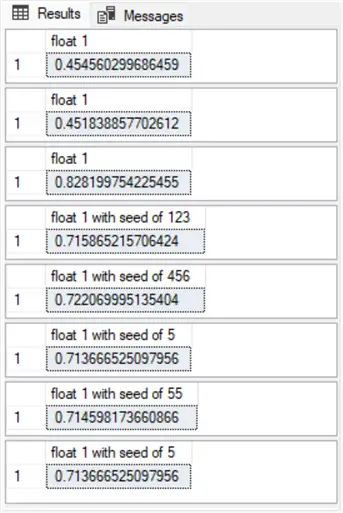
Following screenshot shows the Results tab contents from running the four examples a second successive time.
- The values appearing in the first, second, and third results panes are from the first and second examples, respectively. Notice that the result pane values do not match those in the preceding screenshot. This is because the rand() function calls for the first and second examples are unseeded.
- The values appearing in the remaining panes are for the third and fourth examples. The values in these panes below correspond exactly to values of the corresponding panes in the preceding screenshot. This is because the rand() function calls in the queries for third and fourth examples are seeded with the exact same seed values for the preceding screenshot as the following screenshot.
More Examples
The next set of three examples illustrates different contexts for configuring rand() function calls to simulate the throwing of one die or two dice. Each example includes 1 or 2 queries that convert native rand() function output, ranging from 0 up to but not including 1 to die face values in the range of 1 through 6.
- The floor() function returns whole number values in the range of 0 through 5.
- The addition of 1 to the floor() function output converts the range to 1 through 6, which corresponds to the values on die faces.
The first example is for the throwing of a single die. The second example is for the sequential throwing of a single die. The third example is for the concurrent throwing of a pair of dice.
-- first example: simulate throwing a die 1 time
select floor(rand() * 6) + 1 [one throw of die];
-- second example: simulate throwing a die 2 times sequentially
select floor(rand() * 6) + 1 [die 1, first throw];
select floor(rand() * 6) + 1 [die 1, second throw];
-- third example: simulate throwing two dice concurrently 1 time
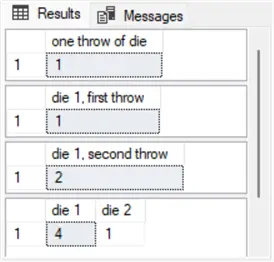
select (floor(rand() * 6) + 1) [die 1], (floor(rand() * 6) + 1) [die 2];The following screenshot shows result sets from the three simulation examples in the preceding script.
- First pane = the first example.
- Second and third panes = the second example.
- Fourth pane = the third example.
Simulating Throwing a Die 120000 Times
SQL random numbers functions like rand() and newid() must generate unbiased results to ensure accurate simulations in both gaming and business contexts. In a sequence of die rolls, each face should appear with equal frequency over many trials. When observed outcomes deviate significantly from expected outcomes over many sets of die rolls, the function may not be truly random. Likewise, randomness is crucial for fair card shuffling, roulette spins, lottery draws, and game mechanics. The same principle applies to business applications such as risk modeling, financial forecasting, inventory simulations, and customer behavior analysis, where proper randomization ensures realistic outcomes.
Explanation of Process
This section presents and describes a T-SQL script for simulating the throwing of a die 120000 times and evaluates the randomness of the rand() function in the simulation. The script performs four steps. The beginning of each step is denoted with a comment line, such as Step 1.
- Step 1: Executes the simulation with the rand() function in a while loop as well as creating a temp table (#temp_rolls_for_1_die) for storing die outcomes and local variables (@i, @ChiSquareStatistic, and @df) for implementing and monitoring the simulation’s performance.
- Step 2: Computes and stores the observed and expected die face counts from the simulation.
- Step 3: Computes and displays the @ChiSquareStatistic value and degrees of freedom (@df) based on the observed and expected die face counts from the simulation.
