Problem
As a data professional, data engineer or Business Intelligence (BI) developer I would like to understand the logic behind autonomous data engineering solutions to get an idea about the ongoing advancements in the field of data engineering.
Solution
Let’s take a look at what Autonomous Data Engineering is and how this can be used in a SQL Server environment.
What is Autonomous Data Engineering
Autonomous data engineering is about building data engineering solutions by the use of automation and/or artificial intelligence that may require no or little human intervention afterwards.
It can also be defined as building self-managing data engineering workflows that require no or minimum manual intervention and have the capability to self-heal.
We can also say it is about designing a system that can extract, transform, load, manage and monitor data almost on its own.
Autonomous Data Engineering Capabilities and Attributes
Let’s review autonomous data engineering capabilities which is another way to understand what it means and what we can expect.
In terms of attributes, an autonomous data engineering solution can possess one or all of the following capabilities:
- Self-configuring – Configure itself without the need for any manual work by a data engineer
- Self-healing – Heal or fix itself in case of an issue or error provided
- Self-adjusting – A system can adjust itself based on new changes without requiring a manual change
- Self-managing – Capable of managing itself as when required without the need for manual work, but within the defined boundary of its expectation
Understanding the limitations
Despite these impressive capabilities we cannot expect an autonomous data engineering solution to have everything that we would expect from a system as we are not trying to achieve a zero-failure data engineering solution (system that never fails), but our aim is to build a system that can handle (most of the) failures (by itself) to the best of its capabilities.
Looking Back at Self-Healing ETL in 2018
Let me take you back to 2018 when an article specifically mentioned self-healing ETL (data extract, transform and load), inspired me to an extent that I myself thought how it might be possible (at that time).
This was the time of BI suite SSIS (SQL Server Integration Services), SSRS (SQL Server Reporting Services), SSAS (SQL Server Analysis Services) and on-premises SQL Server. This is now classed as legacy BI suite, but still as powerful as it was in the past, although it lacks the modern competitive BI features.
Let’s analyze the article in terms of autonomous data engineering solution as first visualized by the author, followed by my reflection, considering the tools and technologies of that time.
Data Science Problem and Self-Healing ETL (2018)
The data science problem was based on the fact that Data science requires data preparation. Data preparation requires data extraction, transformation and load either via ETL or ELT. Now the ETL developers or data engineers at that time ended up writing numerous workflows having the similar structure or requirements, but with a little difference. So, we would like to see SSIS (SQL Server Integration Services) from that time with the help of AI (artificial intelligence of the same era) to be able to generate multiple workflows of such nature based on a single template that it can adjust with the requirements.
SSIS with Data Quality and Format Suggestions
Now SSIS (SQL Server Integration Services) Packages can help us to map source and target columns provided naming and data types are same which requires the data engineers or ETL developer to do a lot of work in setting up matching target data structure for successful landing of data via these packages.
What if an SSIS package can directly build the target schema and objects (tables) based on source columns or source query into the target data store and then during the runs it can suggest potential inconsistencies and their solution.
SSIS with Self-Monitoring Capabilities
Another expectation from self-learning ETL is to see if SSIS Packages can learn from the processing (work) they do over the time that what is like an acceptable data flow and what might be an inconsistency plus what the ETL developers marked as potential issues and how they resolved that so that after sometime SSIS Packages should be able to start doing on their own by simply notifying the developers that the same issue happened and this was done to mitigate it successfully please check for any inaccuracy.
Auto-Scaling and Auto Pause and Resume ETL workflows
Additionally, we would like to see SSIS Packages to be able to auto-scale and pause and resume depending on the situation and requirements.
Analysis of self-learning ETL expectations in 2018
This is a reflection from an old article when SSIS was the leading ETL technology and rather than assuming new technologies built on new infrastructure (cloud) will change the way how ETL (data extract, transform and load works) works we expected the tool of the time to do autonomous things which is not a bad idea.
Data Integration Technology: On-premises Architecture to Cloud Architecture
To understand the logic behind an autonomous data engineering solution we need to understand the major breakthrough in data integration technology as we swiftly shifted from on-premises architecture to cloud architecture.
SSIS Packages and On-Premises Architecture
SSIS Packages work smoothly with on-premises architecture but have the capability to work with cloud architectures however, we must acknowledge the fact that SSIS (SQL Server Integration Services) are on-premises native first and then we can expand its capabilities to the next level which is cloud.
So, autonomous data engineering is best not described with SSIS in mind because of its architectural limitations although it is not impossible to build such a solution using SSIS.
Cloud PaaS Delivery Model
Things changed and Cloud native data integration technologies were introduced with the delivery cloud PaaS (Platform as a service) delivery mode much easier to manage and offering a partial autonomy by design in building data engineering solutions as compared to its older counterpart.
One such example is Azure Data Factory making it a better example for discussing autonomous data engineering in it.
