Problem
Next to the average and the median, there is another statistical value that you can calculate over a set: the mode. This is the value that appears the most often in the set. The average and the median are straight forward to calculate with T-SQL in SQL Server, but how can we determine the mode using T-SQL?
Solution
The mode is a statistical calculation that returns the value in a set that occurs the most frequently. A good example is the most common name in a country. In this example, the set is all the possible names found in that country. In 2013, the mode for male baby names was Noah in the United States.
Let’s illustrate the difference between average, median and mode with a simple numerical example using the set {1, 2, 2, 3, 4, 7, 9}.
- Average = (1 + 2 + 2 + 3 + 4 + 7 + 9) / 7 = 4
- Median (the middle value ordered ascending) = 1, 2, 2, 3, 4, 7, 9 = 3
- Mode (most frequent value) = 1, 2, 2, 3, 4, 7, 9 = 2
Test Set-up
We will use the same test-up as in the tip Creating a box plot graph in SQL Server Reporting Services. There we analyzed the durations of the tickets of different customer service representatives. Now we will search the customer representative with the highest number of tickets for each month. In this case, the representative with the highest ticket count is the mode. For easy reference, here is the T-SQL script for creating the test data:
CREATE TABLE dbo.DimRepresentative( SK_Representative INT NOT NULL ,Name VARCHAR(50) NOT NULL CONSTRAINT [PK_DimRepresentative] PRIMARY KEY CLUSTERED ( SK_Representative ASC ) ); GO INSERT INTO dbo.DimRepresentative(SK_Representative,Name) VALUES (1,'Bruce') ,(2,'Selena') ,(3,'Gordon') ,(4,'Harvey'); GO CREATE TABLE dbo.FactCustomerService (SK_CustomerServiceFact INT IDENTITY(1,1) NOT NULL ,SK_Representative INT NULL ,TicketNumber UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() -- degenerate dimension ,TicketTimestamp DATETIME2(3) NOT NULL ,Duration INT NOT NULL); GO INSERT INTO dbo.FactCustomerService(SK_Representative,TicketTimestamp,Duration) SELECT SK_Representative = FLOOR(RAND()*4) + 1 -- random assign a duration to a customer representative ,TicketTimestamp = DATEADD(DAY,RAND()*100,'2014-01-01') ,Duration = RAND()*100000; GO 100
Since the script uses random values, it is possible that you see different outcomes on your machine than those displayed in this tip.
Calculating the Mode with T-SQL
The first step is to count the number of tickets for each representative per month. This is easily done with the COUNT function and a GROUP BY clause:
SELECT Representative = d.Name ,[Month] = DATENAME(MONTH,[TicketTimestamp]) ,cnt = COUNT(1) ,MonthOrder = MONTH([TicketTimestamp]) FROM [dbo].[FactCustomerService] f JOIN [dbo].[DimRepresentative] d ON f.SK_Representative = d.SK_Representative GROUP BY Name, DATENAME(MONTH,[TicketTimestamp]),MONTH([TicketTimestamp]) ORDER BY MonthOrder
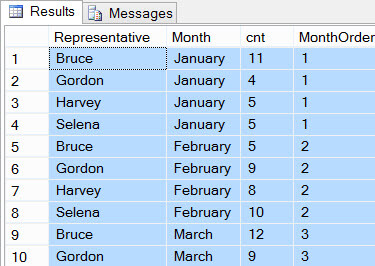
You can for example see that Bruce got the highest count for January: 11 tickets. Now we have to select the highest count for each month. This can be done using the ROW_NUMBER function where we partition on the month. This function is a window function, which means it is calculated after the GROUP BY has been applied to the data. Therefore we can embed the COUNT inside the ROW_NUMBER function so we can sort on it:
SELECT Representative = d.Name ,[Month] = DATENAME(MONTH,[TicketTimestamp]) ,cnt = COUNT(1) ,rid = ROW_NUMBER() OVER (PARTITION BY DATENAME(MONTH,[TicketTimestamp]) ORDER BY COUNT(1) DESC) ,MonthOrder = MONTH([TicketTimestamp]) FROM [dbo].[FactCustomerService] f JOIN [dbo].[DimRepresentative] d ON f.SK_Representative = d.SK_Representative GROUP BY Name, DATENAME(MONTH,[TicketTimestamp]),MONTH([TicketTimestamp]) ORDER BY MonthOrder

All that is left to do is to select the rows where the row number is equal to one.
WITH CTE_CountPerMonth AS ( SELECT Representative = d.Name ,[Month] = DATENAME(MONTH,[TicketTimestamp]) ,cnt = COUNT(1) ,rid = ROW_NUMBER() OVER (PARTITION BY DATENAME(MONTH,[TicketTimestamp]) ORDER BY COUNT(1) DESC) ,MonthOrder = MONTH([TicketTimestamp]) FROM [dbo].[FactCustomerService] f JOIN [dbo].[DimRepresentative] d ON f.SK_Representative = d.SK_Representative GROUP BY Name, DATENAME(MONTH,[TicketTimestamp]),MONTH([TicketTimestamp]) ) SELECT Representative ,TicketCount = cnt ,[Month] FROM CTE_CountPerMonth WHERE rid = 1 ORDER BY MonthOrder;

Handling Ties
But what if there are two representatives holding the same high ticket count in a month? The ROW_NUMBER function doesn’t deal with ties. Right now, the representative is - in theory - randomly returned. To get around this, you can add a tie-breaker to the ROW_NUMBER function. For example, you could also sort on the representative itself. If two representatives with the same high score are found, the one that comes first in the alphabet is returned.
If you want to return actual ties, consider replacing the ROW_NUMBER function with the RANK function, since the RANK function is sensitive to ties.
Next Steps
- You can use the T-SQL scripts from this tip to try it out yourself. Replace ROW_NUMBER with RANK to see if it changes behavior.
- To get more detail about ROW_NUMBER and RANK, check out the tip SQL Server 2005 and 2008 Ranking Functions Row_Number and Rank.
- If you are interested in window functions, the book Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions by Itzik Ben-Gan is highly recommended.

Koen Verbeeck is a seasoned business intelligence consultant with over a decade of experience with the Microsoft Data Platform. He holds several certifications, including Azure Data Engineer. He’s a prolific writer, with over 375 articles on technologies such as Microsoft Fabric, SSIS, ADF, SSAS, SSRS, MDS, Power BI, Snowflake and Azure services. He has spoken at various events such as PASS, SQLBits, dataMinds Connect and many others. He frequently delivers educational webinars on MSSQLTips.com. For his efforts, Koen has been awarded the Microsoft MVP data platform award for many years.
- MSSQLTips Awards:
- Leadership Award (200+ Tips) – 2021
- Author of the Year – 2014/2020/2022
- Author Contender – 2024/2025