- Step 4: Displays for comparison the @ChiSquareStatistic value from Step 3 to critical ChiSquareTable values from the #ChiSquareTable object for the degrees of freedom in the simulation. The #ChiSquareTable values are reconfigured from an earlier tip to simplify their use within the current tip. If the @ChiSquareStatistic value is less than its corresponding value in #ChiSquareTable based on matching @df values, then the rand() function returns fair die throws for a set of outcomes.
SQL Code
-- Step 1
-- simulate throwing a die 120000 times
-- create a temp table for storing the throw outcomes, and
-- declare local variables referenced in the simulation evaluation
if object_id('tempdb..#temp_rolls_for_1_die') is not null
drop table #temp_rolls_for_1_die;
create table #temp_rolls_for_1_die(
id int identity(1,1) primary key,
dice_number int
);
-- throw a die @i times where max(@i) is 120000
-- and save throw outcomes in #temp_rolls_for_1_die
declare @i int = 1, @ChiSquareStatistic float, @df float;
while @i <= 120000
begin
insert into #temp_rolls_for_1_die (dice_number)
VALUES (floor(rand() * 6) + 1);
set @i = @i + 1
end;
-- optionally display 120000 die throws
-- select * from #temp_rolls_for_1_die order by id;
-- Step 2
-- compute observed and expected counts for
-- throwing a die 120000 times
if object_id('tempdb..#chi_square_data') is not null
drop table #chi_square_data;
select
dice_number
,cast(count(*) as float) [observed count]
,cast(120000/6 as float) [expected count]
into #chi_square_data
from #temp_rolls_for_1_die
group by dice_number
order by dice_number;
-- optionally display observed and expected counts
select * from #chi_square_data order by dice_number
-- Step 3
-- compute and display ChiSquare Statistic and degrees of freedom
select
@ChiSquareStatistic = sum([for ChiSquare Statistic])
,@df = count(*) - 1
from
(
select
dice_number
,[observed count]
,[expected count]
,(power([observed count] - [expected count],2)/[expected count]) [for ChiSquare Statistic]
from #chi_square_data
--order by dice_number
) [for Chi Square Statistic]
select @ChiSquareStatistic [@ChiSquareStatistic], @df [@df]
-- Step 4
-- compare @ChiSquareStatistic to critical ChiSquareTable value
-- for matching degrees of freedom (@df)
-- for assessing statistical significance
if object_id('tempdb..#ChiSquareTable') is not null
drop table #ChiSquareTable;
CREATE TABLE #ChiSquareTable (
DegreesOfFreedom INT PRIMARY KEY,
CriticalValue_95 FLOAT, -- α = 0.05 (Common)
CriticalValue_99 FLOAT -- α = 0.01 (Stronger significance)
);
-- Insert common critical values for df (you can expand this with more rows)
INSERT INTO #ChiSquareTable (DegreesOfFreedom, CriticalValue_95, CriticalValue_99)
VALUES
(1, 3.84, 6.63),
(2, 5.99, 9.21),
(3, 7.81, 11.34),
(4, 9.49, 13.28),
(5, 11.07, 15.09),
(6, 12.59, 16.81),
(7, 14.07, 18.48),
(8, 15.51, 20.09),
(9, 16.92, 21.67),
(10, 18.31, 23.21);
-- Query critical value for a given df
select DegreesOfFreedom, CriticalValue_95 AS CriticalChiSquare_95, CriticalValue_99 AS CriticalChiSquare_99
from #ChiSquareTable
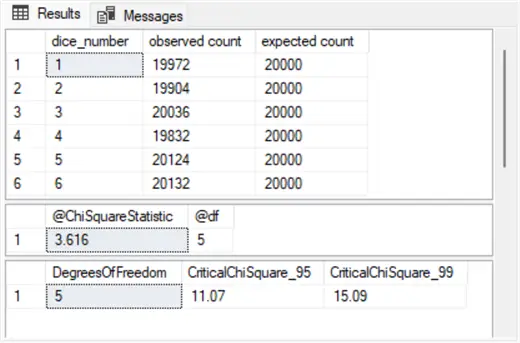
where DegreesOfFreedom = @df;The following screenshot shows results from the preceding script.