SaaS stacks Delivery Model
However, things moved ahead and the delivery method SaaS (Software as a Service) was introduced taking it to the next level using the products like Microsoft Fabric, Databricks (SaaS-like), Snowflake etc. becoming best candidates for autonomous data engineering.
Logic Behind Autonomous Data Engineering
Let us now jump straight to the logic (designing principle) behind autonomous data engineering in the form of requirements as this tip assumes that the readers have basic data engineering knowledge and are aware of the tools and technologies regarding data engineering.
Scope and Specification (Business Requirements)
The first and foremost thing is to define the scope of your autonomous data engineering project (or research work) alongside the specification or business (or technical) requirements that you are targeting to meet via this solution.
Specification (requirements)
We want to build a proof-of-concept for an autonomous data engineering solution to understand its underlying logic.
Scope
This is a tricky part because this is where you will clarify what is being covered and what is beyond the scope of this work (not covered) but most importantly what do we mean by autonomous data engineering (our context).
Please set the scope carefully because the whole work revolves around the scope and specification.
The following examples help us to understand what might be the scope for an autonomous data engineering solution:
- Automated data pipelines getting created on the fly based on the source schema and data structure.
- Self-healing data pipelines to automatically recover from errors or inconsistencies with little or no human intervention.
- Data pipelines with automated quality checks and monitoring that can spot any quality issues with the data with little or no human intervention.
- Automated data pipelines with anomaly detection and auto-correction to spot anomalies (or inconsistencies) in a data flow and automatically make corrections.
- Self-optimizing data pipelines (ETL process) that is capable of optimization the source queries and transformation logic to keep the smooth flow of data in a speedy manner.
- Auto-scaling data pipelines that can handle sudden massive data flows which the ETL architecture was not initially designed to handle.
- An intelligent ETL system that constantly learns from the current data flows and suggest improvements and point out potential issues that may occur with time.
- Another way is to just define an autonomous data platform that require no manual effort for testing and deployment.
ETL Architecture and Resource Specific Planning
We also need to be specific in terms of what will be the resources in use such as tools, technologies and processes to design such solution.
Analysing Sources
At this point, please perform a quick analysis of what type of sources your autonomous data engineering solution will be processing as this helps you to determine next steps.
Let us see some examples of valid ETL system sources:
- Databases (SQL, Oracle, MongoDB etc.)
- APIs
- CSV Files
- Streaming data
Analysing Data Processing Type
The data processing methodology may fall into the following categories:
- Batch processing (incremental loads or one-time loads from operational databases)
- Real-time processing (to process real-time data as it happens)
- Hybrid (a mix of both batch and real-time processing)
Analysing Target Storage Type
Next you have to understand what is the ultimate target storage type for the autonomous data engineering solution as it may vary based on the purpose and requirements.
The typical target storage type can be one or all of the following:
- Database
- Data Warehouse
- Data Lake
- Lakehouse
Analysing Scale and Tools
Additionally, you have to analyse the volume of data to be processed and the tools and technologies to be used for this automated solution.
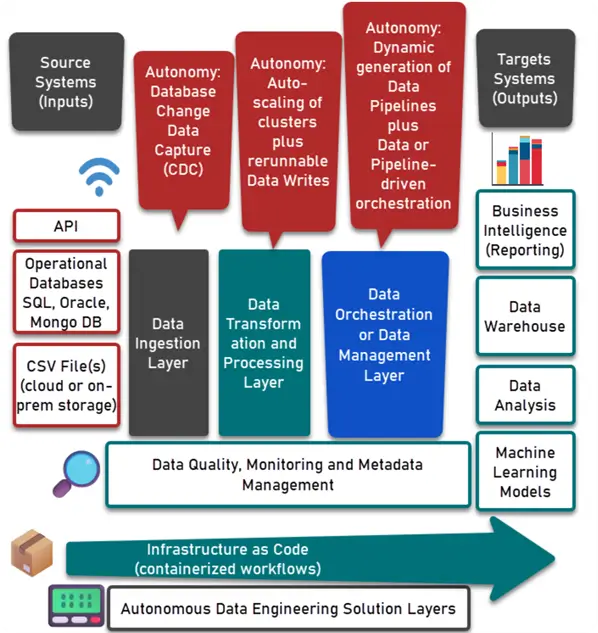
Understanding Data Platform Layers and other aspects for Autonomous Data Engineering
There are three layers for a data platform to be considered when designing autonomous data engineering solution.
Data Copy (Ingestion) Layer
This is the layer that talks about data ingestion responsible for the first copy of data from the source system.
With batch processing you can use a number of available tools including Azure Data Factory pipelines, Apache Airflow or custom python scripts.
For steaming data Databricks structured streaming analytics, Apache Kafka, Microsoft Event Hubs or Fabric Streaming Analytics (which let you plug streaming data directly into Power BI or OneLake) can be used.
