Problem
During the early phases of an application, inserts perform just fine. Over time, they progress from singleton inserts, to stored procedures performing inserts, to stored procedure calls using table-valued parameters to handle multiple rows, and finally, to some sort of bulk insert or BCP process. As the application matures, and volume increases, that single table accepting this bulk data quickly becomes your most painful bottleneck. Some would suggest you partition your tables, or increase memory so you can use In-Memory OLTP, or switch to SSIS or some other ETL process, or even upgrade your entire disk subsystem to SSDs or better. But what if you don’t have the budget, aren’t using the required edition, or don’t have the luxury of involving or waiting for hardware or architectural changes?
Solution
I’ll start by describing the simplest variation of the problem. Multiple copies of an app (possibly each server in a web farm) are competing to insert large blocks of data into a single table. We’ll use BULK INSERT in this example, which allows you to use the TABLOCK option and, in some cases, benefit from minimal logging. This trades one performance aspect (speed) for another (concurrency). The effect is that when you have multiple processes vying to perform their own BULK INSERT operations, the process becomes serial: The first one in line performs their operation, while the others wait; when they are finished, the next one gets their turn; and so on. The following diagram shows how this works in a very simple setup where four web servers are trying to perform these operations:
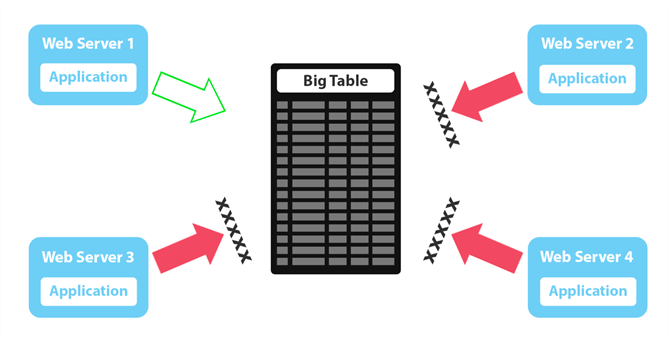
We can demonstrate this effect by creating the following database and table:
CREATE DATABASE Dumpster;<br />GO
ALTER DATABASE Dumpster SET RECOVERY SIMPLE;<br />GO
USE Dumpster;<br />GO
CREATE TABLE dbo.DumpsterTable<br />(<br /> id bigint NOT NULL IDENTITY(1,1),<br /> a varchar(256), b varchar(256),<br /> c varchar(256), d varchar(256),<br /> e varchar(256), f varchar(256),<br /> g varchar(256), h varchar(256),<br /> i varchar(256), j varchar(256),<br /> CONSTRAINT PK_Dumpster PRIMARY KEY(id),<br /> INDEX IX_Dumpster_IX1 (c,d),<br /> INDEX IX_Dumpster_IX2 (j,h)<br />);
And then we can generate a single file to bulk insert over and over. Running the following query to generate 500,000 rows, and then saving the results to a CSV file, file took about 17 seconds on my machine; your mileage may vary.
(<br /> SELECT TOP (10000)<br /> a = CONVERT(varchar(13), ABS(object_id)), <br /> b = CONVERT(varchar(13), ABS(object_id)) <br /> + '-' + CONVERT(varchar(11), column_id),<br /> c = CONVERT(varchar(36), NEWID())<br /> FROM sys.all_columns ORDER BY c<br />),<br />m AS<br />(<br /> SELECT a,b,c, d = REVERSE(c),<br /> e = SUBSTRING(c,1,COALESCE(NULLIF(CHARINDEX('F',c),-1),12)),<br /> f = CONVERT(char(10),GETDATE(),120)<br /> FROM src<br />)<br />SELECT a,b,c,d,e,f,<br /> g = REVERSE(f), h = REVERSE(e),<br /> i = COUNT(*) OVER(PARTITION BY e),<br /> j = 4<br />FROM m<br />CROSS JOIN (SELECT TOP (50) * FROM sys.all_objects) AS x<br />ORDER BY c;
-- File > Save Results As > CSV e.g. to c:\temp\Dumpster.csv
Now, we want to BULK INSERT to this table without overwriting the identity column, because it is what allows us to use the same file over and over again during testing (and we definitely want a unique key on this table based on where we’re going). You might have a different key in your existing data, which is great, but to bypass the identity column I’m going to create a simple view:
CREATE VIEW dbo.vDumpsterTable -- hide identity column from bulk insert<br />AS<br /> SELECT a,b,c,d,e,f,g,h,i,j<br /> FROM dbo.DumpsterTable;
Next we’ll have a stored procedure that handles the BULK INSERT:
CREATE PROCEDURE dbo.LoadDumpsterData<br />AS<br />BEGIN<br /> SET NOCOUNT ON;
BULK INSERT dbo.vDumpsterTable <br /> FROM 'c:\temp\Dumpster.csv' WITH <br /> (<br /> TABLOCK, <br /> ROWTERMINATOR = '\n',<br /> FIELDTERMINATOR = ','<br /> );<br />END
Finally, we’ll create four jobs to impersonate the four web servers and applications from the diagram above. (This processing in your environment doesn’t necessarily come from jobs, but this lets us easily synchronize execution to simulate worst case scenario – all threads attempt to write simultaneously.) They each contain a single step with this code:
EXEC Dumpster.dbo.LoadDumpsterData;<br />GO 5
In Object Explorer > SQL Server Agent, we can right-click Job Activity Monitor, select View Job Activity, highlight all four jobs, and select “Start Jobs:”

Observe how long they take (right-click any job and select “View History”). On my system, they averaged over six minutes. We’ll use this as a baseline for comparison as we introduce a slightly different way to pull in this data. We can also look at waits that occurred during this period and observe that the majority of waits are PAGEIOLATCH_EX (including the big spike). This makes sense because they’re all trying to load and write pages from the same constantly-locked table:
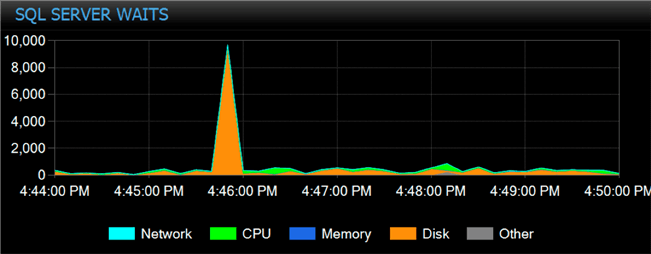
The processors are also slamming here, with prolonged bouts of high CPU usage and high context switches:

We have two problems; one is that each web server is waiting on the others before it can do any work, and the other is that this is exacerbating the problem by making everyone wait. This is the opposite of scalability. And this symptom is not even that severe; it’s on an SSD drive with no other activity. I can envision the problem compounded on slow, mechanical drives, with more write processes, bigger files, and other types of OLTP activity added to the mix. It’s a recipe for disaster at scale.
What can we do improve bulk inserts into SQL Server?
The first thing a consultant will say is to get faster disks, or more of them. As suggested earlier, though, changing out your I/O subsystem might not be feasible due to budget or technical reasons. Next, they might suggest partitioning the table by thread. In addition to the Enterprise Edition requirement, which might be a non-starter, and the disruption of adding a new clustering key to the table, this might not make sense if the rest of your application benefits greatly from a different clustering/partitioning key.
One way that I’ve tackled this problem in the past is similar to the partitioning idea, except that you just create separate staging tables, and let each thread bulk insert into its own staging table. Another single background process will be responsible for moving the data from the staging tables to the destination. The following diagram represents how that would work; most importantly, none of the web servers are waiting on each other:

The process that goes through the staging tables and moves the data to the big table is represented by the gear icon. We’ll come back to that; for now, let’s focus on splitting up the work.
We start by creating four copies of the dumpster table (we don’t need the identity column, nor a view to hide it):
SELECT TOP 0 a,b,c,d,e,f,g,h,I,j INTO dbo.Dumpster<strong>Copy1</strong> FROM dbo.DumpsterTable;<br />SELECT TOP 0 a,b,c,d,e,f,g,h,I,j INTO dbo.Dumpster<strong>Copy2</strong> FROM dbo.DumpsterCopy1;<br />SELECT TOP 0 a,b,c,d,e,f,g,h,I,j INTO dbo.Dumpster<strong>Copy3</strong> FROM dbo.DumpsterCopy1;<br />SELECT TOP 0 a,b,c,d,e,f,g,h,I,j INTO dbo.Dumpster<strong>Copy4</strong> FROM dbo.DumpsterCopy1;
(If we want to optimize loading into these tables in a certain order, we can create a clustered index and use that order in the BULK INSERT command.)
Now, the stored procedure has to change slightly, in order to direct the insert to the proper table. You can do this in a number of ways:
- Using HOST_NAME(), assuming each copy of the app is on its own server
- APP_NAME() if each copy of the app can be modified to set that differently in its connection string
- Create a separate stored procedure per thread and have the app determine which one to call based on its host
- Add a parameter and change the stored procedure call in the app to dictate which thread it is
Since this example is using SQL Server Agent to simulate the real world, we’ll use the last approach, but the other approaches wouldn’t be much different.
ALTER PROCEDURE dbo.LoadDumpsterData<br /> @Thread varchar(11) = '1'<br />AS<br />BEGIN<br /> SET NOCOUNT ON;
DECLARE @TableName sysname = N'dbo.DumpsterCopy' + @Thread;
IF OBJECT_ID(@TableName) IS NOT NULL<br /> BEGIN<br /> DECLARE @sql nvarchar(max) = N'BULK INSERT ' + @TableName<br /> + N' FROM ''c:\temp\Dumpster.csv'' WITH <br /> (<br /> TABLOCK, <br /> ROWTERMINATOR = ''\n'',<br /> FIELDTERMINATOR = '',''<br /> );';
EXEC sys.sp_executesql @sql;<br /> END<br />END<br />GO
Then we change each job to this:
EXEC Dumpster.dbo.LoadDumpsterData @Thread = '1'; -- and 2 and 3 and 4<br />GO 5
Next, we need to create a second job that sequentially goes through and moves the data:
BEGIN TRANSACTION;<br />INSERT dbo.DumpsterTable(a,b,c,d,e,f,g,h,i,j) <br /> SELECT a,b,c,d,e,f,g,h,I,j <br /> FROM dbo.DumpsterCopy1 WITH (HOLDLOCK);<br />TRUNCATE TABLE dbo.DumpsterCopy1;<br />COMMIT TRANSACTION;<br />-- repeat for 2, 3, 4
Now the loading jobs averaged less than 45 seconds, and the one job that loaded into the main table took just over three minutes. That’s a huge win no matter how you look at it – we’ve shaved around two minutes off the entire process, and a very small portion of that work is forcing the application to wait.
Waits were much less severe during this window (it might look worse on first glance, but just look at the y-axis):

We can compare the most significant spikes between the two operations. With the initial approach (on the left below), we see very high PAGEIOLATCH_EX and also a lot of contention on writing to the log. On the right, most of the log contention has gone away, and we’ve whittled the page contention to almost nothing:

The CPU pattern was slightly different. We get some higher CPU at the beginning because of the huge increase in throughput, but then it settles down to a lower profile for the remainder of the operation (and you can see where the process stopped two minutes earlier than before, and we went back down to 20% average load):

The biggest win is not in any performance chart, it’s all that waiting time freed up from the web servers, the saving of roughly two minutes of clock time, and shifting all the locking contention on the main table. That contention still exists, it’s just different now.
Summary
You probably notice that, while we reduced concurrency and I/O issues by splitting out the initial load and lowered waits for the web servers, so far, we’ve merely shifted the hotspot. It is now in the background process, since it must read these tables potentially while the web servers are trying to bulk insert more data. In part 2, I’ll discuss how you can alleviate this using partition switching – even on Express Edition.
Next Steps
Read on for related tips and other resources:
- Minimally Logging Bulk Load Inserts into SQL Server
- Troubleshooting Common SQL Server Bulk Insert Errors
- Options to Improve SQL Server Bulk Load Performance
- Different Options for Importing Data into SQL Server
- Stay tuned for part 2!

Aaron Bertrand (@AaronBertrand) is a passionate technologist with industry experience dating back to Classic ASP and SQL Server 6.5. He also blogs at sqlblog.org.
- MSSQLTips Awards: Author of the Year – 2016, 2023 | Leadership (200+ tips) – 2022