- Results Pane 1: Shows the observed versus the expected counts from Step 2 in the script for each of the six die face values in the simulation. If you repeat the script, your observed count values can vary slightly across result sets.
- Results Pane 2: Shows the @ChiSquareStatistic and @df local variable values computed in Step 3 by the script.
- Results Pane 3: Shows the outcome from Step 4 of a lookup in the #ChiSquareTable object for the @df value (5). Because the @ChiSquareStatistic value (3.616) is less than the critical Chi Square value for 5 degrees of freedom (11.07), the differences between the observed counts and expected counts are not statistically different at the .05 level. This means the observed counts are not statistically different than the expected counts at the .05 level.
Random Sampling Rows from a Table With and Without Replacement
There are two different widely used ways of randomly sampling rows from a table (or any collection of entities):
- Sampling Without Replacement. Once a row is randomly selected, it is removed from the pool of rows from which subsequent rows are selected.
- Sampling With Replacement. After each row is randomly selected, it is returned to the pool of rows for subsequent random selections.
Randomly sampling all the rows from a table without replacement is equivalent to shuffling the rows in a table. The shuffled rows are the same as those in the source dataset, except the order of the rows is different.
Variations
You can implement this style of random sampling with an order by clause for the newid() function. Each original row can appear only once in the result set of randomly selected rows. If you use a top keyword in the SELECT statement with an order by clause for the newid() function, then your query will return a subset of the rows in the original table instead of all the rows. For example, if you want to simulate the selection of the top card from a freshly shuffled deck of cards, your query could add the top keyword with an argument of 13 to a query that shuffles the rows in a table with 52 rows. Each of the table rows could represent one of the 52 cards in a deck of cards with four distinct suits and 13 cards within each suit.
Randomly sampling rows with replacement allows rows from the original table to appear one or more times in the result set query statement. This style of sampling is especially well-suited for machine learning tasks, such as enhancing multiple regression models via bagging, which is based on random sampling with replacement, or randomizing the order of offers across prospective customers so that each offer has an equal chance of being exposed to all prospective customers. The rand() function is well-suited for these kinds of applications.
Sampling Rows Without Replacement
The following script presents an example of how to implement sampling without replacement with the newid() function in an order by clause of a select statement. In addition, the script shows that sampling without replacement cannot be implemented by replacing the newid() function with the rand() function.
- First and Second Statements in the script create a fresh copy of the #student table in the tempdb database. As you can see, the #student table has two columns:
- The student_id column, which is for the primary key, has an int data type.
- The name column has a nvarchar data type. Student names are stored in this column.
- Third Statement inserts student_id and name values into the student_id and name columns, respectively.
- Fourth Statement lists the student_id and name values from the #student table by primary key value.
- Fifth Statement lists name column values from the #student table ordered by the newid() function return values.
- Sixth Statement appears to list name column values from the #student table by the rand() function return values in its order by clause. This statement is identical to the fifth statement, except that it replaces the newid() function with the rand() function. Unlike the newid() function, the rand() function in an order by clause does not display the rows from the source data in a shuffled order. As a result, the result set from the sixth statement does not display the rows in a shuffled order relative to the rows in the original data source.
-- create a fresh copy of the #student table
if object_id('tempdb..#student') is not null
drop table tempdb..#student;
-- create a #sample table
create table #student (
student_id int primary key,
name nvarchar(50)
);
-- populate #student with names
insert into #student (student_id, name) values
(1, 'Barbra'),
(2, 'Dee'),
(3, 'Rod'),
(4, 'Louise'),
(5, 'Robert');
-- retrieve student names in primary key order
select name
from #student
-- retrieve student names in random order by the newid() function
select name
from #student
order by newid();
-- attempt to retrieve student names in random order by the rand() function
-- notice it does not work
select name
FROM #student
order by rand();Review the Results
The following screenshot shows the result sets for each of the three select statements in the preceding script.
- Result Set 1: Shows the name values from the #student table in the default primary key order.
- Result Set 2: Shows the name values from the #student table in a shuffled order based on the return values from the newid() function in the order by clause of the second select statement.