For automation event-driven triggers can be used where certain events trigger data ingestion process and for the database CDC (Change Data Capture) can be helpful which means any change in the data triggers data ingestion.
The scheduled triggers that run around the clock may also be part of the automation if they are meta-data driven which they receive data from a database such as a table which can be successfully managed dynamically.
Data Transformation and Processing Layer
This layer determines your autonomous data platform’s processing and transformation logic.
Mind you it is all about processing and transformation logic so you have a limited number of tooling options as compared to data ingestion layer.
For example, if you require intensive SQL transformations to meet your business or technical requirements then dbt (data build tool) is one of the best candidates to use which can help you in running massive transformations within your SQL repository whether it be a database, data warehouse or SQL hybrid (lakehouse). Please remember that this is the typical case of ELT (Extract Load and Transform) since T is your transformation layer.
On the contrary if an industry standard batch or even streaming data processing is your requirements then Databricks can do the job for you.
Now to understand what type of autonomy is applicable in this layer and it can be anything that can help us to automate or assist in our data processing and transformation objectives such as auto-scaling of clusters based on data volume or dynamic partitioning of data to speed up transformation or even rerunnable writes (insertion or transformation of same data to get to the final state without introducing duplicates no matter how many times it runs) .
Data Orchestration or Data Management Layer
Another layer is data orchestration or data management layer and a tool such as Apache Airflow or any competitive cloud-native framework can make a difference here since this layer deals with how the data workflows are going to be handled or managed.
Here the automation can be more likely generation of data pipelines dynamically and then its data-driven orchestration as well. It may also include other factors such as auto pause of the resources when not in use or alerting the operations time about unexpected data orchestration.
Data Quality, Monitoring and Metadata Management
Data quality, its continuous monitoring and the way you manage your metadata are all interlinked and must be handled with a lot of care.
Let us start with metadata management which means we need to preserve the structure of the data in a safe place it can be an online repository so that it can managed because metadata is a key component for the quality of data that we expect from constant monitoring.
There are a number of tools like Great Expectations (GX), Microsoft Purview (Data Quality feature) available to achieve such purposes and one potential use case of automation here simply means automatic adjustment of data pipelines base on meta-data change detected by the monitoring system. Another aspect would be automated data platform governance.
Overall Infrastructure and Publishing Strategy
Finally, we have to look at the overall infrastructure and data platform publishing or deployment strategy. This in itself is a broad topic but to simplify we can say our data platform infrastructure can also be an infrastructure as code and tools like Terraform can help and/or we can use light weight data platform containers or containerized workflows and deployments can be fully modernized to achieve Continuous Integration and Continuous Deployment (CI/CD).
Automating SSIS ETL Packages Example
Let us take a very simple SSIS Project to understand a very basic form of autonomous data engineering.
A data engineer builds an SSIS Project for a data loading activity that runs via scheduled SQL job. Whenever the data load fails due to any issue all the project is terminated abnormally after the failure. The data engineer has to manually check from the database where it failed what data was sent and what was left and then he triggers the package manually to either redo all the load or resume from the failure. One day he decides to automate the process to save his time and effort. So, he takes a note of his manual steps turns them into objects such as stored procedures to exactly perform the same work that he does when the package fails. That’s it next time when the job fails his (a simple form of) autonomous data engineering kicks in and does the job.
Enabling Anomaly Detection in Power BI Example
Finally, a quick example of assisted analytics or partially autonomous data engineering solution might be when you publish your Power BI report to Power BI Premium workspace and enable anomaly detection (on specific visuals) then it starts automatically detecting anomalies in your data and showing you trends and patterns so you did not originally design anomaly detection or predictive analytics for your report but the tool is providing this self-service AI feature.
Congratulations! You have successfully learned the logic behind autonomous data engineering solutions.
Next Steps
- Now that you know the logic behind autonomous data engineering, can you please try to design a model of your own even if it is just on paper
- Can you please recommend what tools and autonomy would you use to build autonomous data engineering solution across the three layers of data engineering platform if your data source consists of ten CSV files only
- Please go through the Create Custom SSIS Execution Log – Part 1 and try if you can automate any part of the process such as creating of staging table or event login table or even both
- Please try to regenerate the problem mentioned in Create Custom SSIS Execution Log – Part 2 tip and check for yourself what part of the process you can automate and how
- Please have a look at the Data Wrangling in SQL by Imputing Missing Values using Derived Values tip and try to automate the steps by writing a stored procedure that does the job for you when a table is passed to it

Haroon Ashraf’s deep interest in logic and reasoning at an early age of his academic career paved his path to become a data professional.
He holds BSc (Gold Medal) and MSc Degrees in Computer Science and also received the OPF merit award.
His programming career began in 2006 working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Business Intelligence and Database Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration.
He has recently earned “Knowledge Management and Big Data in Business” certificate from The Polytechnic University of Hong Kong.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2018-2020


