By: Koen Verbeeck
Overview
In this part, we’ll take a close look at the ROW_NUMBER function, probably the most used window function. It’s a ranking function, which is the next topic in this tutorial.
Explanation
The syntax of ROW_NUMBER is like any other window function:
ROW_NUMBER() OVER (PARTITION BY expression ORDER BY expression)
This function adds a virtual sequence number to the rows. Depending on the PARTITION BY, this sequence can be restarted multiple times. I mention “virtual”, because the row numbers only exist while querying. If you want to persist row numbers physically, IDENTITY and sequences are better options.
Let’s see this function in action:
SELECT
sc.[EnglishProductSubcategoryName]
,[c].[EnglishProductCategoryName]
,[RowCnt] = ROW_NUMBER() OVER (ORDER BY [sc].[EnglishProductSubcategoryName])
,[RowCntPerCategory] = ROW_NUMBER() OVER (PARTITION BY c.[EnglishProductCategoryName]
ORDER BY [sc].[EnglishProductSubcategoryName])
FROM [dbo].[DimProductSubcategory] sc
JOIN [dbo].[DimProductCategory] c ON [c].[ProductCategoryKey] = [sc].[ProductCategoryKey]
ORDER BY 2,1;
This query calculates a general row number and a row number that is reset for every product category:
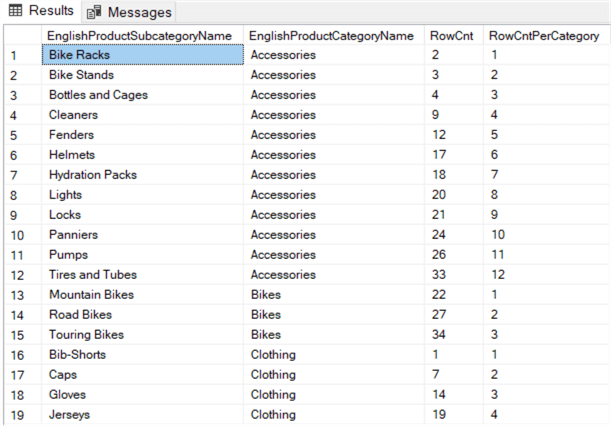
Removing Duplicates
The reason why ROW_NUMBER is so popular is because it’s easy to remove duplicate rows. Truly duplicate rows – where every column has the exact same values - can be removed with DISTINCT or GROUP BY, but you can have also duplicates in a business sense. Say for example a table normally stores one record for each employee. Because of an issue, some employees have multiple rows. We want to remove all the unnecessary rows and only keep the most recent one. The rows we want to delete are the “duplicate rows”. Suppose we have the following table with employee data:
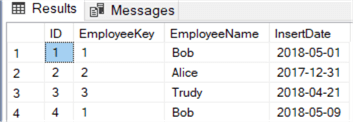
Due to a mistake, Bob was inserted twice, while only one record per employee is allowed (a unique index would have prevented this). Now we want to remove the second row of employee Bob (ID = 4). The business key is the EmployeeKey, which is equal to one for both records. With the following query, we can mark the second row using ROW_NUMBER:
SELECT
[ID]
,[EmployeeKey]
,[EmployeeName]
,[InsertDate]
,RID = ROW_NUMBER() OVER (PARTITION BY [EmployeeKey] ORDER BY [InsertDate])
FROM [dbo].[EmployeesDuplicate]
This returns the following results:
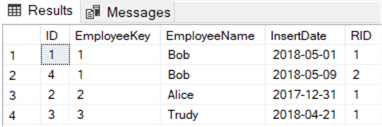
Now we only have to delete the rows where the RID column is not equal to one:
WITH cte_source AS
(
SELECT
[ID]
,[EmployeeKey]
,[EmployeeName]
,[InsertDate]
,RID = ROW_NUMBER() OVER (PARTITION BY [EmployeeKey] ORDER BY [InsertDate])
FROM [dbo].[EmployeesDuplicate]
)
DELETE FROM [dbo].[EmployeesDuplicate]
FROM [dbo].[EmployeesDuplicate] ed
JOIN [cte_source] c ON [c].[ID] = [ed].[ID]
WHERE c.RID <> 1;
If you want to keep the most recent record instead, you need to sort descending in the ROW_NUMBER function. Of course it would be easier to just delete the record where ID = 4. However, it would not be that straight forward when the table has thousands of rows and where one record doesn’t have only one, but potentially multiple duplicate instances. This pattern with ROW_NUMBER is an ideal construct to clean out your table.
There are many similar scenarios that can benefit from this pattern:
- A table keeps history of the records. One record is the current records, and all the other rows for the same object are history rows. You want to remove some of the older history records. You can for example keep the 5 most recent records and delete all older rows.
- You have a source table where records are logged multiple times through the day. In your batch process, you only need the most recent record for your data warehouse. With this pattern, you can easily identity the most recent record and filter out all other records.
- You add a column “CurrentRecord” to your table. With ROW_NUMBER, you can run an UPDATE statement that flags the current record as 1 and the other records as 1.
In short, you can use this pattern in SELECT, UPDATE and DELETE statements.
Additional Information
- There are quite a number of tips that use ROW_NUMBER:
