Problem
As a database or business intelligence developer I would like to learn the data wrangling steps in SQL especially the methods used to impute missing values without having to learn any specialized languages such as Python or R.
Solution
The solution is to get hands on experience of imputing missing values using the native SQL language, but following the same basis used in Data Science for data munging that utilize specialized languages like Python.
About Imputing Missing Values
It is very important to get some basic know-how of data wrangling and the term “Imputing Missing Values” in a Dataset from a data wrangling process.
Data wrangling
Data wrangling is simply a way to refine a Dataset by converting it from raw data to another form for data analytics purposes by Data Analyst for better decision making.
To get a better understanding about data wrangling (data exploration, data preparation, data cleaning, validating, enriching, automation, etc.) please refer to the following tutorial: Learn basics of Data Wrangling in SQL to handle Invalid Values.
What is Imputing Missing Values?
Imputing missing values means replacing missing values with some meaningful data in a Dataset as part of data wrangling, which can be very time-consuming.
What are missing values?
A missing value is any value in a Dataset (such as a SQL database table) which has not been supplied or has been left uninitialized.
SQL Example of missing value
Null values represent missing values in a SQL table which can pose serious problems for carrying out complex data analysis so these missing values must be handled by using one of the methods applied in data wrangling.
Imputing Missing Values using Mean and Median Methods
In this walkthrough we are going to learn the following data wrangling approaches to impute (replace) missing values:
- Using Drop Attribute Method
- Using Mean Method
Prerequisites
This tip assumes that the readers are well familiar with T-SQL and database concepts and the following environment is setup:
- SQL Server local/remote instance is installed
- Database development and management tool like SQL Server Management Studio (SSMS) or Azure Data Studio is readily available to setup the database and run T-SQL scripts
Reference Tip
It is highly recommended to go through the previously discussed methods used in data wrangling by reading the following tip: Learn basics of Data Wrangling in SQL to handle Invalid Values.
Setup Sample Dataset (Database) WatchesDWR2
The first thing is to setup a sample Dataset (SQL database) called WatchesDWR2, about watches, by running the following script against the master database to create the data structures:
-- Create a new database called 'WatchesDWR2'
-- Connect to the 'master' database to run this snippet
USE master
GO
-- Create the new database if it does not exist already
IF NOT EXISTS (
SELECT [name]
FROM sys.databases
WHERE [name] = N'WatchesDWR2'
)
CREATE DATABASE WatchesDWR2
GO
-- Switch to the WatchesDWR2 database (created locally)
USE WatchesDWR2
-- Creating a watch table
CREATE TABLE [dbo].[Watch]
(
[WatchId] [int] IDENTITY(1,1) NOT NULL,
[Color] [varchar](20) NULL,
[Case Width] INT NULL,
[Case Depth] INT NULL,
[Price] [decimal](10, 2) NULL,
CONSTRAINT [PK_WatchType] PRIMARY KEY CLUSTERED
(
[WatchId] ASC
)
)
-- Insert rows into table 'Watch' in schema '[dbo]'
INSERT INTO [dbo].[Watch]
( -- Columns to insert data into
Color,[Case Width],[Case Depth], Price
)
VALUES
(
'Black', 49, 20, 200.00
),
(
'Blue', 45, 18, 150.00
),
(
NULL, 50, 15, NULL
),
(
NULL, 55, 15, 170.50
),
(
NULL, NULL, NULL, NULL
),
(
NULL, 52, 20, 300
)
Dataset Check
Please have a quick look at the recently created sample database which is used as a Dataset for data wrangling by typing and executing the following T-SQL script against the WatchesDWR2 database:
-- View Watch table SELECT w.WatchId, w.Color, w.[Case Width], w.[Case Depth], w.Price FROM [dbo].[Watch] w GO
The output is as follows:

Please note that this output is generated by Azure Data Studio. You can use any other compliant database development and management tool such as SQL Server Management Studio (SSMS) to write and run your SQL scripts.
Data Wrangling by using Drop Attribute Method
The “Drop Attribute” data wrangling algorithm is used in one of the following use cases:
- There are many missing values (NULLs) of a column, but the columns itself is not of interest from analysis point of view
- There may be no missing value of a column, but it is excluded from the analysis we are preparing the Dataset for
- There may be very few missing values of column, but dropping the field (column) is better than replacing those values
So, in other words, this is the data wrangling approach in which the Data Scientist \ Data Wrangler decides to detach (remove) an attribute from the Dataset (such as a SQL table as a data source) on the basis of its rare or non-use for the upcoming data analysis.
For example, if we are preparing the Dataset for analyzing case width and case depth of different watches sold to the customers recorded in the Dataset then Color column does not carry any weight to proceed further to the next stages.
Considering the current Watch t table, the following two strong reasons can be used to remove this column:
- It (Color) is not integral part of the analysis which requires case width and case depth of the watches
- It has a lot of NULLs which may be very costly (in terms of effort) to impute (replace) them with meaningful data
As a result of the above reasons, we decide to drop this attribute (column) by using data wrangling drop attribute approach.
This method is (if done in SQL) applied by the help of the following script (executed against the sample database):
-- Drop '[Color]' from table '[Watch]' in schema '[dbo]' using Drop Attribute Data Wrangling Method
ALTER TABLE [dbo].[Watch]
DROP COLUMN [Color]
GO
Now check the refined Dataset (table):
-- View Watch Table (Dataset) after applying Drop Attribute Data Wrangling Method SELECT w.WatchId, w.[Case Width], w.[Case Depth], w.Price FROM [dbo].[Watch] w GO
The result set is as follows:

We have refined the Dataset by dropping the Color column as it was not needed for analysis and cost (in terms of effort) of imputing (replacing) its missing values (Nulls) was far more than detaching it from the Dataset straight away.
Data Wrangling by Imputing Missing Values using Mean Method
Let us now discuss another form of data wrangling by imputing (replacing) missing values with the help of Mean Method to improve the data quality. This method requires us to calculate statistical mean value of the series of the dataset to impute (replace) missing values.
The Mean value is defined as follows: SUM of elements of the series/Number of elements of the series
In other words, this is average of a series of elements to be used as a replacement for missing value(s).
However, please remember that this is applicable to numerical series only (having numbers) and it is only desirable when very small percentage of data is missing.

Let us apply the Mean value method to impute the missing value in Case Width column by running the following script:
--Data Wrangling Mean value method to impute the missing value in Case Width column SELECT SUM(w.[Case Width]) AS SumOfValues, COUNT(*) NumberOfValues, SUM(w.[Case Width])/COUNT(*) as Mean FROM dbo.Watch w WHERE w.[Case Width] is NOT NULL --Imputing the missing value in Case Width Column with Mean: 50 UPDATE dbo.Watch SET [Case Width]=50 -- Mean Value (Average) WHERE [Case Width] IS NULL
The output is as follows:

Let us take a look at the table now:
-- View Watch Table (Dataset) after applying Mean Value Data Wrangling Method for Case Width SELECT w.WatchId, w.[Case Width], w.[Case Depth], w.Price FROM [dbo].[Watch] w GO
The updated Watch table (Dataset) is shown below:

The Case Width column of the Watch table (Dataset) has been successfully populated using the data wrangling Mean method by replacing Nulls with computed mean value which is 50.
Let us refine the Case Depth column as well by applying the same Mean Method for this column.
Please write and run the following script:
--Data Wrangling Mean value method to impute the missing value in Case Depth column SELECT SUM(w.[Case Depth]) AS SumOfValues, COUNT(*) NumberOfValues, SUM(w.[Case Depth])/COUNT(*) as Mean FROM dbo.Watch w WHERE w.[Case Depth] is NOT NULL --Imputing the missing value in Case Depth Column with Mean: 50 UPDATE dbo.Watch SET [Case Depth]=17 -- Mean Value (Average) WHERE [Case Depth] IS NULL
The output is as follows:
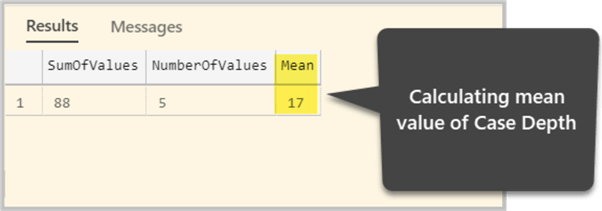
Let us view the table now:
-- View Watch Table (Dataset) after applying Mean Value Data Wrangling Method for Case Depth SELECT w.WatchId, w.[Case Width], w.[Case Depth], w.Price FROM [dbo].[Watch] w GO
The results are shown below:

We can clearly see that the Case Depth column’s missing value has been successfully replaced with the mean value and table does not have the same number of Nulls that it had before.
Alternative way to calculate Mean
Please remember since Mean is just like Average, so we can also use the SQL Average function AVG() to calculate mean value as a portion of your validation rules in the real-world.
For example, if we have to calculate the mean value of Price column then we can simply type the following script:
--Estimating Mean Value of Price Column using AVG functionSELECT SUM(W.Price) AS SUM_PRICE, COUNT(W.PRICE) AS COUNT_PRICE,AVG(w.PRICE) as Mean_Price_Using_AVG FROM dbo.Watch w
The output can be seen below:

Next Steps
- Please reset the sample database (Dataset) and apply data wrangling mean value method by using Average function for both Case Width and Case Depth Columns and see if you get the same results or not.
- Try imputing (replacing) missing values in the Price Column by using Mean Method.
- Please setup the sample database OfficeSuppliesSampleV2_Data referenced in this tip and try data wrangling techniques after replacing columns Quantity and Price with Nulls for any two orders (rows) and try imputing the missing values using data wrangling mean value method mentioned in this tip.
- Please create a sample database OfficeSuppliesSample by referring to this tip and replace any 3 of the rows of both Stock and Price column with NULLs in the Product table to apply data wrangling in the light of this tip.

Haroon Ashraf’s deep interest in logic and reasoning at an early age of his academic career paved his path to become a data professional.
He holds BSc (Gold Medal) and MSc Degrees in Computer Science and also received the OPF merit award.
His programming career began in 2006 working on his first data venture to migrate and rewrite a public sector database driven examination system from IBM AS400 (DB2) to SQL Server 2000 using VB 6.0 and Classic ASP along with developing reports and archiving many years of data.
His work and interest revolves around Business Intelligence and Database Centric Architectures and his expertise include database and reports design, development, testing, implementation and migration.
He has recently earned “Knowledge Management and Big Data in Business” certificate from The Polytechnic University of Hong Kong.
- MSSQLTips Awards: Trendsetter (25+ tips) – 2020 | Author of the Year Contender – 2018-2020


Currently SQL server studio , Thanks for these wonderful tutorials.