By: Koen Verbeeck
Overview
In this part of the tutorial, we’ll learn how we can improve the execution performance of queries using window functions.
Explanation
Using window functions can be resource intensive, as data has to be grouped and sorted before the results can be calculated. However, due to the nature of window functions and how they are implemented in SQL Server, window functions are typically faster and scale better than alternatives using other methods (such as self-joins or cursors).
Luckily, we can help the SQL Server database engine by adding indexes to support window functions.
Test Set-up
Let’s create a test table with some sample data in it. Using the ROW_NUMBER function (discussed in part 5) we can create a “tally table” to generate a sequence of numbers:
DROP TABLE IF EXISTS dbo.Inventory;
WITH T0 AS (SELECT N FROM (VALUES (1),(1)) AS tmp(N))
,T1 AS (SELECT N = 1 FROM T0 AS a CROSS JOIN T0 AS b)
,T2 AS (SELECT N = 1 FROM T1 AS a CROSS JOIN T1 AS b)
,T3 AS (SELECT N = 1 FROM T2 AS a CROSS JOIN T2 AS b)
,T4 AS (SELECT N = 1 FROM T3 AS a CROSS JOIN T3 AS b)
,T5 AS (SELECT N = 1 FROM T4 AS a CROSS JOIN T4 AS b) -- over 4 billion rows
SELECT
InventoryID = ROW_NUMBER() OVER (ORDER BY NEWID())
,InventoryChange = RAND(N) * 100000 - 30000
INTO dbo.Inventory
FROM
(
SELECT TOP 100000
N = ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM T5
) tmp
ORDER BY InventoryID;
Two tricks are used:
- The first ROW_NUMBER function is sorted by NEWID() to generate a randomized distribution of the InventoryID column
- The second ROW_NUMVER function is sorted by (SELECT NULL). This tells SQL Server sorting doesn’t matter.
The script generates a 100,000 row table within a second. Next, we’re going to create some warehouses where the fictional products are stored. With a similar T-SQL query, we generate 100 warehouses:
DROP TABLE IF EXISTS dbo.Warehouses;
WITH T0 AS (SELECT N FROM (VALUES (1),(1)) AS tmp(N))
,T1 AS (SELECT N = 1 FROM T0 AS a CROSS JOIN T0 AS b)
,T2 AS (SELECT N = 1 FROM T1 AS a CROSS JOIN T1 AS b)
,T3 AS (SELECT N = 1 FROM T2 AS a CROSS JOIN T2 AS b)
SELECT TOP 100
Warehouse = CONCAT('Warehouse ',ROW_NUMBER() OVER (ORDER BY (SELECT NULL)))
INTO dbo.Warehouses
FROM T3;
Now we’re going to cross-join the warehouses with the inventory transactions. This will generate a 10,000,000 row table which we can use to test performance of our window functions.
SELECT
w.[Warehouse]
,i.[InventoryID]
,i.[InventoryChange]
INTO dbo.InventoryChanges
FROM [dbo].[Warehouses] w
CROSS JOIN dbo.[Inventory] i;
This table takes about 400MB on my machine and took about 10 seconds to generate. With the following query, we’re going to calculate a running total (see part 4) for each warehouse, simulating a stock level influenced by the inventory changes.
SELECT
[Warehouse]
,[InventoryChange]
,Balance = SUM([InventoryChange]) OVER (PARTITION BY [Warehouse]
ORDER BY [InventoryID]
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM dbo.[InventoryChanges]
ORDER BY [Warehouse],[InventoryID];
Improving Performance
Without any indexes, the query runs for about a minute:
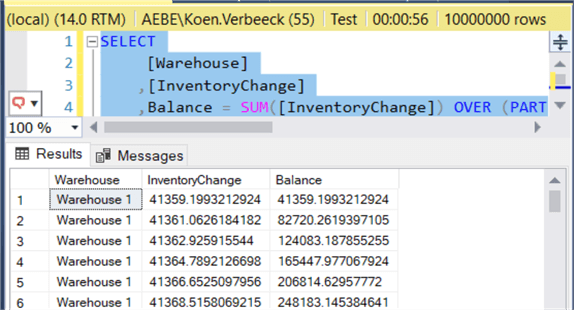
The query has quite some read-ahead reads in a worktable:

The execution plan shows an expensive sort, which is used for the PARTITION BY and ORDER BY clauses of the window function.

Let’s try to get rid of this sort by adding an index on the Warehouse and InventoryID columns:
CREATE NONCLUSTERED INDEX [NCI_InventoryChanges]
ON [dbo].[InventoryChanges]
(
[Warehouse] ASC
,[InventoryID] ASC
)
INCLUDE ([InventoryChange]);
When we re-execute the query, the sort operator has disappeared and the query now takes about 38 seconds to execute:
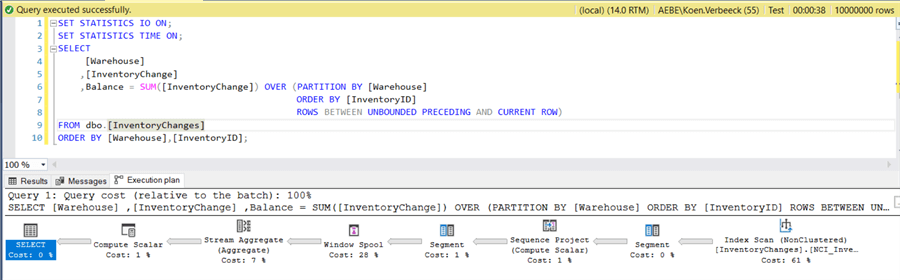
The read-ahead reads of the worktable have been reduced to zero (logical reads of the base table have stayed roughly the same):

In general, you can optimize window functions by following these rules:
- In the index, sort on the columns of the PARTITION BY clause first, then on the columns used in the ORDER BY clause.
- Include any other column referenced in the query as included columns of the index.
Keep in mind that if there are multiple window functions, it might not be possible to optimize them all at once, especially if some have different sort orders (ascending vs descending).