- Result Set 3: Shows the name values from the #student table in an order based on the return values from the rand() function in the order by clause of the third select statement. Because the return values from the rand() function in the order by clause are identical for each row in the source data, the name values are listed in their corresponding primary key order.
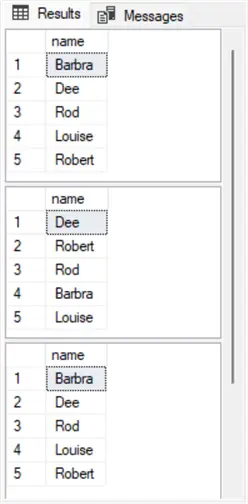
The following script shows the second select statement from the preceding script replicated three times. If you run the following script, it will return the names from the #student table in three different shuffled orders. This outcome confirms that the newid() function in the order by clause of each select statement freshly shuffles the rows from the #student table.
-- retrieve student names in random order by newid function
select name
from #student
order by newid();
-- retrieve student names in random order by newid function
select name
from #student
order by newid();
-- retrieve student names in random order by newid function
select name
from #student
order by newid();The following screenshot shows three result sets – one for each of the three copies of the second select statement in the first script within this section. Notice that each result set lists the name values from the #student table in a different order for each select statement. Also notice that each select statement displays each of the original five student names just once. These are expected outcomes for sampling rows from a table without replacement.
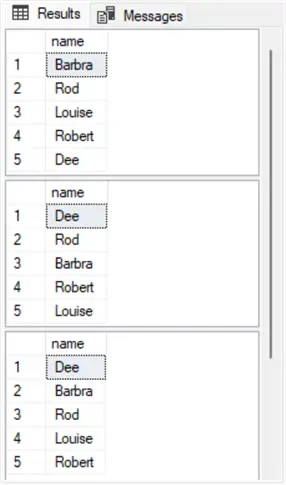
Sampling Rows With Replacement
You can relatively easily implement sampling with replacement with either the rand() function or the newid() function. The following script shows an approach to sampling with replacement that uses the rand() function.
- The script starts by creating and populating the #student table. This part of the example copies the code that performs the same function in the preceding script. After creating and populating the #student table, the script optionally prints the name column values by primary key values.
- Next, the script creates a fresh copy of the #rand_student_name table. This table is for storing the random sample with replacement. The table has three columns whose names are: student_id, name, and student_id_rand. A fresh copy of the table is populated inside a while loop.
- The while loop successively iterates from an initial value for @index through @max_index. When the @index value exceeds @max_index control passes to the first statement after the while loop.
- On each pass through the while loop, the @student_id_rand local variable is assigned a random value of 1 through 5 from the rand() function. The values of 1 and 5 correspond to minimum and maximum primary key values in the #student table.
- The select statement portion of an insert into…select bulk insert statement populates a row in the #rand_student_name table.
- After the insert into statement populates a fresh row in the #rand_student_name table, the current value of the @index is updated by 1.
SQL Code
use DataScience
-- sampling with replacement examples
-- base table from which to sample
-- create a fresh copy of the #student table
if object_id('tempdb..#student') is not null
drop table tempdb..#student;
-- create a #sample table
create table #student (
student_id int primary key,
name nvarchar(50)
);
-- populate #student with names
insert into #student (student_id, name) values
(1, 'Barbra'),
(2, 'Dee'),
(3, 'Rod'),
(4, 'Louise'),
(5, 'Robert');
--/*
-- optionally display student names in primary key order
select name
from #student
--*/
-- create and populate a fresh version of the #rand_student_name table
if object_id('tempdb..#rand_student_name') is not null
drop table #rand_student_name;
-- create table #rand_student_name
-- student_id is not a primary key so the table can have
-- dupe student_id values
create table #rand_student_name(
student_id int,
name nvarchar(50),
student_id_rand int
);
-- also declare and populate @student_id_rand,
-- @index, and @max_index for sampling
-- with replacement with rand() function
declare
@student_id_rand int
,@index int = 1 -- goes from 1 to 5 in the following while loop instance
,@max_index int = 5;
-- use while statement to populate student_id, name, and student_id_rand
-- column values for @max_index successive rows with rand() function
while @index <= @max_index
begin
set @student_id_rand = (select floor(rand() * 5) + 1)
insert into #rand_student_name
select student_id [student_id], name, @student_id_rand [@student_id_rand]
from #student
where student_id = @student_id_rand;
set @index = @index + 1
end
-- optionally display #rand_student_name
select * from #rand_student_name
-- re-run the code multiple times to confirm the ability to generate
-- distinct name sets with the rand() function for sampling with replacementReview Results
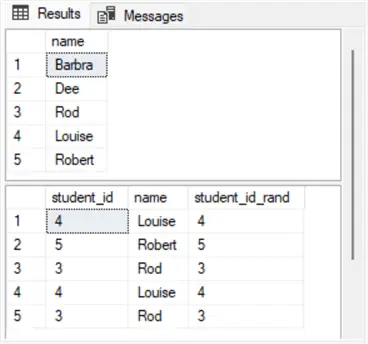
The following screenshot shows a pair of result sets from running the preceding script once.
- The top pane shows the name column values in the #student table.
- The bottom pane shows another set of rows based on the #rand_student_name table. This table is populated by random sampling with replacement with the rand() function from the #student table.
Notice that the student_id column values in the bottom pane do not appear in the order of the primary key for the #student_id. Additionally, the first and fourth rows in the bottom pane are duplicate rows. When populating a set of rows with random sampling with replacement, it is common, but not necessary, to have the resulting sampled dataset include duplicate rows. This is because each new sampled row is selected with replacement from the original whole set of rows.
You can also implement sampling with replacement using the newid() function. The following query sample illustrates one way of implementing this objective.
How Query Works
This query depends on a cross join between two result sets.
- A cross join is a way of pairing all the rows from one data source with all the rows from a second data source.
- The inner select statement for the cross join keyword returns 5 rows with newid() function return values based on the rows in the spt_values table within the dbo schema of the master database).
- For the current sample, the Cartesian product implemented by cross join keyword returns 25 rows – five rows from the inner select statement with an alias of t crossed with five other rows from the outer select statement with an alias of s.
- This query depends on the availability of a #student table in the tempdb database. The spt_values table in the master database is undocumented but commonly used for applications like the one described here.
-- return five randomly selected names from #student with replacement with the newid() function
select top 5 s.* from #student s
cross join (select top 5 newid() sampleid from master.dbo.spt_values) t
order by newid();
-- re-run the code multiple times to confirm its ability to generate distinct name sets
-- with the newid() function for sampling with replacementThe following screenshot shows the result set from running the preceding script. Notice that there are three instances of Rod in the name column. This means the name Rod was sampled three out of five times by the preceding query. This is a feasible return sample for a query returning sample values with replacement.
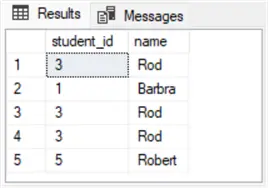
Next Steps
Here is a list of sources about SQL random numbers functions from MSSQLTips.com and other select sources:
- Evaluating the Randomness of SQL Server Random Number Functions
- Digitally Signing a SQL Stored Procedure
- CRYPT_GEN_RANDOM (Transact-SQL)
- A More Versatile SQL Random Numbers Function
- Different ways to get random data for SQL Server data sampling
- How can I generate a cryptographically secure number in SQL Server?
- SQL Server stored procedure to generate random passwords
- Generate Unique Random Number in SQL Server
- SQL Server Function to Generate SQL Random Numbers
- rand vs. crypt_gen_random
- Difference between New_Id() & Rand() SQLSERVER2005
- Generating Random Numbers in SQL Server Without Collisions
- SQL Server Column Encryption and Decryption with Code Examples
I am also interested in the crypt_gen_random() function, but this one focuses on cryptographic security, which is outside the scope of this tip. You can get an introduction to selected cryptographic security features available from SQL Server with either of these two tips: SQL Server Column Encryption and Decryption with Code Examples and Digitally Signing a SQL Stored Procedure.
